 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to segment clustered amoeboid cells from brightfield microscopy via multi-task learning with adaptive weight selection
May 19, 2020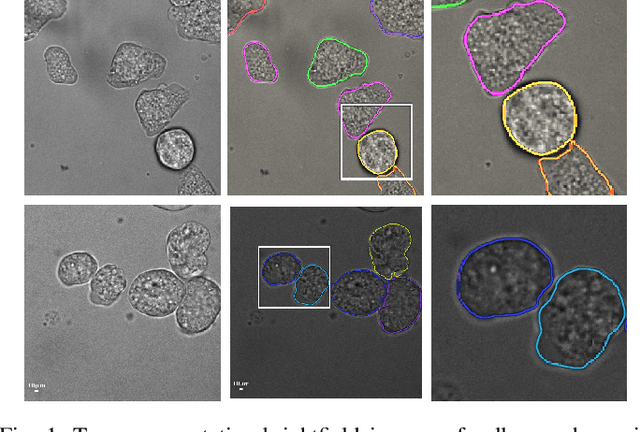
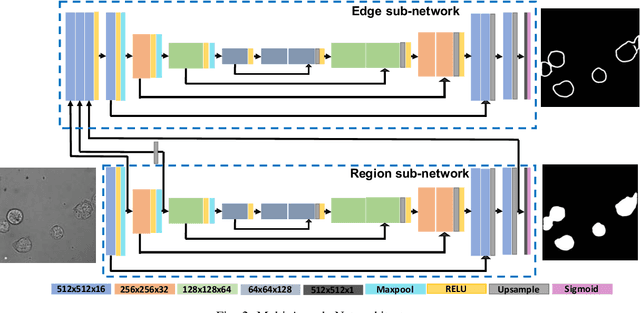
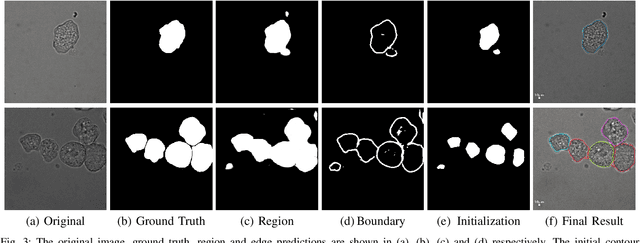

Detecting and segmenting individual cells from microscopy images is critical to various life science applications. Traditional cell segmentation tools are often ill-suited for applications in brightfield microscopy due to poor contrast and intensity heterogeneity, and only a small subset are applicable to segment cells in a cluster. In this regard, we introduce a novel supervised technique for cell segmentation in a multi-task learning paradigm. A combination of a multi-task loss, based on the region and cell boundary detection, is employed for an improved prediction efficiency of the network. The learning problem is posed in a novel min-max framework which enables adaptive estimation of the hyper-parameters in an automatic fashion. The region and cell boundary predictions are combined via morphological operations and active contour model to segment individual cells. The proposed methodology is particularly suited to segment touching cells from brightfield microscopy images without manual interventions. Quantitatively, we observe an overall Dice score of 0.93 on the validation set, which is an improvement of over 15.9% on a recent unsupervised method, and outperforms the popular supervised U-net algorithm by at least $5.8\%$ on average.
DISCO: Depth Inference from Stereo using Context
May 31, 2019
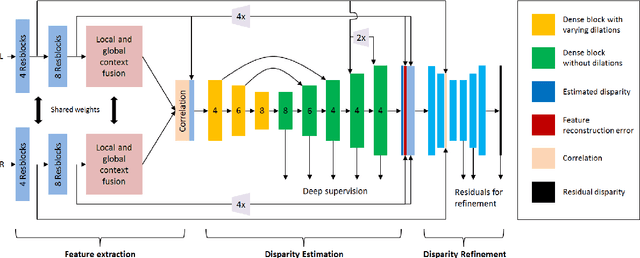
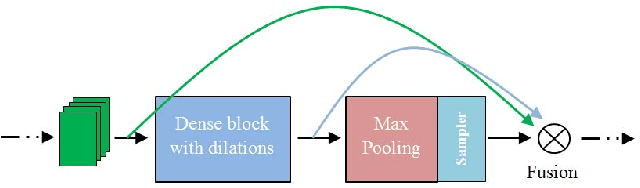

Recent deep learning based approaches have outperformed classical stereo matching methods. However, current deep learning based end-to-end stereo matching methods adopt a generic encoder-decoder style network with skip connections. To limit computational requirement, many networks perform excessive down sampling, which results in significant loss of useful low-level information. Additionally, many network designs do not exploit the rich multi-scale contextual information. In this work, we address these aforementioned problems by carefully designing the network architecture to preserve required spatial information throughout the network, while at the same time achieve large effective receptive field to extract multiscale contextual information. For the first time, we create a synthetic disparity dataset reflecting real life images captured using a smartphone; this enables us to obtain state-of-the-art results on common real life images. The proposed model DISCO is pre-trained on the synthetic Scene Flow dataset and evaluated on popular benchmarks and our in-house dataset of challenging real life images. The proposed model outperforms existing state-of-the-art methods in terms of quality as well as quantitative metrics.