 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFTBNN: Rethinking Non-linearity for 1-bit CNNs and Going Beyond
Oct 29, 2020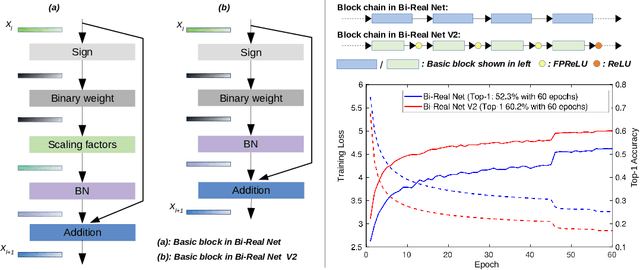


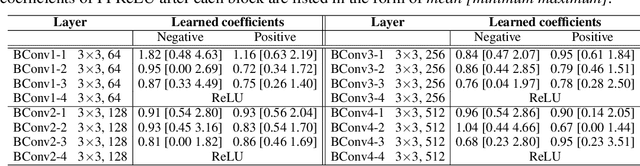
Binary neural networks (BNNs), where both weights and activations are binarized into 1 bit, have been widely studied in recent years due to its great benefit of highly accelerated computation and substantially reduced memory footprint that appeal to the development of resource constrained devices. In contrast to previous methods tending to reduce the quantization error for training BNN structures, we argue that the binarized convolution process owns an increasing linearity towards the target of minimizing such error, which in turn hampers BNN's discriminative ability. In this paper, we re-investigate and tune proper non-linear modules to fix that contradiction, leading to a strong baseline which achieves state-of-the-art performance on the large-scale ImageNet dataset in terms of accuracy and training efficiency. To go further, we find that the proposed BNN model still has much potential to be compressed by making a better use of the efficient binary operations, without losing accuracy. In addition, the limited capacity of the BNN model can also be increased with the help of group execution. Based on these insights, we are able to improve the baseline with an additional 4~5% top-1 accuracy gain even with less computational cost. Our code will be made public at https://github.com/zhuogege1943/ftbnn.
Dynamic Group Convolution for Accelerating Convolutional Neural Networks
Jul 10, 2020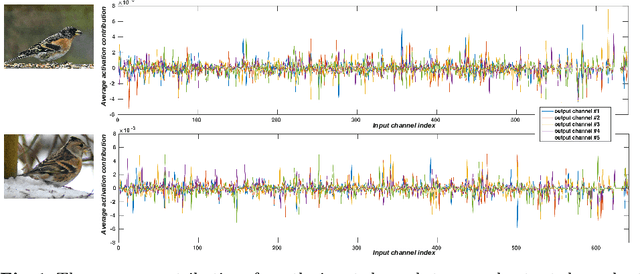
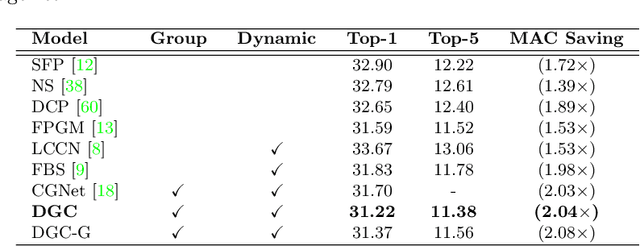
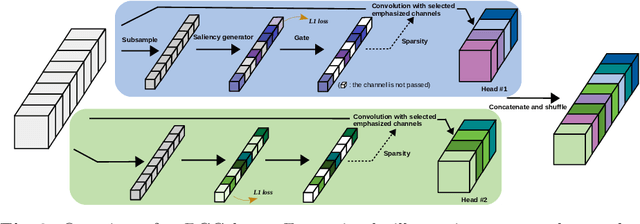
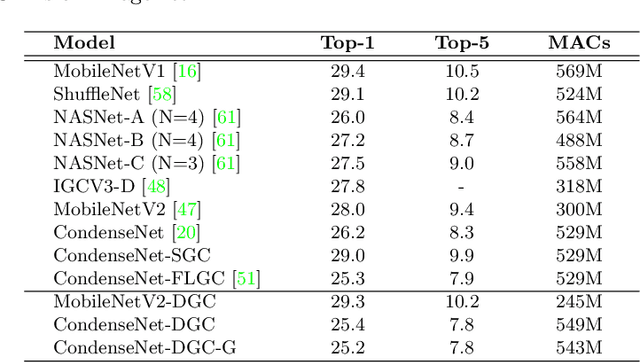
Replacing normal convolutions with group convolutions can significantly increase the computational efficiency of modern deep convolutional networks, which has been widely adopted in compact network architecture designs. However, existing group convolutions undermine the original network structures by cutting off some connections permanently resulting in significant accuracy degradation. In this paper, we propose dynamic group convolution (DGC) that adaptively selects which part of input channels to be connected within each group for individual samples on the fly. Specifically, we equip each group with a small feature selector to automatically select the most important input channels conditioned on the input images. Multiple groups can adaptively capture abundant and complementary visual/semantic features for each input image. The DGC preserves the original network structure and has similar computational efficiency as the conventional group convolution simultaneously. Extensive experiments on multiple image classification benchmarks including CIFAR-10, CIFAR-100 and ImageNet demonstrate its superiority over the existing group convolution techniques and dynamic execution methods. The code is available at https://github.com/zhuogege1943/dgc.
JGR-P2O: Joint Graph Reasoning based Pixel-to-Offset Prediction Network for 3D Hand Pose Estimation from a Single Depth Image
Jul 10, 2020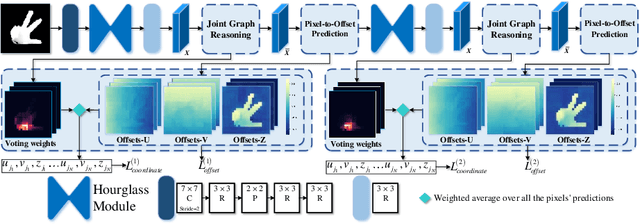
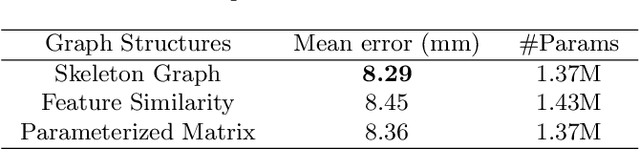
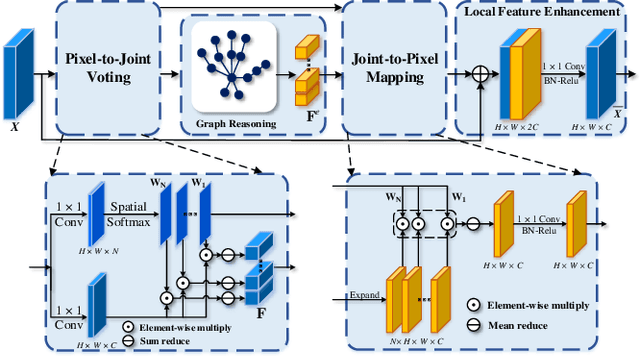

State-of-the-art single depth image-based 3D hand pose estimation methods are based on dense predictions, including voxel-to-voxel predictions, point-to-point regression, and pixel-wise estimations. Despite the good performance, those methods have a few issues in nature, such as the poor trade-off between accuracy and efficiency, and plain feature representation learning with local convolutions. In this paper, a novel pixel-wise prediction-based method is proposed to address the above issues. The key ideas are two-fold: a) explicitly modeling the dependencies among joints and the relations between the pixels and the joints for better local feature representation learning; b) unifying the dense pixel-wise offset predictions and direct joint regression for end-to-end training. Specifically, we first propose a graph convolutional network (GCN) based joint graph reasoning module to model the complex dependencies among joints and augment the representation capability of each pixel. Then we densely estimate all pixels' offsets to joints in both image plane and depth space and calculate the joints' positions by a weighted average over all pixels' predictions, totally discarding the complex postprocessing operations. The proposed model is implemented with an efficient 2D fully convolutional network (FCN) backbone and has only about 1.4M parameters. Extensive experiments on multiple 3D hand pose estimation benchmarks demonstrate that the proposed method achieves new state-of-the-art accuracy while running very efficiently with around a speed of 110fps on a single NVIDIA 1080Ti GPU.
EHSOD: CAM-Guided End-to-end Hybrid-Supervised Object Detection with Cascade Refinement
Feb 18, 2020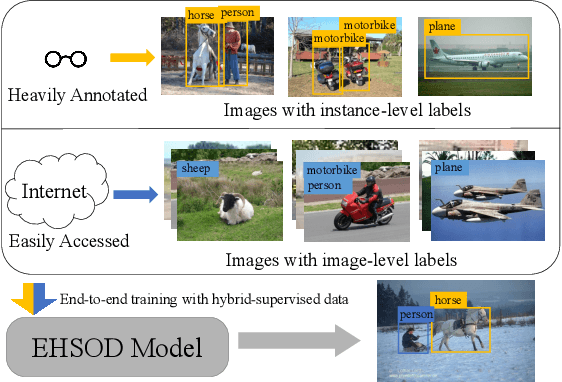
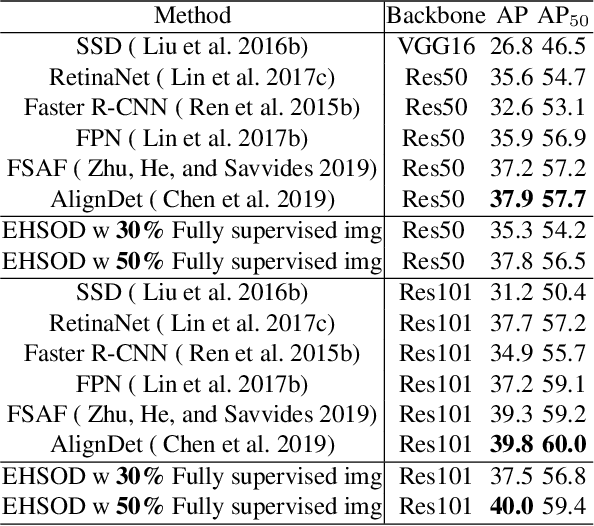
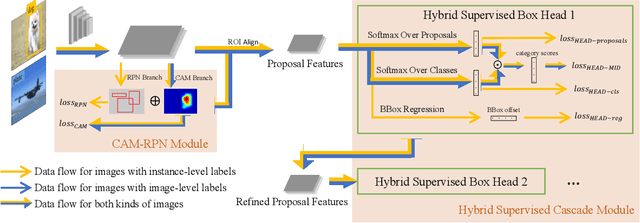
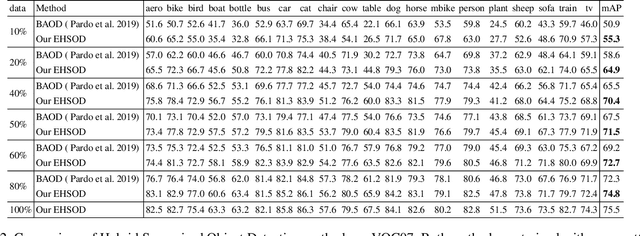
Object detectors trained on fully-annotated data currently yield state of the art performance but require expensive manual annotations. On the other hand, weakly-supervised detectors have much lower performance and cannot be used reliably in a realistic setting. In this paper, we study the hybrid-supervised object detection problem, aiming to train a high quality detector with only a limited amount of fullyannotated data and fully exploiting cheap data with imagelevel labels. State of the art methods typically propose an iterative approach, alternating between generating pseudo-labels and updating a detector. This paradigm requires careful manual hyper-parameter tuning for mining good pseudo labels at each round and is quite time-consuming. To address these issues, we present EHSOD, an end-to-end hybrid-supervised object detection system which can be trained in one shot on both fully and weakly-annotated data. Specifically, based on a two-stage detector, we proposed two modules to fully utilize the information from both kinds of labels: 1) CAMRPN module aims at finding foreground proposals guided by a class activation heat-map; 2) hybrid-supervised cascade module further refines the bounding-box position and classification with the help of an auxiliary head compatible with image-level data. Extensive experiments demonstrate the effectiveness of the proposed method and it achieves comparable results on multiple object detection benchmarks with only 30% fully-annotated data, e.g. 37.5% mAP on COCO. We will release the code and the trained models.
Universal-RCNN: Universal Object Detector via Transferable Graph R-CNN
Feb 18, 2020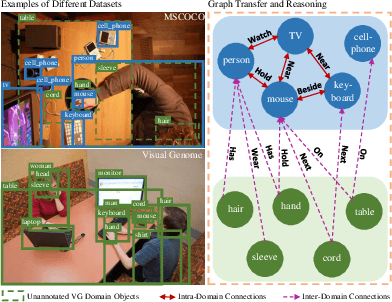
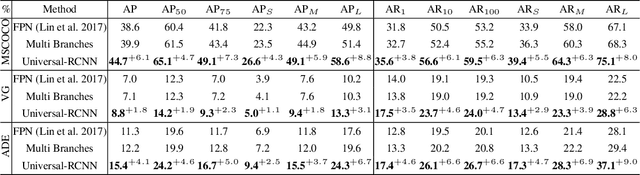

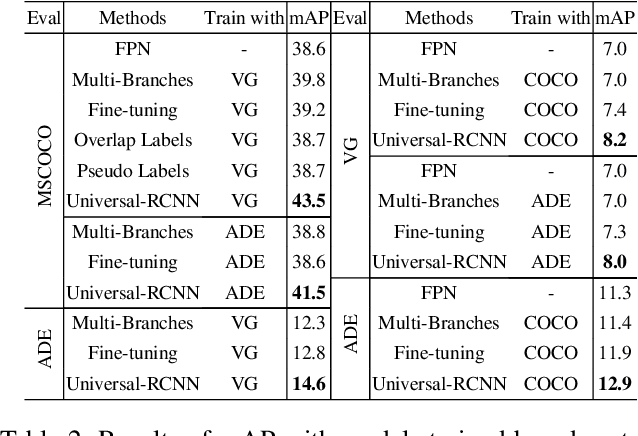
The dominant object detection approaches treat each dataset separately and fit towards a specific domain, which cannot adapt to other domains without extensive retraining. In this paper, we address the problem of designing a universal object detection model that exploits diverse category granularity from multiple domains and predict all kinds of categories in one system. Existing works treat this problem by integrating multiple detection branches upon one shared backbone network. However, this paradigm overlooks the crucial semantic correlations between multiple domains, such as categories hierarchy, visual similarity, and linguistic relationship. To address these drawbacks, we present a novel universal object detector called Universal-RCNN that incorporates graph transfer learning for propagating relevant semantic information across multiple datasets to reach semantic coherency. Specifically, we first generate a global semantic pool by integrating all high-level semantic representation of all the categories. Then an Intra-Domain Reasoning Module learns and propagates the sparse graph representation within one dataset guided by a spatial-aware GCN. Finally, an InterDomain Transfer Module is proposed to exploit diverse transfer dependencies across all domains and enhance the regional feature representation by attending and transferring semantic contexts globally. Extensive experiments demonstrate that the proposed method significantly outperforms multiple-branch models and achieves the state-of-the-art results on multiple object detection benchmarks (mAP: 49.1% on COCO).