 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreq-DP Net: A Dual-Branch Network for Fence Removal using Dual-Pixel and Fourier Priors
Feb 15, 2026Removing fence occlusions from single images is a challenging task that degrades visual quality and limits downstream computer vision applications. Existing methods often fail on static scenes or require motion cues from multiple frames. To overcome these limitations, we introduce the first framework to leverage dual-pixel (DP) sensors for this problem. We propose Freq-DP Net, a novel dual-branch network that fuses two complementary priors: a geometric prior from defocus disparity, modeled using an explicit cost volume, and a structural prior of the fence's global pattern, learned via Fast Fourier Convolution (FFC). An attention mechanism intelligently merges these cues for highly accurate fence segmentation. To validate our approach, we build and release a diverse benchmark with different fence varieties. Experiments demonstrate that our method significantly outperforms strong general-purpose baselines, establishing a new state-of-the-art for single-image, DP-based fence removal.
AbracADDbra: Touch-Guided Object Addition by Decoupling Placement and Editing Subtasks
Feb 15, 2026Instruction-based object addition is often hindered by the ambiguity of text-only prompts or the tedious nature of mask-based inputs. To address this usability gap, we introduce AbracADDbra, a user-friendly framework that leverages intuitive touch priors to spatially ground succinct instructions for precise placement. Our efficient, decoupled architecture uses a vision-language transformer for touch-guided placement, followed by a diffusion model that jointly generates the object and an instance mask for high-fidelity blending. To facilitate standardized evaluation, we contribute the Touch2Add benchmark for this interactive task. Our extensive evaluations, where our placement model significantly outperforms both random placement and general-purpose VLM baselines, confirm the framework's ability to produce high-fidelity edits. Furthermore, our analysis reveals a strong correlation between initial placement accuracy and final edit quality, validating our decoupled approach. This work thus paves the way for more accessible and efficient creative tools.
Insert In Style: A Zero-Shot Generative Framework for Harmonious Cross-Domain Object Composition
Nov 19, 2025Reference-based object composition methods fail when inserting real-world objects into stylized domains. This under-explored problem is currently split between practical "blenders" that lack generative fidelity and "generators" that require impractical, per-subject online finetuning. In this work, we introduce Insert In Style, the first zero-shot generative framework that is both practical and high-fidelity. Our core contribution is a unified framework with two key innovations: (i) a novel multi-stage training protocol that disentangles representations for identity, style, and composition, and (ii) a specialized masked-attention architecture that surgically enforces this disentanglement during generation. This approach prevents the concept interference common in general-purpose, unified-attention models. Our framework is trained on a new 100k sample dataset, curated from a novel data pipeline. This pipeline couples large-scale generation with a rigorous, two-stage filtering process to ensure both high-fidelity semantic identity and style coherence. Unlike prior work, our model is truly zero-shot and requires no text prompts. We also introduce a new public benchmark for stylized composition. We demonstrate state-of-the-art performance, significantly outperforming existing methods on both identity and style metrics, a result strongly corroborated by user studies.
DiFuse-Net: RGB and Dual-Pixel Depth Estimation using Window Bi-directional Parallax Attention and Cross-modal Transfer Learning
Jun 17, 2025Depth estimation is crucial for intelligent systems, enabling applications from autonomous navigation to augmented reality. While traditional stereo and active depth sensors have limitations in cost, power, and robustness, dual-pixel (DP) technology, ubiquitous in modern cameras, offers a compelling alternative. This paper introduces DiFuse-Net, a novel modality decoupled network design for disentangled RGB and DP based depth estimation. DiFuse-Net features a window bi-directional parallax attention mechanism (WBiPAM) specifically designed to capture the subtle DP disparity cues unique to smartphone cameras with small aperture. A separate encoder extracts contextual information from the RGB image, and these features are fused to enhance depth prediction. We also propose a Cross-modal Transfer Learning (CmTL) mechanism to utilize large-scale RGB-D datasets in the literature to cope with the limitations of obtaining large-scale RGB-DP-D dataset. Our evaluation and comparison of the proposed method demonstrates its superiority over the DP and stereo-based baseline methods. Additionally, we contribute a new, high-quality, real-world RGB-DP-D training dataset, named Dual-Camera Dual-Pixel (DCDP) dataset, created using our novel symmetric stereo camera hardware setup, stereo calibration and rectification protocol, and AI stereo disparity estimation method.
MIPI 2023 Challenge on RGB+ToF Depth Completion: Methods and Results
Apr 27, 2023



Depth completion from RGB images and sparse Time-of-Flight (ToF) measurements is an important problem in computer vision and robotics. While traditional methods for depth completion have relied on stereo vision or structured light techniques, recent advances in deep learning have enabled more accurate and efficient completion of depth maps from RGB images and sparse ToF measurements. To evaluate the performance of different depth completion methods, we organized an RGB+sparse ToF depth completion competition. The competition aimed to encourage research in this area by providing a standardized dataset and evaluation metrics to compare the accuracy of different approaches. In this report, we present the results of the competition and analyze the strengths and weaknesses of the top-performing methods. We also discuss the implications of our findings for future research in RGB+sparse ToF depth completion. We hope that this competition and report will help to advance the state-of-the-art in this important area of research. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2023.
AcED: Accurate and Edge-consistent Monocular Depth Estimation
Jun 16, 2020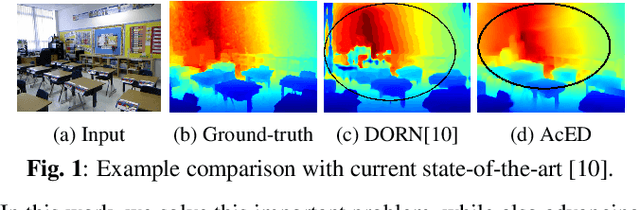
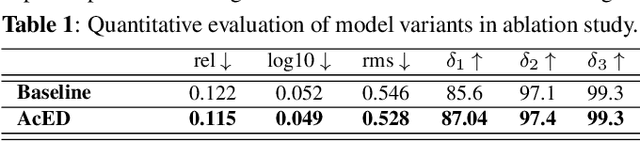

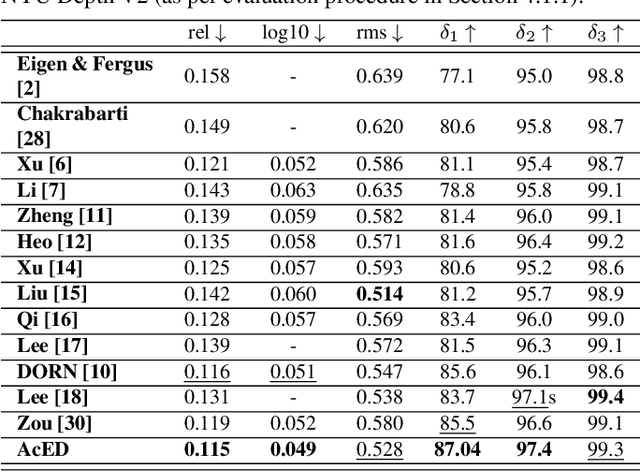
Single image depth estimation is a challenging problem. The current state-of-the-art method formulates the problem as that of ordinal regression. However, the formulation is not fully differentiable and depth maps are not generated in an end-to-end fashion. The method uses a na\"ive threshold strategy to determine per-pixel depth labels, which results in significant discretization errors. For the first time, we formulate a fully differentiable ordinal regression and train the network in end-to-end fashion. This enables us to include boundary and smoothness constraints in the optimization function, leading to smooth and edge-consistent depth maps. A novel per-pixel confidence map computation for depth refinement is also proposed. Extensive evaluation of the proposed model on challenging benchmarks reveals its superiority over recent state-of-the-art methods, both quantitatively and qualitatively. Additionally, we demonstrate practical utility of the proposed method for single camera bokeh solution using in-house dataset of challenging real-life images.
DISCO: Depth Inference from Stereo using Context
May 31, 2019
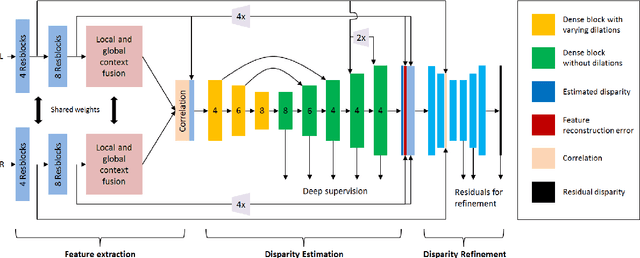
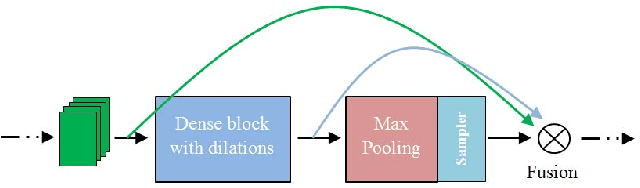

Recent deep learning based approaches have outperformed classical stereo matching methods. However, current deep learning based end-to-end stereo matching methods adopt a generic encoder-decoder style network with skip connections. To limit computational requirement, many networks perform excessive down sampling, which results in significant loss of useful low-level information. Additionally, many network designs do not exploit the rich multi-scale contextual information. In this work, we address these aforementioned problems by carefully designing the network architecture to preserve required spatial information throughout the network, while at the same time achieve large effective receptive field to extract multiscale contextual information. For the first time, we create a synthetic disparity dataset reflecting real life images captured using a smartphone; this enables us to obtain state-of-the-art results on common real life images. The proposed model DISCO is pre-trained on the synthetic Scene Flow dataset and evaluated on popular benchmarks and our in-house dataset of challenging real life images. The proposed model outperforms existing state-of-the-art methods in terms of quality as well as quantitative metrics.
CANDY: Conditional Adversarial Networks based Fully End-to-End System for Single Image Haze Removal
May 02, 2018


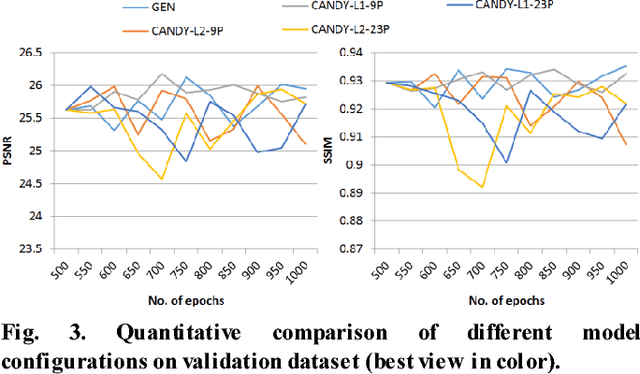
Single image haze removal is a very challenging and ill-posed problem. The existing haze removal methods in literature, including the recently introduced deep learning methods, model the problem of haze removal as that of estimating intermediate parameters, viz., scene transmission map and atmospheric light. These are used to compute the haze-free image from the hazy input image. Such an approach only focuses on accurate estimation of intermediate parameters, while the aesthetic quality of the haze-free image is unaccounted for in the optimization framework. Thus, errors in the estimation of intermediate parameters often lead to generation of inferior quality haze-free images. In this paper, we present CANDY (Conditional Adversarial Networks based Dehazing of hazY images), a fully end-to-end model which directly generates a clean haze-free image from a hazy input image. CANDY also incorporates the visual quality of haze-free image into the optimization function; thus, generating a superior quality haze-free image. To the best of our knowledge, this is the first work in literature to propose a fully end-to-end model for single image haze removal. Also, this is the first work to explore the newly introduced concept of generative adversarial networks for the problem of single image haze removal. The proposed model CANDY was trained on a synthetically created haze image dataset, while evaluation was performed on challenging synthetic as well as real haze image datasets. The extensive evaluation and comparison results of CANDY reveal that it significantly outperforms existing state-of-the-art haze removal methods in literature, both quantitatively as well as qualitatively.
Why my photos look sideways or upside down? Detecting Canonical Orientation of Images using Convolutional Neural Networks
Dec 04, 2017
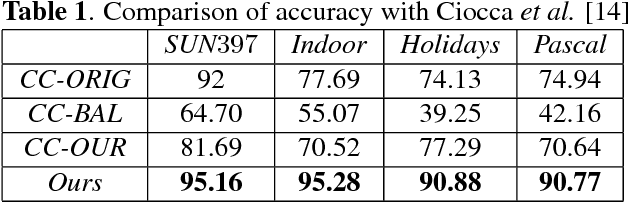
Image orientation detection requires high-level scene understanding. Humans use object recognition and contextual scene information to correctly orient images. In literature, the problem of image orientation detection is mostly confronted by using low-level vision features, while some approaches incorporate few easily detectable semantic cues to gain minor improvements. The vast amount of semantic content in images makes orientation detection challenging, and therefore there is a large semantic gap between existing methods and human behavior. Also, existing methods in literature report highly discrepant detection rates, which is mainly due to large differences in datasets and limited variety of test images used for evaluation. In this work, for the first time, we leverage the power of deep learning and adapt pre-trained convolutional neural networks using largest training dataset to-date for the image orientation detection task. An extensive evaluation of our model on different public datasets shows that it remarkably generalizes to correctly orient a large set of unconstrained images; it also significantly outperforms the state-of-the-art and achieves accuracy very close to that of humans.