 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers for Image-Goal Navigation
May 23, 2024
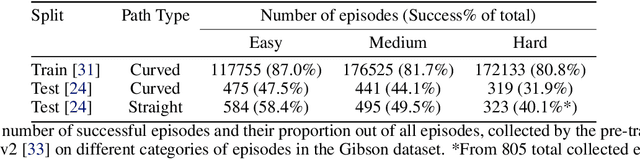
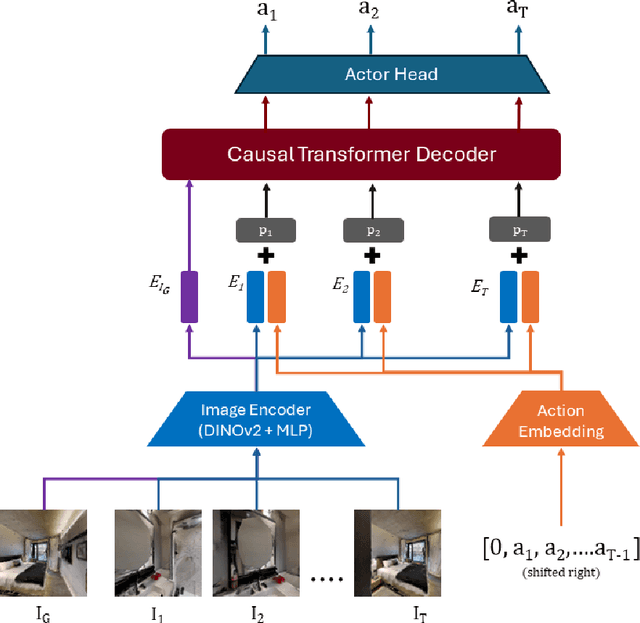
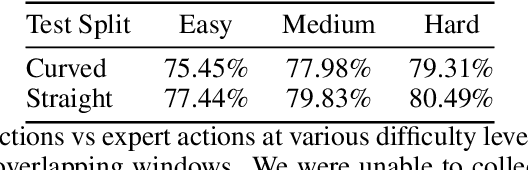
Visual perception and navigation have emerged as major focus areas in the field of embodied artificial intelligence. We consider the task of image-goal navigation, where an agent is tasked to navigate to a goal specified by an image, relying only on images from an onboard camera. This task is particularly challenging since it demands robust scene understanding, goal-oriented planning and long-horizon navigation. Most existing approaches typically learn navigation policies reliant on recurrent neural networks trained via online reinforcement learning. However, training such policies requires substantial computational resources and time, and performance of these models is not reliable on long-horizon navigation. In this work, we present a generative Transformer based model that jointly models image goals, camera observations and the robot's past actions to predict future actions. We use state-of-the-art perception models and navigation policies to learn robust goal conditioned policies without the need for real-time interaction with the environment. Our model demonstrates capability in capturing and associating visual information across long time horizons, helping in effective navigation.
DISCO: Depth Inference from Stereo using Context
May 31, 2019
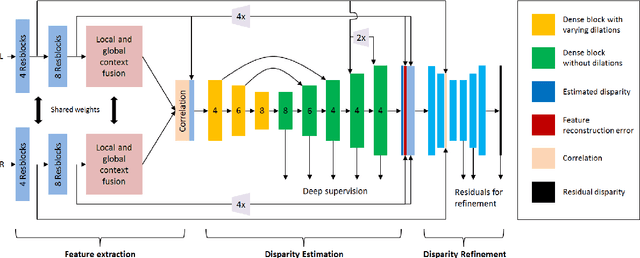
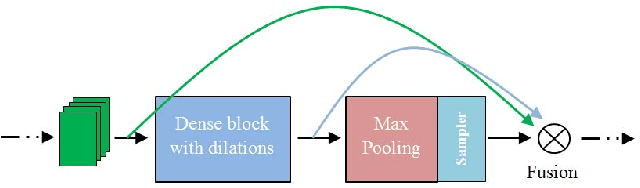

Recent deep learning based approaches have outperformed classical stereo matching methods. However, current deep learning based end-to-end stereo matching methods adopt a generic encoder-decoder style network with skip connections. To limit computational requirement, many networks perform excessive down sampling, which results in significant loss of useful low-level information. Additionally, many network designs do not exploit the rich multi-scale contextual information. In this work, we address these aforementioned problems by carefully designing the network architecture to preserve required spatial information throughout the network, while at the same time achieve large effective receptive field to extract multiscale contextual information. For the first time, we create a synthetic disparity dataset reflecting real life images captured using a smartphone; this enables us to obtain state-of-the-art results on common real life images. The proposed model DISCO is pre-trained on the synthetic Scene Flow dataset and evaluated on popular benchmarks and our in-house dataset of challenging real life images. The proposed model outperforms existing state-of-the-art methods in terms of quality as well as quantitative metrics.