 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning of Visual-Semantic Embeddings
Paper and Code
Oct 17, 2021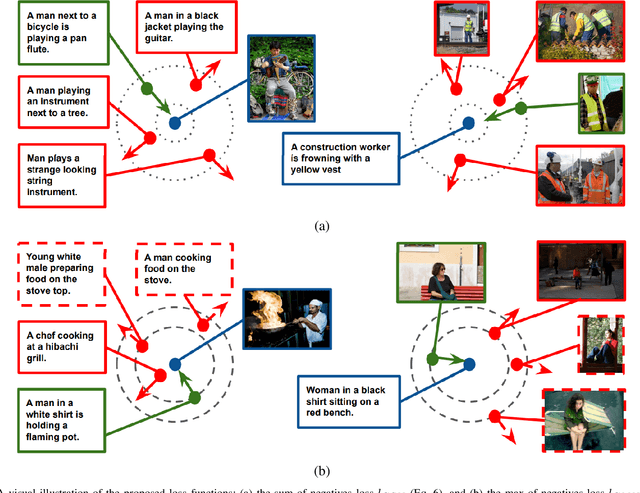


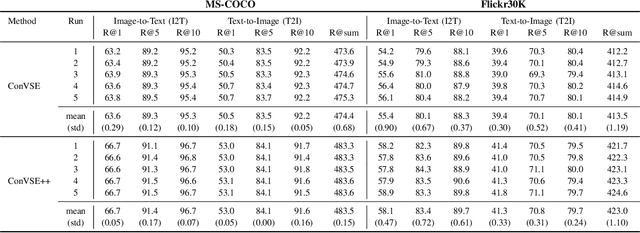
Contrastive learning is a powerful technique to learn representations that are semantically distinctive and geometrically invariant. While most of the earlier approaches have demonstrated its effectiveness on single-modality learning tasks such as image classification, recently there have been a few attempts towards extending this idea to multi-modal data. In this paper, we propose two loss functions based on normalized cross-entropy to perform the task of learning joint visual-semantic embedding using batch contrastive training. In a batch, for a given anchor point from one modality, we consider its negatives only from another modality, and define our first contrastive loss based on expected violations incurred by all the negatives. Next, we update this loss and define the second contrastive loss based on the violation incurred only by the hardest negative. We compare our results with existing visual-semantic embedding methods on cross-modal image-to-text and text-to-image retrieval tasks using the MS-COCO and Flickr30K datasets, where we outperform the state-of-the-art on the MS-COCO dataset and achieve comparable results on the Flickr30K dataset.