 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-based Early Autism Diagnosis Using Contrastive Feature Learning
Sep 12, 2022
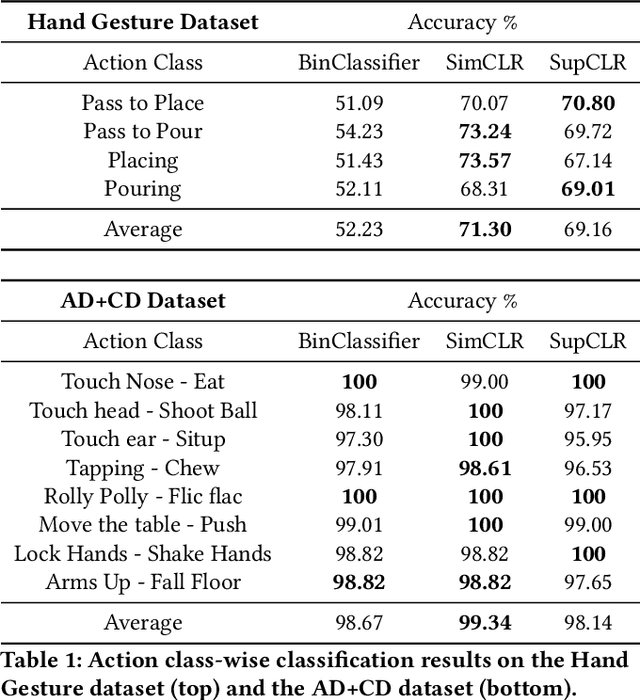

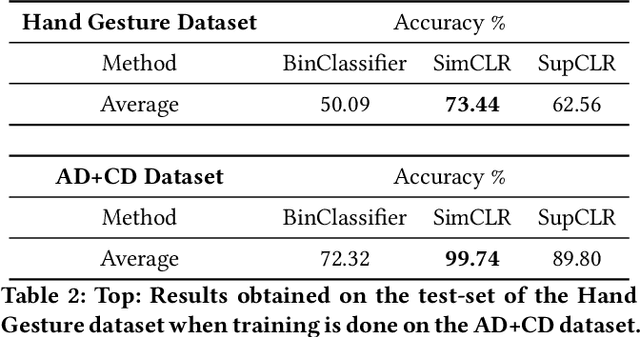
Autism, also known as Autism Spectrum Disorder (or ASD), is a neurological disorder. Its main symptoms include difficulty in (verbal and/or non-verbal) communication, and rigid/repetitive behavior. These symptoms are often indistinguishable from a normal (control) individual, due to which this disorder remains undiagnosed in early childhood leading to delayed treatment. Since the learning curve is steep during the initial age, an early diagnosis of autism could allow to take adequate interventions at the right time, which might positively affect the growth of an autistic child. Further, the traditional methods of autism diagnosis require multiple visits to a specialized psychiatrist, however this process can be time-consuming. In this paper, we present a learning based approach to automate autism diagnosis using simple and small action video clips of subjects. This task is particularly challenging because the amount of annotated data available is small, and the variations among samples from the two categories (ASD and control) are generally indistinguishable. This is also evident from poor performance of a binary classifier learned using the cross-entropy loss on top of a baseline encoder. To address this, we adopt contrastive feature learning in both self supervised and supervised learning frameworks, and show that these can lead to a significant increase in the prediction accuracy of a binary classifier on this task. We further validate this by conducting thorough experimental analyses under different set-ups on two publicly available datasets.
Contrastive Learning of Visual-Semantic Embeddings
Oct 17, 2021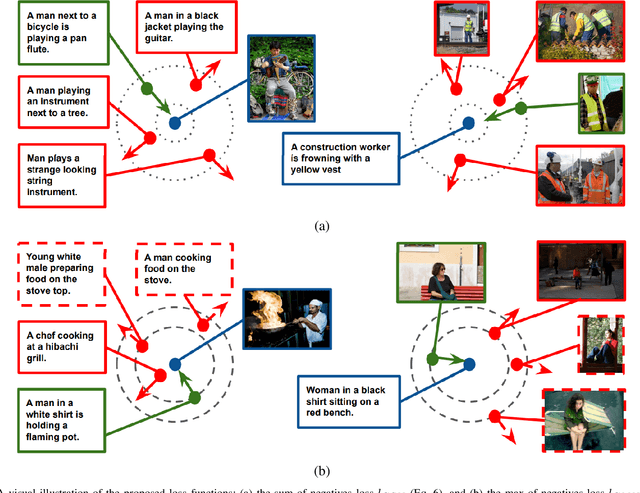


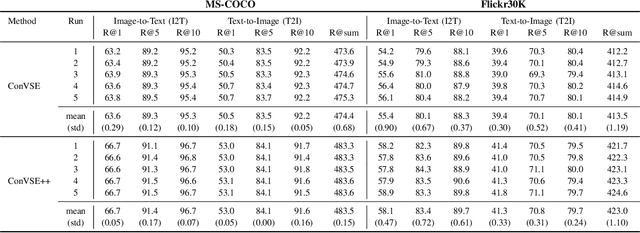
Contrastive learning is a powerful technique to learn representations that are semantically distinctive and geometrically invariant. While most of the earlier approaches have demonstrated its effectiveness on single-modality learning tasks such as image classification, recently there have been a few attempts towards extending this idea to multi-modal data. In this paper, we propose two loss functions based on normalized cross-entropy to perform the task of learning joint visual-semantic embedding using batch contrastive training. In a batch, for a given anchor point from one modality, we consider its negatives only from another modality, and define our first contrastive loss based on expected violations incurred by all the negatives. Next, we update this loss and define the second contrastive loss based on the violation incurred only by the hardest negative. We compare our results with existing visual-semantic embedding methods on cross-modal image-to-text and text-to-image retrieval tasks using the MS-COCO and Flickr30K datasets, where we outperform the state-of-the-art on the MS-COCO dataset and achieve comparable results on the Flickr30K dataset.
An Embarrassingly Simple Baseline for eXtreme Multi-label Prediction
Dec 17, 2019
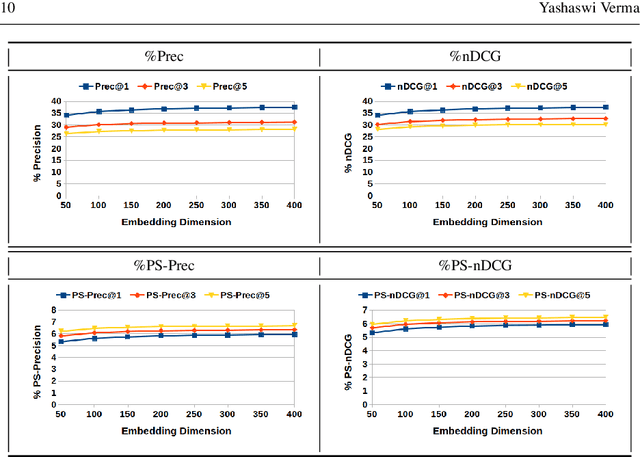

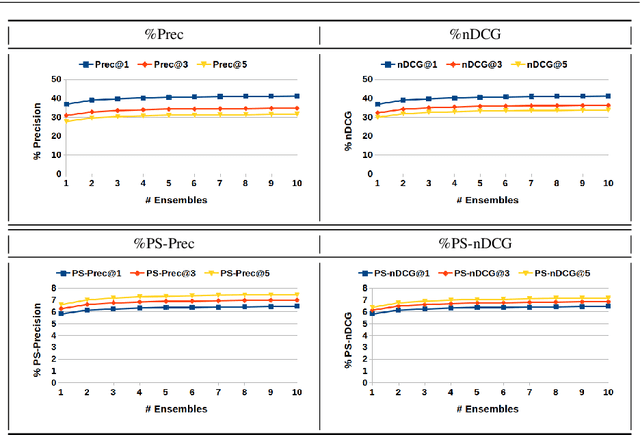
The goal of eXtreme Multi-label Learning (XML) is to design and learn a model that can automatically annotate a given data point with the most relevant subset of labels from an extremely large label set. Recently, many techniques have been proposed for XML that achieve reasonable performance on benchmark datasets. Motivated by the complexities of these methods and their subsequent training requirements, in this paper we propose a simple baseline technique for this task. Precisely, we present a global feature embedding technique for XML that can easily scale to very large datasets containing millions of data points in very high-dimensional feature space, irrespective of number of samples and labels. Next we show how an ensemble of such global embeddings can be used to achieve further boost in prediction accuracies with only linear increase in training and prediction time. During testing, we assign the labels using a weighted k-nearest neighbour classifier in the embedding space. Experiments reveal that though conceptually simple, this technique achieves quite competitive results, and has training time of less than one minute using a single CPU core with 15.6 GB RAM even for large-scale datasets such as Amazon-3M.