 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssociating Spatially-Consistent Grouping with Text-supervised Semantic Segmentation
Apr 03, 2023
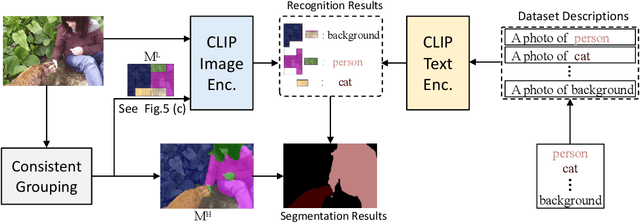
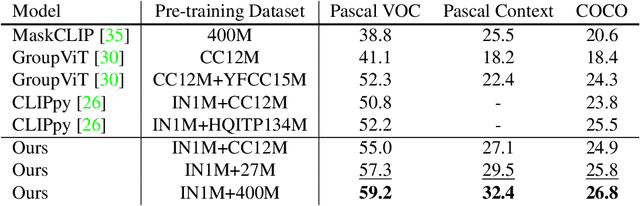
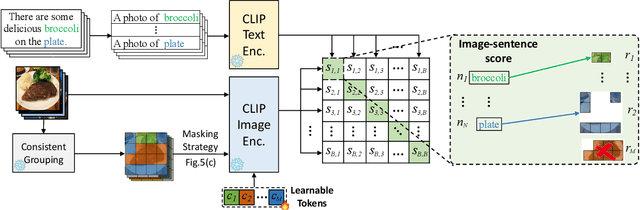
In this work, we investigate performing semantic segmentation solely through the training on image-sentence pairs. Due to the lack of dense annotations, existing text-supervised methods can only learn to group an image into semantic regions via pixel-insensitive feedback. As a result, their grouped results are coarse and often contain small spurious regions, limiting the upper-bound performance of segmentation. On the other hand, we observe that grouped results from self-supervised models are more semantically consistent and break the bottleneck of existing methods. Motivated by this, we introduce associate self-supervised spatially-consistent grouping with text-supervised semantic segmentation. Considering the part-like grouped results, we further adapt a text-supervised model from image-level to region-level recognition with two core designs. First, we encourage fine-grained alignment with a one-way noun-to-region contrastive loss, which reduces the mismatched noun-region pairs. Second, we adopt a contextually aware masking strategy to enable simultaneous recognition of all grouped regions. Coupled with spatially-consistent grouping and region-adapted recognition, our method achieves 59.2% mIoU and 32.4% mIoU on Pascal VOC and Pascal Context benchmarks, significantly surpassing the state-of-the-art methods.
Image Inpainting by End-to-End Cascaded Refinement with Mask Awareness
Apr 28, 2021
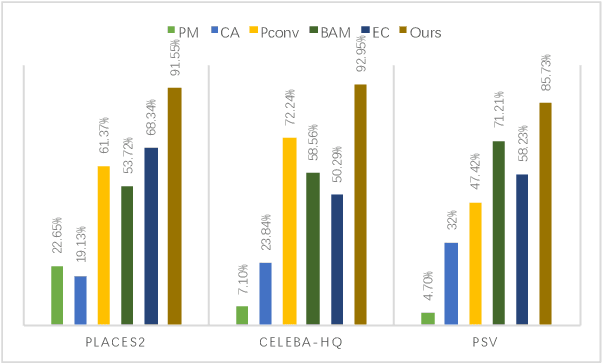


Inpainting arbitrary missing regions is challenging because learning valid features for various masked regions is nontrivial. Though U-shaped encoder-decoder frameworks have been witnessed to be successful, most of them share a common drawback of mask unawareness in feature extraction because all convolution windows (or regions), including those with various shapes of missing pixels, are treated equally and filtered with fixed learned kernels. To this end, we propose our novel mask-aware inpainting solution. Firstly, a Mask-Aware Dynamic Filtering (MADF) module is designed to effectively learn multi-scale features for missing regions in the encoding phase. Specifically, filters for each convolution window are generated from features of the corresponding region of the mask. The second fold of mask awareness is achieved by adopting Point-wise Normalization (PN) in our decoding phase, considering that statistical natures of features at masked points differentiate from those of unmasked points. The proposed PN can tackle this issue by dynamically assigning point-wise scaling factor and bias. Lastly, our model is designed to be an end-to-end cascaded refinement one. Supervision information such as reconstruction loss, perceptual loss and total variation loss is incrementally leveraged to boost the inpainting results from coarse to fine. Effectiveness of the proposed framework is validated both quantitatively and qualitatively via extensive experiments on three public datasets including Places2, CelebA and Paris StreetView.