 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-Inspired Robotic Houbara: From Development to Field Deployment for Behavioral Studies
Oct 06, 2025Biomimetic intelligence and robotics are transforming field ecology by enabling lifelike robotic surrogates that interact naturally with animals under real world conditions. Studying avian behavior in the wild remains challenging due to the need for highly realistic morphology, durable outdoor operation, and intelligent perception that can adapt to uncontrolled environments. We present a next generation bio inspired robotic platform that replicates the morphology and visual appearance of the female Houbara bustard to support controlled ethological studies and conservation oriented field research. The system introduces a fully digitally replicable fabrication workflow that combines high resolution structured light 3D scanning, parametric CAD modelling, articulated 3D printing, and photorealistic UV textured vinyl finishing to achieve anatomically accurate and durable robotic surrogates. A six wheeled rocker bogie chassis ensures stable mobility on sand and irregular terrain, while an embedded NVIDIA Jetson module enables real time RGB and thermal perception, lightweight YOLO based detection, and an autonomous visual servoing loop that aligns the robot's head toward detected targets without human intervention. A lightweight thermal visible fusion module enhances perception in low light conditions. Field trials in desert aviaries demonstrated reliable real time operation at 15 to 22 FPS with latency under 100 ms and confirmed that the platform elicits natural recognition and interactive responses from live Houbara bustards under harsh outdoor conditions. This integrated framework advances biomimetic field robotics by uniting reproducible digital fabrication, embodied visual intelligence, and ecological validation, providing a transferable blueprint for animal robot interaction research, conservation robotics, and public engagement.
FishDet-M: A Unified Large-Scale Benchmark for Robust Fish Detection and CLIP-Guided Model Selection in Diverse Aquatic Visual Domains
Jul 23, 2025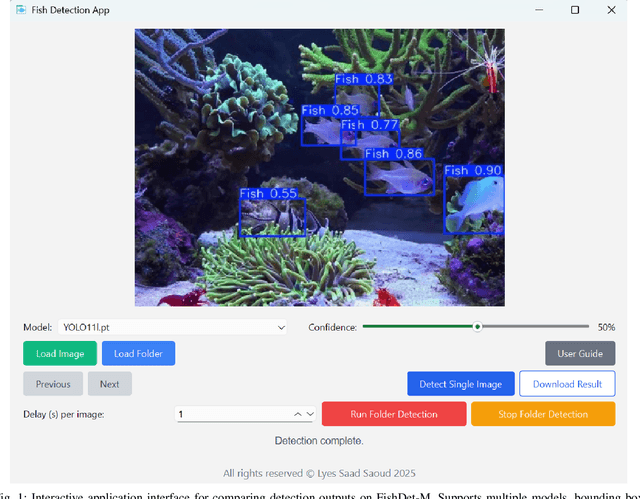
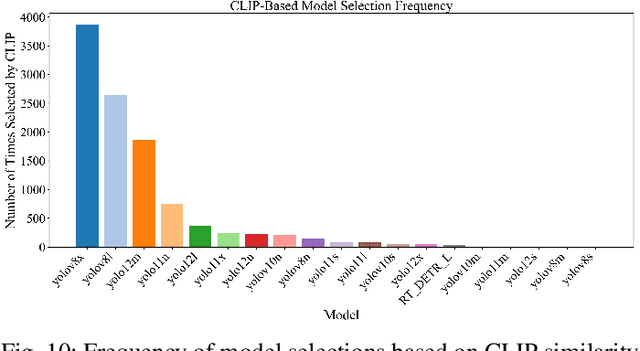
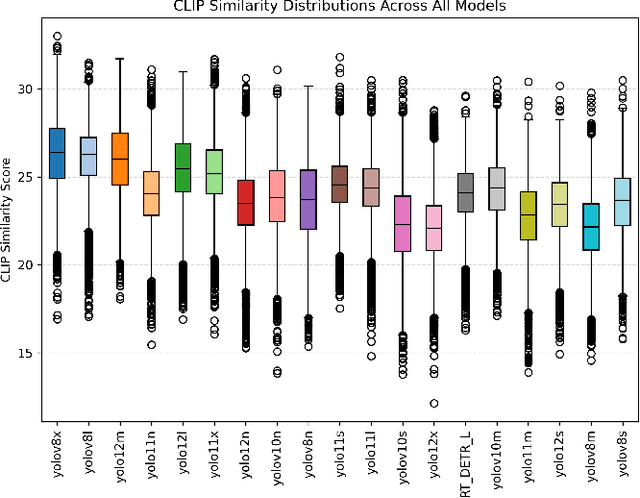
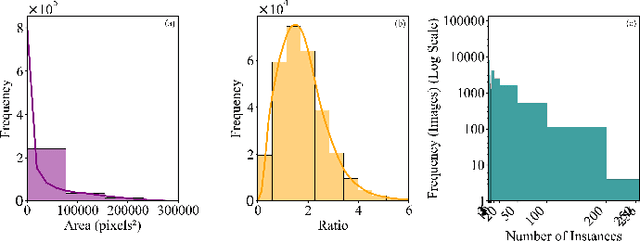
Accurate fish detection in underwater imagery is essential for ecological monitoring, aquaculture automation, and robotic perception. However, practical deployment remains limited by fragmented datasets, heterogeneous imaging conditions, and inconsistent evaluation protocols. To address these gaps, we present \textit{FishDet-M}, the largest unified benchmark for fish detection, comprising 13 publicly available datasets spanning diverse aquatic environments including marine, brackish, occluded, and aquarium scenes. All data are harmonized using COCO-style annotations with both bounding boxes and segmentation masks, enabling consistent and scalable cross-domain evaluation. We systematically benchmark 28 contemporary object detection models, covering the YOLOv8 to YOLOv12 series, R-CNN based detectors, and DETR based models. Evaluations are conducted using standard metrics including mAP, mAP@50, and mAP@75, along with scale-specific analyses (AP$_S$, AP$_M$, AP$_L$) and inference profiling in terms of latency and parameter count. The results highlight the varying detection performance across models trained on FishDet-M, as well as the trade-off between accuracy and efficiency across models of different architectures. To support adaptive deployment, we introduce a CLIP-based model selection framework that leverages vision-language alignment to dynamically identify the most semantically appropriate detector for each input image. This zero-shot selection strategy achieves high performance without requiring ensemble computation, offering a scalable solution for real-time applications. FishDet-M establishes a standardized and reproducible platform for evaluating object detection in complex aquatic scenes. All datasets, pretrained models, and evaluation tools are publicly available to facilitate future research in underwater computer vision and intelligent marine systems.
MARS: Multi-Scale Adaptive Robotics Vision for Underwater Object Detection and Domain Generalization
Dec 23, 2023Underwater robotic vision encounters significant challenges, necessitating advanced solutions to enhance performance and adaptability. This paper presents MARS (Multi-Scale Adaptive Robotics Vision), a novel approach to underwater object detection tailored for diverse underwater scenarios. MARS integrates Residual Attention YOLOv3 with Domain-Adaptive Multi-Scale Attention (DAMSA) to enhance detection accuracy and adapt to different domains. During training, DAMSA introduces domain class-based attention, enabling the model to emphasize domain-specific features. Our comprehensive evaluation across various underwater datasets demonstrates MARS's performance. On the original dataset, MARS achieves a mean Average Precision (mAP) of 58.57\%, showcasing its proficiency in detecting critical underwater objects like echinus, starfish, holothurian, scallop, and waterweeds. This capability holds promise for applications in marine robotics, marine biology research, and environmental monitoring. Furthermore, MARS excels at mitigating domain shifts. On the augmented dataset, which incorporates all enhancements (+Domain +Residual+Channel Attention+Multi-Scale Attention), MARS achieves an mAP of 36.16\%. This result underscores its robustness and adaptability in recognizing objects and performing well across a range of underwater conditions. The source code for MARS is publicly available on GitHub at https://github.com/LyesSaadSaoud/MARS-Object-Detection/
ADOD: Adaptive Domain-Aware Object Detection with Residual Attention for Underwater Environments
Dec 11, 2023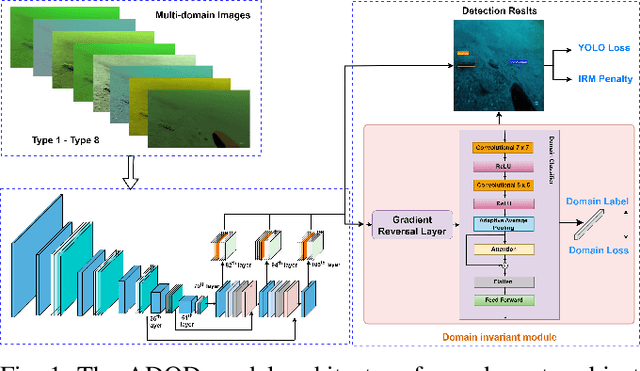
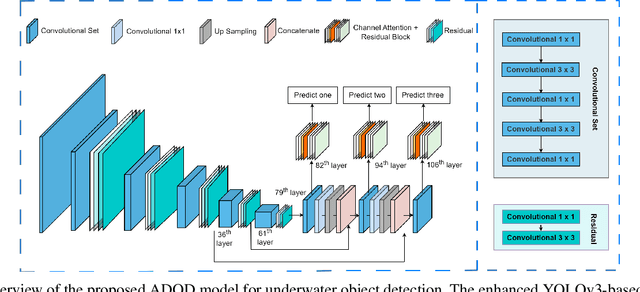
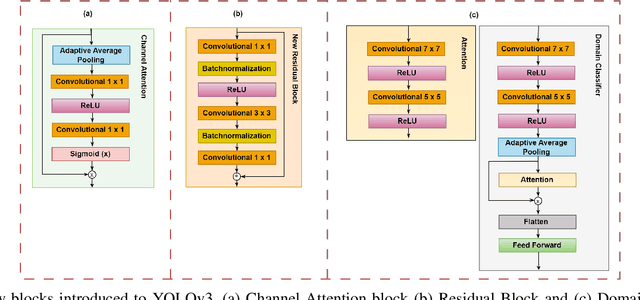
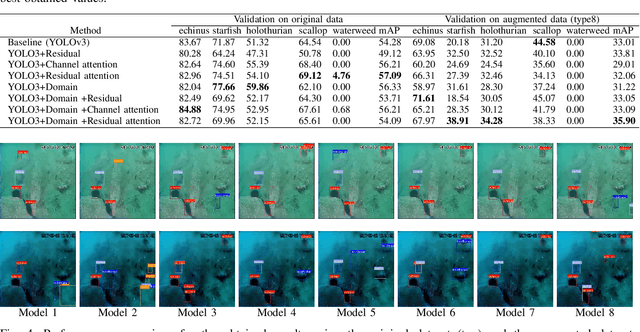
This research presents ADOD, a novel approach to address domain generalization in underwater object detection. Our method enhances the model's ability to generalize across diverse and unseen domains, ensuring robustness in various underwater environments. The first key contribution is Residual Attention YOLOv3, a novel variant of the YOLOv3 framework empowered by residual attention modules. These modules enable the model to focus on informative features while suppressing background noise, leading to improved detection accuracy and adaptability to different domains. The second contribution is the attention-based domain classification module, vital during training. This module helps the model identify domain-specific information, facilitating the learning of domain-invariant features. Consequently, ADOD can generalize effectively to underwater environments with distinct visual characteristics. Extensive experiments on diverse underwater datasets demonstrate ADOD's superior performance compared to state-of-the-art domain generalization methods, particularly in challenging scenarios. The proposed model achieves exceptional detection performance in both seen and unseen domains, showcasing its effectiveness in handling domain shifts in underwater object detection tasks. ADOD represents a significant advancement in adaptive object detection, providing a promising solution for real-world applications in underwater environments. With the prevalence of domain shifts in such settings, the model's strong generalization ability becomes a valuable asset for practical underwater surveillance and marine research endeavors.
Marine$\mathcal{X}$: Design and Implementation of Unmanned Surface Vessel for Vision Guided Navigation
Nov 28, 2023
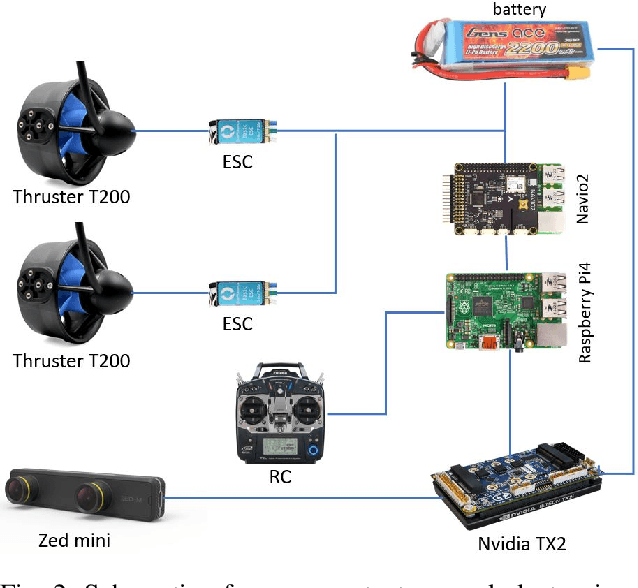
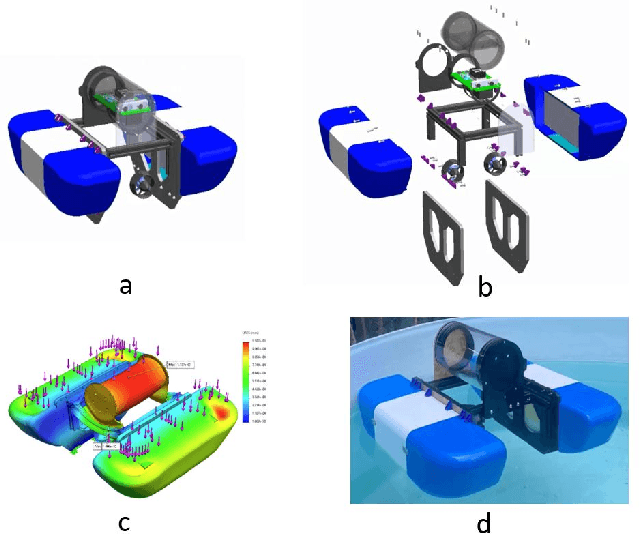
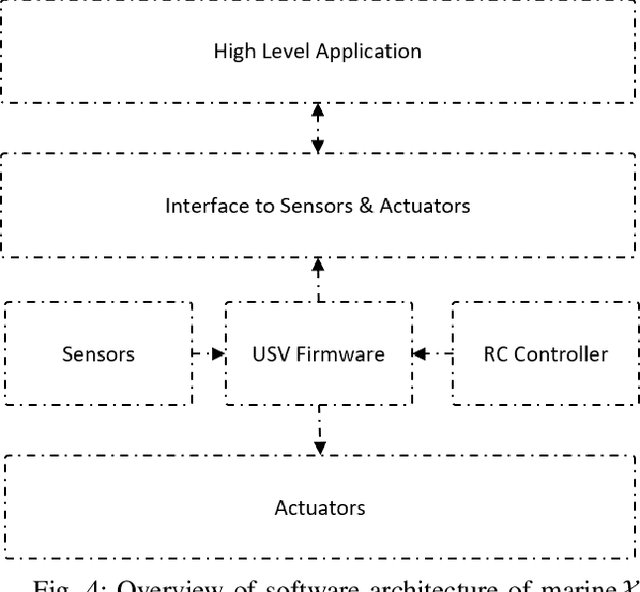
Marine robots, particularly Unmanned Surface Vessels (USVs), have gained considerable attention for their diverse applications in maritime tasks, including search and rescue, environmental monitoring, and maritime security. This paper presents the design and implementation of a USV named marine$\mathcal{X}$. The hardware components of marine$\mathcal{X}$ are meticulously developed to ensure robustness, efficiency, and adaptability to varying environmental conditions. Furthermore, the integration of a vision-based object tracking algorithm empowers marine$\mathcal{X}$ to autonomously track and monitor specific objects on the water surface. The control system utilizes PID control, enabling precise navigation of marine$\mathcal{X}$ while maintaining a desired course and distance to the target object. To assess the performance of marine$\mathcal{X}$, comprehensive testing is conducted, encompassing simulation, trials in the marine pool, and real-world tests in the open sea. The successful outcomes of these tests demonstrate the USV's capabilities in achieving real-time object tracking, showcasing its potential for various applications in maritime operations.
* accepted in ICAR
Robust Collision Detection for Robots with Variable Stiffness Actuation by Using MAD-CNN: Modularized-Attention-Dilated Convolutional Neural Network
Oct 04, 2023Ensuring safety is paramount in the field of collaborative robotics to mitigate the risks of human injury and environmental damage. Apart from collision avoidance, it is crucial for robots to rapidly detect and respond to unexpected collisions. While several learning-based collision detection methods have been introduced as alternatives to purely model-based detection techniques, there is currently a lack of such methods designed for collaborative robots equipped with variable stiffness actuators. Moreover, there is potential for further enhancing the network's robustness and improving the efficiency of data training. In this paper, we propose a new network, the Modularized Attention-Dilated Convolutional Neural Network (MAD-CNN), for collision detection in robots equipped with variable stiffness actuators. Our model incorporates a dual inductive bias mechanism and an attention module to enhance data efficiency and improve robustness. In particular, MAD-CNN is trained using only a four-minute collision dataset focusing on the highest level of joint stiffness. Despite limited training data, MAD-CNN robustly detects all collisions with minimal detection delay across various stiffness conditions. Moreover, it exhibits a higher level of collision sensitivity, which is beneficial for effectively handling false positives, which is a common issue in learning-based methods. Experimental results demonstrate that the proposed MAD-CNN model outperforms existing state-of-the-art models in terms of collision sensitivity and robustness.
TempoNet: Empowering long-term Knee Joint Angle Prediction with Dynamic Temporal Attention in Exoskeleton Control
Oct 03, 2023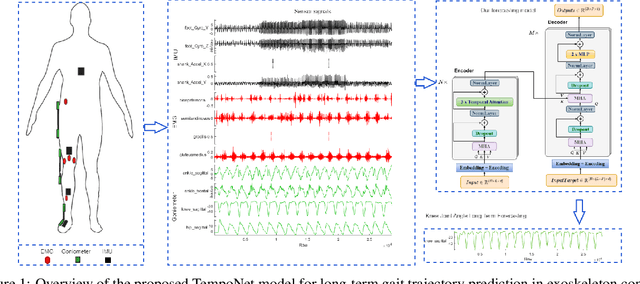
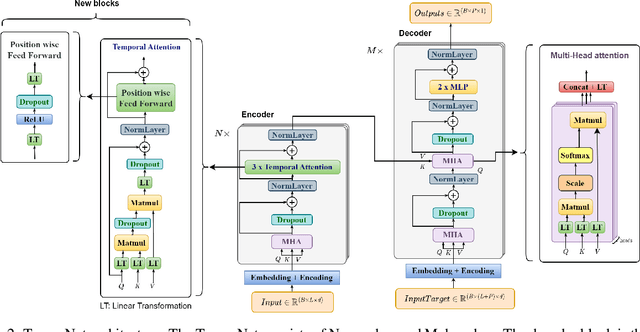
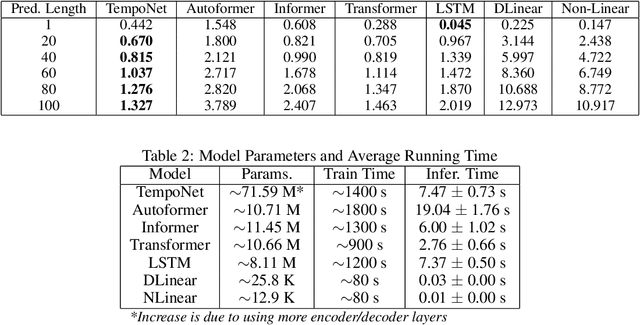
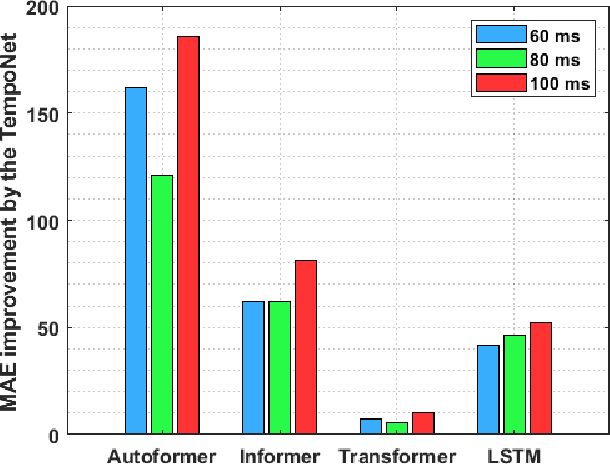
In the realm of exoskeleton control, achieving precise control poses challenges due to the mechanical delay of exoskeletons. To address this, incorporating future gait trajectories as feed-forward input has been proposed. However, existing deep learning models for gait prediction mainly focus on short-term predictions, leaving the long-term performance of these models relatively unexplored. In this study, we present TempoNet, a novel model specifically designed for precise knee joint angle prediction. By harnessing dynamic temporal attention within the Transformer-based architecture, TempoNet surpasses existing models in forecasting knee joint angles over extended time horizons. Notably, our model achieves a remarkable reduction of 10\% to 185\% in Mean Absolute Error (MAE) for 100 ms ahead forecasting compared to other transformer-based models, demonstrating its effectiveness. Furthermore, TempoNet exhibits further reliability and superiority over the baseline Transformer model, outperforming it by 14\% in MAE for the 200 ms prediction horizon. These findings highlight the efficacy of TempoNet in accurately predicting knee joint angles and emphasize the importance of incorporating dynamic temporal attention. TempoNet's capability to enhance knee joint angle prediction accuracy opens up possibilities for precise control, improved rehabilitation outcomes, advanced sports performance analysis, and deeper insights into biomechanical research. Code implementation for the TempoNet model can be found in the GitHub repository: https://github.com/LyesSaadSaoud/TempoNet.
Autonomous Underwater Robotic System for Aquaculture Applications
Aug 26, 2023Aquaculture is a thriving food-producing sector producing over half of the global fish consumption. However, these aquafarms pose significant challenges such as biofouling, vegetation, and holes within their net pens and have a profound effect on the efficiency and sustainability of fish production. Currently, divers and/or remotely operated vehicles are deployed for inspecting and maintaining aquafarms; this approach is expensive and requires highly skilled human operators. This work aims to develop a robotic-based automatic net defect detection system for aquaculture net pens oriented to on- ROV processing and real-time detection of different aqua-net defects such as biofouling, vegetation, net holes, and plastic. The proposed system integrates both deep learning-based methods for aqua-net defect detection and feedback control law for the vehicle movement around the aqua-net to obtain a clear sequence of net images and inspect the status of the net via performing the inspection tasks. This work contributes to the area of aquaculture inspection, marine robotics, and deep learning aiming to reduce cost, improve quality, and ease of operation.
FocalGatedNet: A Novel Deep Learning Model for Accurate Knee Joint Angle Prediction
Jun 12, 2023


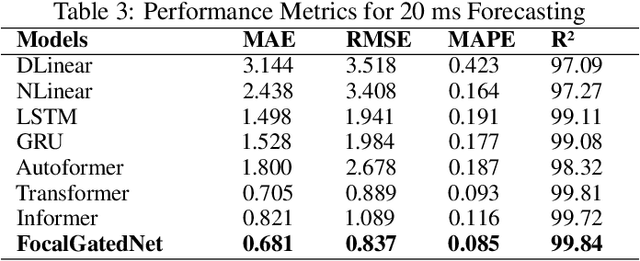
Predicting knee joint angles accurately is critical for biomechanical analysis and rehabilitation. This paper introduces a new deep learning model called FocalGatedNet that incorporates Dynamic Contextual Focus (DCF) Attention and Gated Linear Units (GLU) to enhance feature dependencies and interactions. Our proposed model is evaluated on a large-scale dataset and compared to existing models such as Transformer, Autoformer, Informer, NLinear, DLinear, and LSTM in multi-step gait trajectory prediction. Our results demonstrate that FocalGatedNet outperforms other state-of-the-art models for long-term prediction lengths (60 ms, 80 ms, and 100 ms), achieving an average improvement of 13.66% in MAE and 8.13% in RMSE compared to the second-best performing model (Transformer). Furthermore, our model has a lower computational load than most equivalent deep learning models. These results highlight the effectiveness of our proposed model for knee joint angle prediction and the importance of our modifications for this specific application.
Cascaded Deep Hybrid Models for Multistep Household Energy Consumption Forecasting
Jul 06, 2022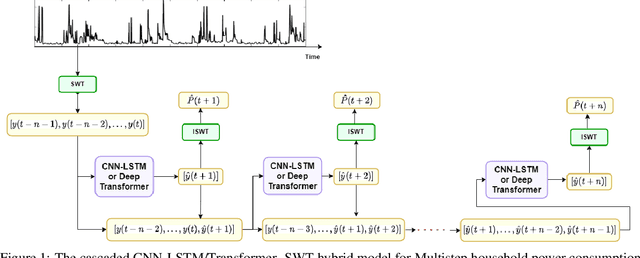

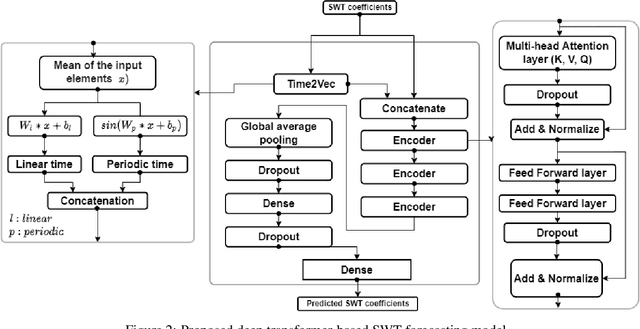

Sustainability requires increased energy efficiency with minimal waste. The future power systems should thus provide high levels of flexibility iin controling energy consumption. Precise projections of future energy demand/load at the aggregate and on the individual site levels are of great importance for decision makers and professionals in the energy industry. Forecasting energy loads has become more advantageous for energy providers and customers, allowing them to establish an efficient production strategy to satisfy demand. This study introduces two hybrid cascaded models for forecasting multistep household power consumption in different resolutions. The first model integrates Stationary Wavelet Transform (SWT), as an efficient signal preprocessing technique, with Convolutional Neural Networks and Long Short Term Memory (LSTM). The second hybrid model combines SWT with a self-attention based neural network architecture named transformer. The major constraint of using time-frequency analysis methods such as SWT in multistep energy forecasting problems is that they require sequential signals, making signal reconstruction problematic in multistep forecasting applications.The cascaded models can efficiently address this problem through using the recursive outputs. Experimental results show that the proposed hybrid models achieve superior prediction performance compared to the existing multistep power consumption prediction methods. The results will pave the way for more accurate and reliable forecasting of household power consumption.