 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers for Image-Goal Navigation
Paper and Code
May 23, 2024
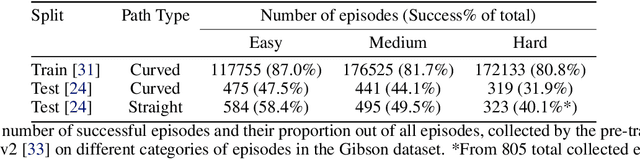
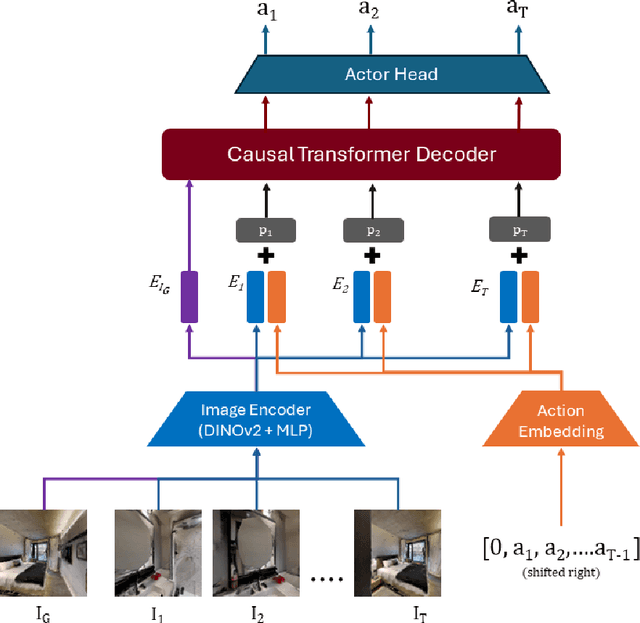
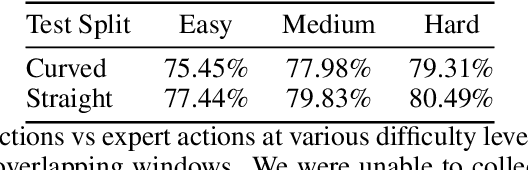
Visual perception and navigation have emerged as major focus areas in the field of embodied artificial intelligence. We consider the task of image-goal navigation, where an agent is tasked to navigate to a goal specified by an image, relying only on images from an onboard camera. This task is particularly challenging since it demands robust scene understanding, goal-oriented planning and long-horizon navigation. Most existing approaches typically learn navigation policies reliant on recurrent neural networks trained via online reinforcement learning. However, training such policies requires substantial computational resources and time, and performance of these models is not reliable on long-horizon navigation. In this work, we present a generative Transformer based model that jointly models image goals, camera observations and the robot's past actions to predict future actions. We use state-of-the-art perception models and navigation policies to learn robust goal conditioned policies without the need for real-time interaction with the environment. Our model demonstrates capability in capturing and associating visual information across long time horizons, helping in effective navigation.