 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning of Visual-Semantic Embeddings
Oct 17, 2021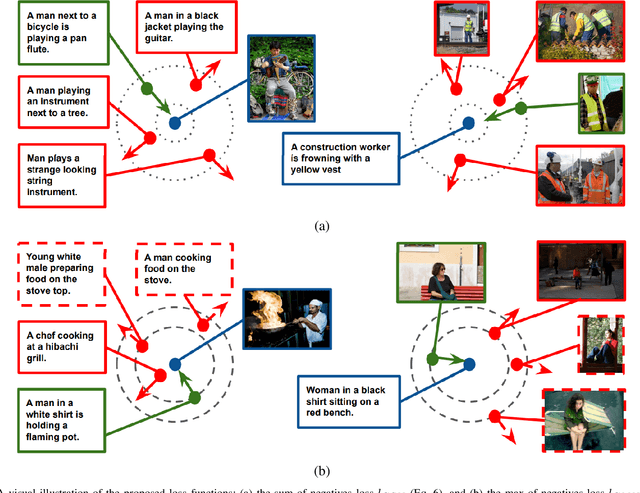


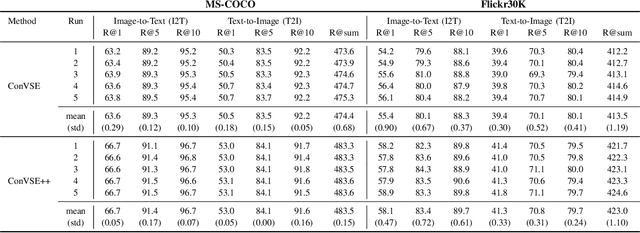
Contrastive learning is a powerful technique to learn representations that are semantically distinctive and geometrically invariant. While most of the earlier approaches have demonstrated its effectiveness on single-modality learning tasks such as image classification, recently there have been a few attempts towards extending this idea to multi-modal data. In this paper, we propose two loss functions based on normalized cross-entropy to perform the task of learning joint visual-semantic embedding using batch contrastive training. In a batch, for a given anchor point from one modality, we consider its negatives only from another modality, and define our first contrastive loss based on expected violations incurred by all the negatives. Next, we update this loss and define the second contrastive loss based on the violation incurred only by the hardest negative. We compare our results with existing visual-semantic embedding methods on cross-modal image-to-text and text-to-image retrieval tasks using the MS-COCO and Flickr30K datasets, where we outperform the state-of-the-art on the MS-COCO dataset and achieve comparable results on the Flickr30K dataset.
Del-Net: A Single-Stage Network for Mobile Camera ISP
Aug 03, 2021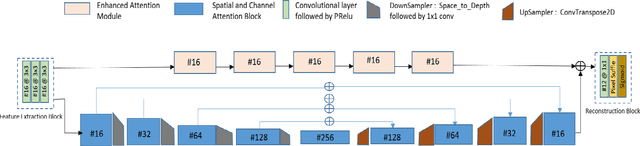
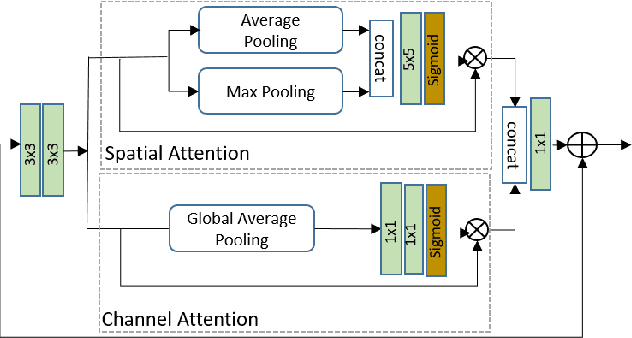
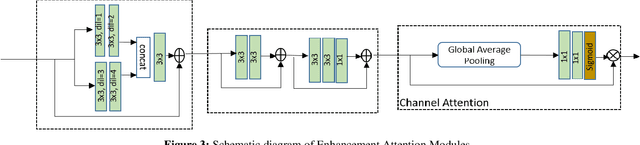
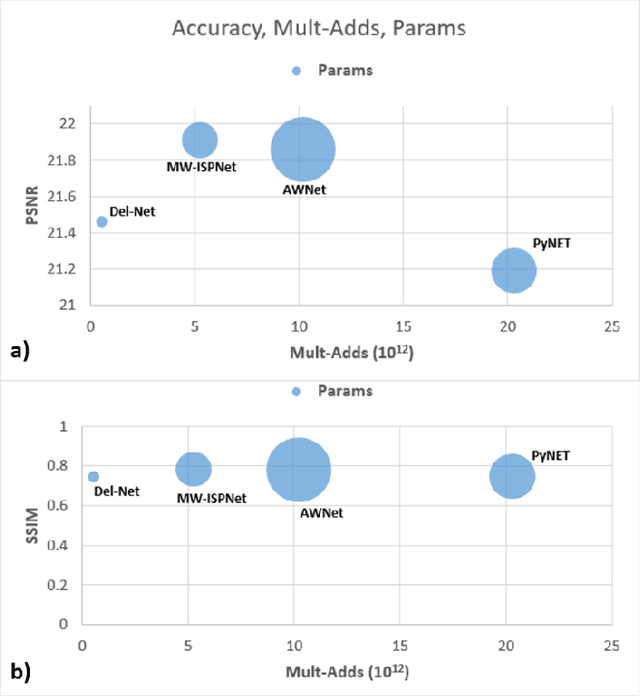
The quality of images captured by smartphones is an important specification since smartphones are becoming ubiquitous as primary capturing devices. The traditional image signal processing (ISP) pipeline in a smartphone camera consists of several image processing steps performed sequentially to reconstruct a high quality sRGB image from the raw sensor data. These steps consist of demosaicing, denoising, white balancing, gamma correction, colour enhancement, etc. Since each of them are performed sequentially using hand-crafted algorithms, the residual error from each processing module accumulates in the final reconstructed signal. Thus, the traditional ISP pipeline has limited reconstruction quality in terms of generalizability across different lighting conditions and associated noise levels while capturing the image. Deep learning methods using convolutional neural networks (CNN) have become popular in solving many image-related tasks such as image denoising, contrast enhancement, super resolution, deblurring, etc. Furthermore, recent approaches for the RAW to sRGB conversion using deep learning methods have also been published, however, their immense complexity in terms of their memory requirement and number of Mult-Adds make them unsuitable for mobile camera ISP. In this paper we propose DelNet - a single end-to-end deep learning model - to learn the entire ISP pipeline within reasonable complexity for smartphone deployment. Del-Net is a multi-scale architecture that uses spatial and channel attention to capture global features like colour, as well as a series of lightweight modified residual attention blocks to help with denoising. For validation, we provide results to show the proposed Del-Net achieves compelling reconstruction quality.