 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDel-Net: A Single-Stage Network for Mobile Camera ISP
Aug 03, 2021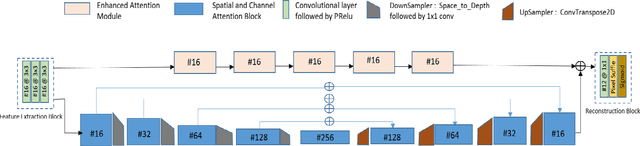
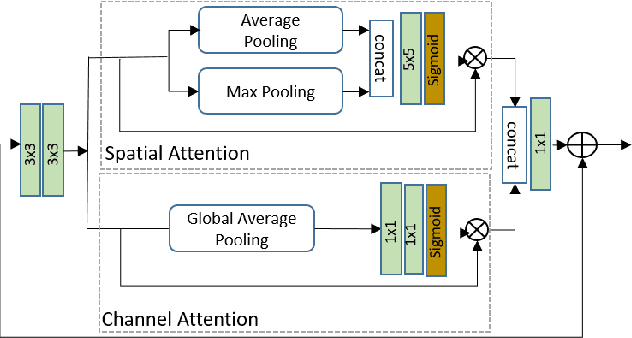
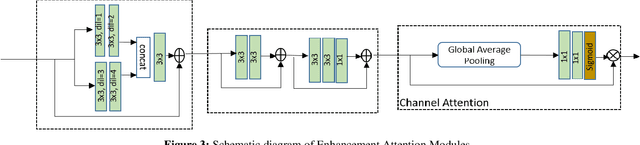
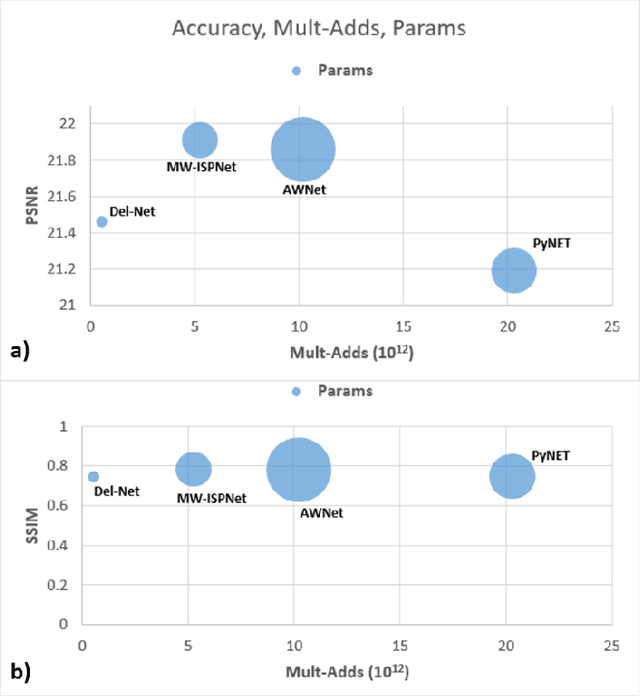
The quality of images captured by smartphones is an important specification since smartphones are becoming ubiquitous as primary capturing devices. The traditional image signal processing (ISP) pipeline in a smartphone camera consists of several image processing steps performed sequentially to reconstruct a high quality sRGB image from the raw sensor data. These steps consist of demosaicing, denoising, white balancing, gamma correction, colour enhancement, etc. Since each of them are performed sequentially using hand-crafted algorithms, the residual error from each processing module accumulates in the final reconstructed signal. Thus, the traditional ISP pipeline has limited reconstruction quality in terms of generalizability across different lighting conditions and associated noise levels while capturing the image. Deep learning methods using convolutional neural networks (CNN) have become popular in solving many image-related tasks such as image denoising, contrast enhancement, super resolution, deblurring, etc. Furthermore, recent approaches for the RAW to sRGB conversion using deep learning methods have also been published, however, their immense complexity in terms of their memory requirement and number of Mult-Adds make them unsuitable for mobile camera ISP. In this paper we propose DelNet - a single end-to-end deep learning model - to learn the entire ISP pipeline within reasonable complexity for smartphone deployment. Del-Net is a multi-scale architecture that uses spatial and channel attention to capture global features like colour, as well as a series of lightweight modified residual attention blocks to help with denoising. For validation, we provide results to show the proposed Del-Net achieves compelling reconstruction quality.
Why my photos look sideways or upside down? Detecting Canonical Orientation of Images using Convolutional Neural Networks
Dec 04, 2017
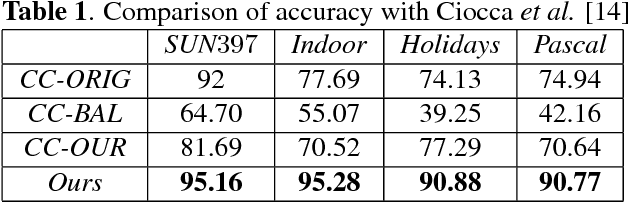
Image orientation detection requires high-level scene understanding. Humans use object recognition and contextual scene information to correctly orient images. In literature, the problem of image orientation detection is mostly confronted by using low-level vision features, while some approaches incorporate few easily detectable semantic cues to gain minor improvements. The vast amount of semantic content in images makes orientation detection challenging, and therefore there is a large semantic gap between existing methods and human behavior. Also, existing methods in literature report highly discrepant detection rates, which is mainly due to large differences in datasets and limited variety of test images used for evaluation. In this work, for the first time, we leverage the power of deep learning and adapt pre-trained convolutional neural networks using largest training dataset to-date for the image orientation detection task. An extensive evaluation of our model on different public datasets shows that it remarkably generalizes to correctly orient a large set of unconstrained images; it also significantly outperforms the state-of-the-art and achieves accuracy very close to that of humans.