 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARBLE: Multi-Armed Restless Bandits in Latent Markovian Environment
Nov 12, 2025Restless Multi-Armed Bandits (RMABs) are powerful models for decision-making under uncertainty, yet classical formulations typically assume fixed dynamics, an assumption often violated in nonstationary environments. We introduce MARBLE (Multi-Armed Restless Bandits in a Latent Markovian Environment), which augments RMABs with a latent Markov state that induces nonstationary behavior. In MARBLE, each arm evolves according to a latent environment state that switches over time, making policy learning substantially more challenging. We further introduce the Markov-Averaged Indexability (MAI) criterion as a relaxed indexability assumption and prove that, despite unobserved regime switches, under the MAI criterion, synchronous Q-learning with Whittle Indices (QWI) converges almost surely to the optimal Q-function and the corresponding Whittle indices. We validate MARBLE on a calibrated simulator-embedded (digital twin) recommender system, where QWI consistently adapts to a shifting latent state and converges to an optimal policy, empirically corroborating our theoretical findings.
From Leiden to Pleasure Island: The Constant Potts Model for Community Detection as a Hedonic Game
Sep 04, 2025Community detection is one of the fundamental problems in data science which consists of partitioning nodes into disjoint communities. We present a game-theoretic perspective on the Constant Potts Model (CPM) for partitioning networks into disjoint communities, emphasizing its efficiency, robustness, and accuracy. Efficiency: We reinterpret CPM as a potential hedonic game by decomposing its global Hamiltonian into local utility functions, where the local utility gain of each agent matches the corresponding increase in global utility. Leveraging this equivalence, we prove that local optimization of the CPM objective via better-response dynamics converges in pseudo-polynomial time to an equilibrium partition. Robustness: We introduce and relate two stability criteria: a strict criterion based on a novel notion of robustness, requiring nodes to simultaneously maximize neighbors and minimize non-neighbors within communities, and a relaxed utility function based on a weighted sum of these objectives, controlled by a resolution parameter. Accuracy: In community tracking scenarios, where initial partitions are used to bootstrap the Leiden algorithm with partial ground-truth information, our experiments reveal that robust partitions yield higher accuracy in recovering ground-truth communities.
Consistent line clustering using geometric hypergraphs
May 30, 2025Traditional data analysis often represents data as a weighted graph with pairwise similarities, but many problems do not naturally fit this framework. In line clustering, points in a Euclidean space must be grouped so that each cluster is well approximated by a line segment. Since any two points define a line, pairwise similarities fail to capture the structure of the problem, necessitating the use of higher-order interactions modeled by geometric hypergraphs. We encode geometry into a 3-uniform hypergraph by treating sets of three points as hyperedges whenever they are approximately collinear. The resulting hypergraph contains information about the underlying line segments, which can then be extracted using community recovery algorithms. In contrast to classical hypergraph block models, latent geometric constraints in this construction introduce significant dependencies between hyperedges, which restricts the applicability of many standard theoretical tools. We aim to determine the fundamental limits of line clustering and evaluate hypergraph-based line clustering methods. To this end, we derive information-theoretic thresholds for exact and almost exact recovery for data generated from intersecting lines on a plane with additive Gaussian noise. We develop a polynomial-time spectral algorithm and show that it succeeds under noise conditions that match the information-theoretic bounds up to a polylogarithmic factor.
Lagrangian Index Policy for Restless Bandits with Average Reward
Dec 17, 2024



We study the Lagrangian Index Policy (LIP) for restless multi-armed bandits with long-run average reward. In particular, we compare the performance of LIP with the performance of the Whittle Index Policy (WIP), both heuristic policies known to be asymptotically optimal under certain natural conditions. Even though in most cases their performances are very similar, in the cases when WIP shows bad performance, LIP continues to perform very well. We then propose reinforcement learning algorithms, both tabular and NN-based, to obtain online learning schemes for LIP in the model-free setting. The proposed reinforcement learning schemes for LIP requires significantly less memory than the analogous scheme for WIP. We calculate analytically the Lagrangian index for the restart model, which describes the optimal web crawling and the minimization of the weighted age of information. We also give a new proof of asymptotic optimality in case of homogeneous bandits as the number of arms goes to infinity, based on exchangeability and de Finetti's theorem.
Tabular and Deep Learning for the Whittle Index
Jun 04, 2024
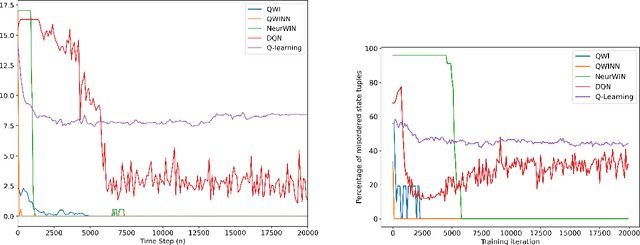

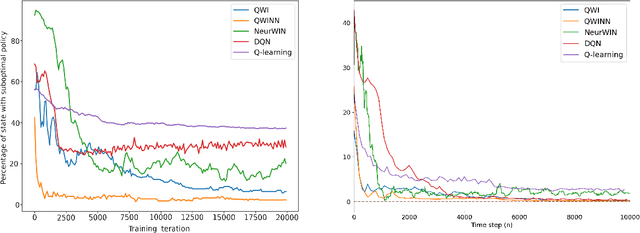
The Whittle index policy is a heuristic that has shown remarkably good performance (with guaranteed asymptotic optimality) when applied to the class of problems known as Restless Multi-Armed Bandit Problems (RMABPs). In this paper we present QWI and QWINN, two reinforcement learning algorithms, respectively tabular and deep, to learn the Whittle index for the total discounted criterion. The key feature is the use of two time-scales, a faster one to update the state-action Q -values, and a relatively slower one to update the Whittle indices. In our main theoretical result we show that QWI, which is a tabular implementation, converges to the real Whittle indices. We then present QWINN, an adaptation of QWI algorithm using neural networks to compute the Q -values on the faster time-scale, which is able to extrapolate information from one state to another and scales naturally to large state-space environments. For QWINN, we show that all local minima of the Bellman error are locally stable equilibria, which is the first result of its kind for DQN-based schemes. Numerical computations show that QWI and QWINN converge faster than the standard Q -learning algorithm, neural-network based approximate Q-learning and other state of the art algorithms.
Deep reinforcement learning for weakly coupled MDP's with continuous actions
Jun 03, 2024This paper introduces the Lagrange Policy for Continuous Actions (LPCA), a reinforcement learning algorithm specifically designed for weakly coupled MDP problems with continuous action spaces. LPCA addresses the challenge of resource constraints dependent on continuous actions by introducing a Lagrange relaxation of the weakly coupled MDP problem within a neural network framework for Q-value computation. This approach effectively decouples the MDP, enabling efficient policy learning in resource-constrained environments. We present two variations of LPCA: LPCA-DE, which utilizes differential evolution for global optimization, and LPCA-Greedy, a method that incrementally and greadily selects actions based on Q-value gradients. Comparative analysis against other state-of-the-art techniques across various settings highlight LPCA's robustness and efficiency in managing resource allocation while maximizing rewards.
Full Gradient Deep Reinforcement Learning for Average-Reward Criterion
Apr 07, 2023


We extend the provably convergent Full Gradient DQN algorithm for discounted reward Markov decision processes from Avrachenkov et al. (2021) to average reward problems. We experimentally compare widely used RVI Q-Learning with recently proposed Differential Q-Learning in the neural function approximation setting with Full Gradient DQN and DQN. We also extend this to learn Whittle indices for Markovian restless multi-armed bandits. We observe a better convergence rate of the proposed Full Gradient variant across different tasks.
Multilayer hypergraph clustering using the aggregate similarity matrix
Jan 27, 2023We consider the community recovery problem on a multilayer variant of the hypergraph stochastic block model (HSBM). Each layer is associated with an independent realization of a d-uniform HSBM on N vertices. Given the aggregated number of hyperedges incident to each pair of vertices, represented using a similarity matrix, the goal is to obtain a partition of the N vertices into disjoint communities. In this work, we investigate a semidefinite programming (SDP) approach and obtain information-theoretic conditions on the model parameters that guarantee exact recovery both in the assortative and the disassortative cases.
Higher-Order Spectral Clustering for Geometric Graphs
Sep 23, 2020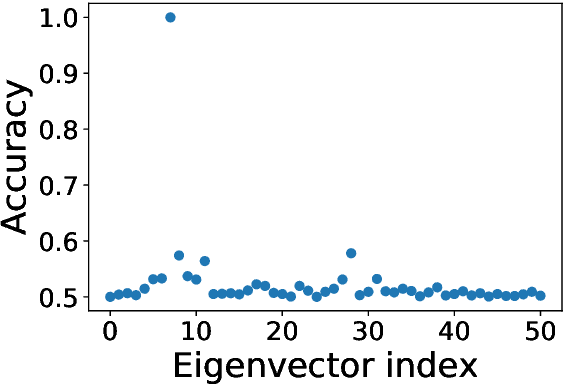
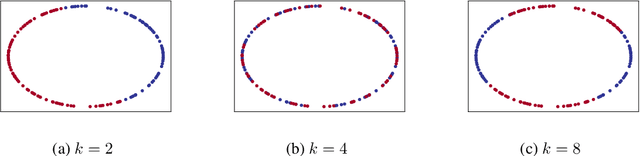
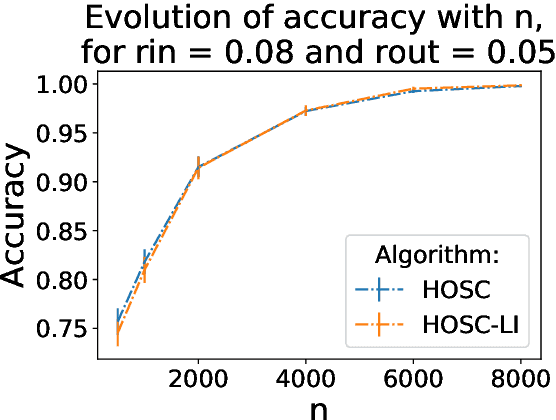
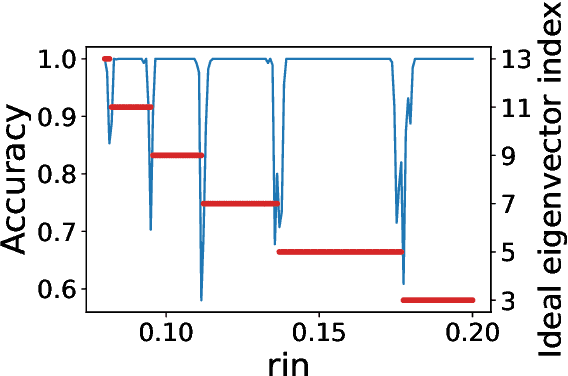
The present paper is devoted to clustering geometric graphs. While the standard spectral clustering is often not effective for geometric graphs, we present an effective generalization, which we call higher-order spectral clustering. It resembles in concept the classical spectral clustering method but uses for partitioning the eigenvector associated with a higher-order eigenvalue. We establish the weak consistency of this algorithm for a wide class of geometric graphs which we call Soft Geometric Block Model. A small adjustment of the algorithm provides strong consistency. We also show that our method is effective in numerical experiments even for graphs of modest size.
Online Algorithms for Estimating Change Rates of Web Pages
Sep 17, 2020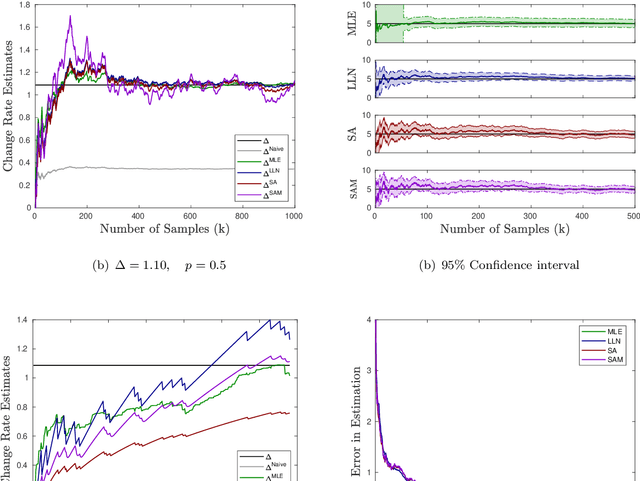
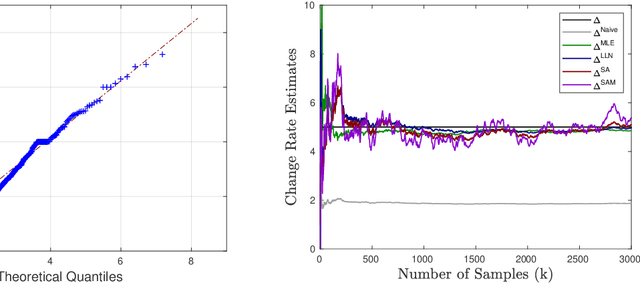
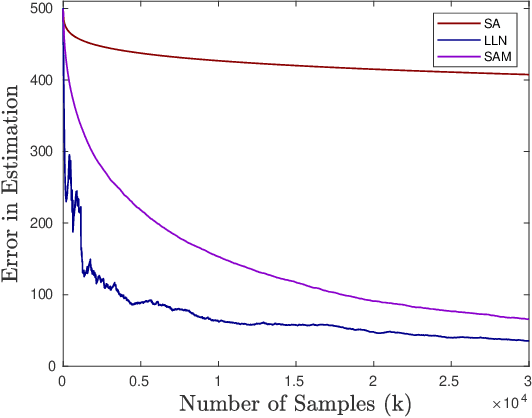

For providing quick and accurate search results, a search engine maintains a local snapshot of the entire web. And, to keep this local cache fresh, it employs a crawler for tracking changes across various web pages. It would have been ideal if the crawler managed to update the local snapshot as soon as a page changed on the web. However, finite bandwidth availability and server restrictions mean that there is a bound on how frequently the different pages can be crawled. This then brings forth the following optimisation problem: maximise the freshness of the local cache subject to the crawling frequency being within the prescribed bounds. Recently, tractable algorithms have been proposed to solve this optimisation problem under different cost criteria. However, these assume the knowledge of exact page change rates, which is unrealistic in practice. We address this issue here. Specifically, we provide three novel schemes for online estimation of page change rates. All these schemes only need partial information about the page change process, i.e., they only need to know if the page has changed or not since the last crawl instance. Our first scheme is based on the law of large numbers, the second on the theory of stochastic approximation, while the third is an extension of the second and involves an additional momentum term. For all of these schemes, we prove convergence and, also, provide their convergence rates. As far as we know, the results concerning the third estimator is quite novel. Specifically, this is the first convergence type result for a stochastic approximation algorithm with momentum. Finally, we provide some numerical experiments (on real as well as synthetic data) to compare the performance of our proposed estimators with the existing ones (e.g., MLE).