 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMTM: Multi-Tasking Multi-Decoder Transformer for Math Word Problems
Jun 02, 2022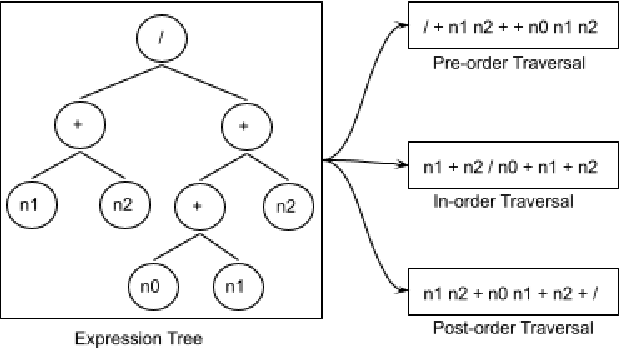
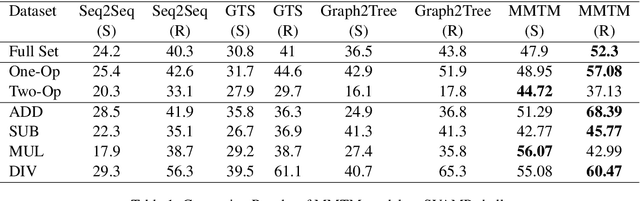
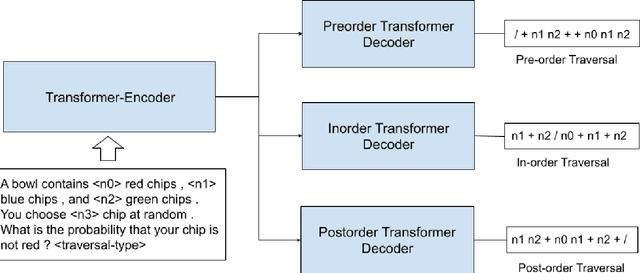

Recently, quite a few novel neural architectures were derived to solve math word problems by predicting expression trees. These architectures varied from seq2seq models, including encoders leveraging graph relationships combined with tree decoders. These models achieve good performance on various MWPs datasets but perform poorly when applied to an adversarial challenge dataset, SVAMP. We present a novel model MMTM that leverages multi-tasking and multi-decoder during pre-training. It creates variant tasks by deriving labels using pre-order, in-order and post-order traversal of expression trees, and uses task-specific decoders in a multi-tasking framework. We leverage transformer architectures with lower dimensionality and initialize weights from RoBERTa model. MMTM model achieves better mathematical reasoning ability and generalisability, which we demonstrate by outperforming the best state of the art baseline models from Seq2Seq, GTS, and Graph2Tree with a relative improvement of 19.4% on an adversarial challenge dataset SVAMP.
Towards Tractable Mathematical Reasoning: Challenges, Strategies, and Opportunities for Solving Math Word Problems
Oct 29, 2021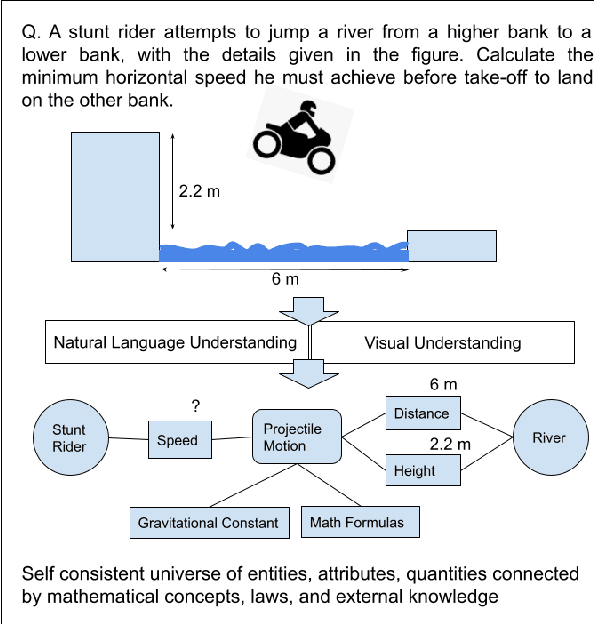

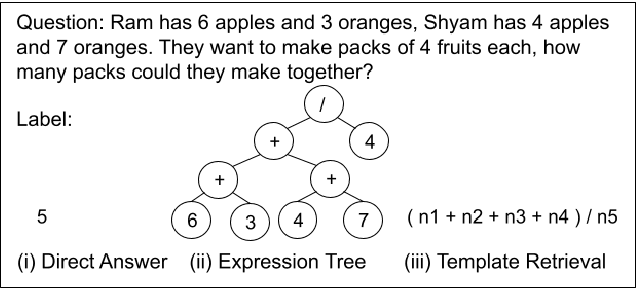
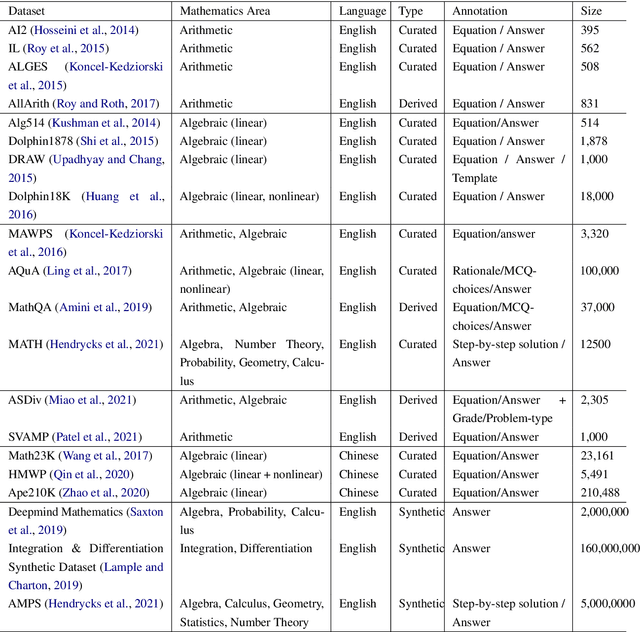
Mathematical reasoning would be one of the next frontiers for artificial intelligence to make significant progress. The ongoing surge to solve math word problems (MWPs) and hence achieve better mathematical reasoning ability would continue to be a key line of research in the coming time. We inspect non-neural and neural methods to solve math word problems narrated in a natural language. We also highlight the ability of these methods to be generalizable, mathematically reasonable, interpretable, and explainable. Neural approaches dominate the current state of the art, and we survey them highlighting three strategies to MWP solving: (1) direct answer generation, (2) expression tree generation for inferring answers, and (3) template retrieval for answer computation. Moreover, we discuss technological approaches, review the evolution of intuitive design choices to solve MWPs, and examine them for mathematical reasoning ability. We finally identify several gaps that warrant the need for external knowledge and knowledge-infused learning, among several other opportunities in solving MWPs.
Knowledge-intensive Language Understanding for Explainable AI
Aug 02, 2021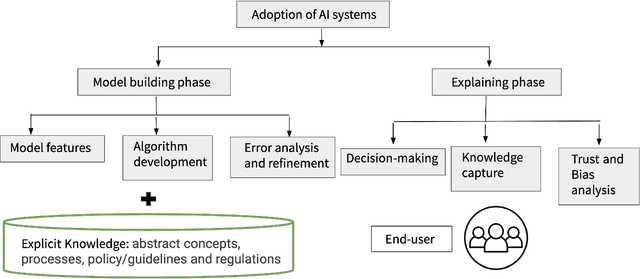


AI systems have seen significant adoption in various domains. At the same time, further adoption in some domains is hindered by inability to fully trust an AI system that it will not harm a human. Besides the concerns for fairness, privacy, transparency, and explainability are key to developing trusts in AI systems. As stated in describing trustworthy AI "Trust comes through understanding. How AI-led decisions are made and what determining factors were included are crucial to understand." The subarea of explaining AI systems has come to be known as XAI. Multiple aspects of an AI system can be explained; these include biases that the data might have, lack of data points in a particular region of the example space, fairness of gathering the data, feature importances, etc. However, besides these, it is critical to have human-centered explanations that are directly related to decision-making similar to how a domain expert makes decisions based on "domain knowledge," that also include well-established, peer-validated explicit guidelines. To understand and validate an AI system's outcomes (such as classification, recommendations, predictions), that lead to developing trust in the AI system, it is necessary to involve explicit domain knowledge that humans understand and use.
KI-BERT: Infusing Knowledge Context for Better Language and Domain Understanding
Apr 09, 2021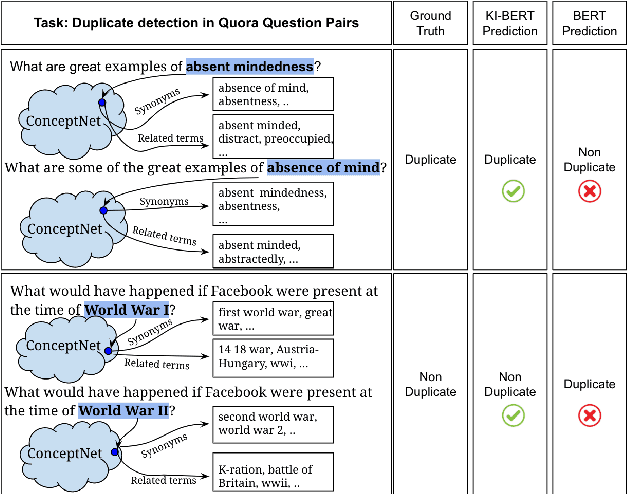
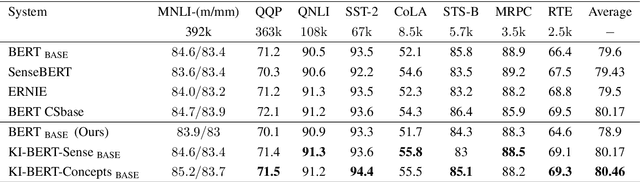
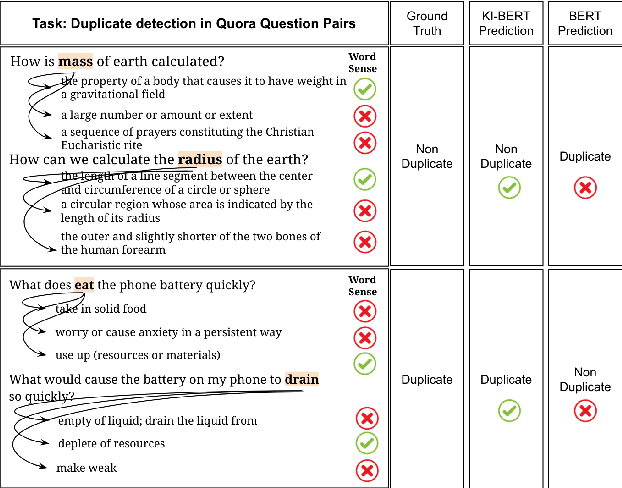

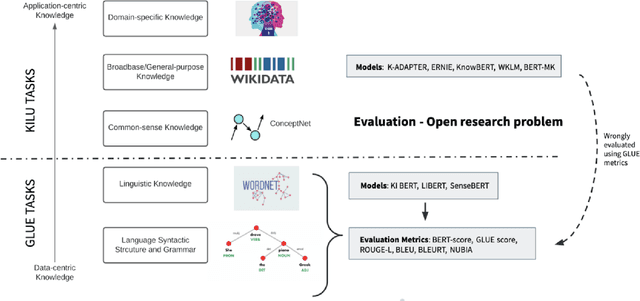
Contextualized entity representations learned by state-of-the-art deep learning models (BERT, GPT, T5, etc) leverage the attention mechanism to learn the data context. However, these models are still blind to leverage the knowledge context present in the knowledge graph. Knowledge context can be understood as semantics about entities, and their relationship with neighboring entities in knowledge graphs. We propose a novel and effective technique to infuse knowledge context from knowledge graphs for conceptual and ambiguous entities into models based on transformer architecture. Our novel technique project knowledge graph embedding in the homogeneous vector-space, introduces new token-types for entities, align entity position ids, and a selective attention mechanism. We take BERT as a baseline model and implement "KnowledgeInfused BERT" by infusing knowledge context from ConceptNet and WordNet, which significantly outperforms BERT over a wide range of NLP tasks over eight different GLUE datasets. KI-BERT-base model even outperforms BERT-large for domain-specific tasks like SciTail and academic subsets of QQP, QNLI, and MNLI.
Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable?
Nov 03, 2020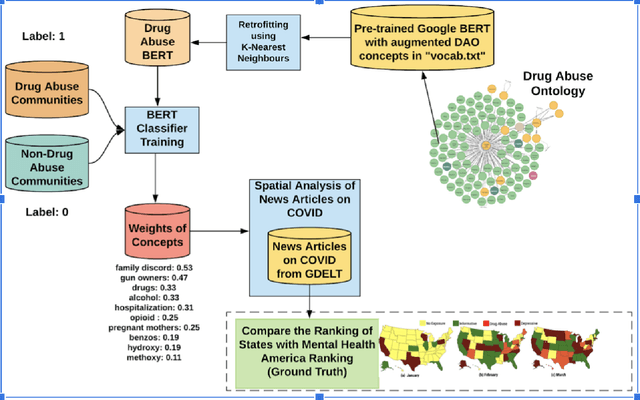


The recent series of innovations in deep learning (DL) have shown enormous potential to impact individuals and society, both positively and negatively. The DL models utilizing massive computing power and enormous datasets have significantly outperformed prior historical benchmarks on increasingly difficult, well-defined research tasks across technology domains such as computer vision, natural language processing, signal processing, and human-computer interactions. However, the Black-Box nature of DL models and their over-reliance on massive amounts of data condensed into labels and dense representations poses challenges for interpretability and explainability of the system. Furthermore, DLs have not yet been proven in their ability to effectively utilize relevant domain knowledge and experience critical to human understanding. This aspect is missing in early data-focused approaches and necessitated knowledge-infused learning and other strategies to incorporate computational knowledge. This article demonstrates how knowledge, provided as a knowledge graph, is incorporated into DL methods using knowledge-infused learning, which is one of the strategies. We then discuss how this makes a fundamental difference in the interpretability and explainability of current approaches, and illustrate it with examples from natural language processing for healthcare and education applications.
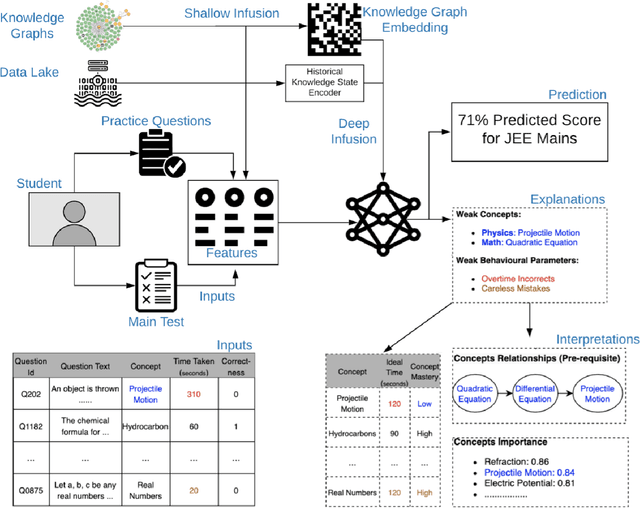
A framework for predicting, interpreting, and improving Learning Outcomes
Oct 12, 2020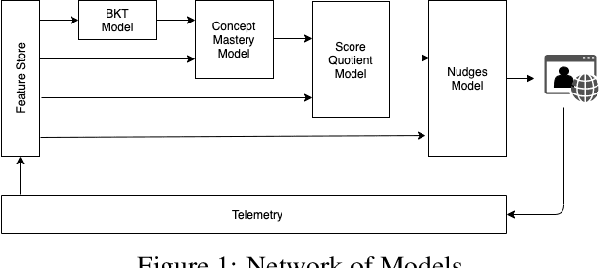

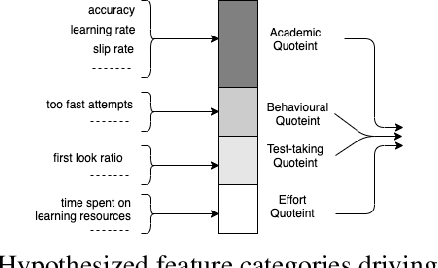
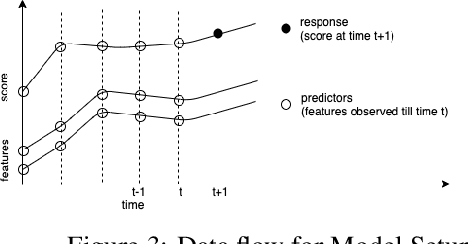
It has long been recognized that academic success is a result of both cognitive and non-cognitive dimensions acting together. Consequently, any intelligent learning platform designed to improve learning outcomes (LOs) must provide actionable inputs to the learner in these dimensions. However, operationalizing such inputs in a production setting that is scalable is not trivial. We develop an Embibe Score Quotient model (ESQ) to predict test scores based on observed academic, behavioral and test-taking features of a student. ESQ can be used to predict the future scoring potential of a student as well as offer personalized learning nudges, both critical to improving LOs. Multiple machine learning models are evaluated for the prediction task. In order to provide meaningful feedback to the learner, individualized Shapley feature attributions for each feature are computed. Prediction intervals are obtained by applying non-parametric quantile regression, in an attempt to quantify the uncertainty in the predictions. We apply the above modelling strategy on a dataset consisting of more than a hundred million learner interactions on the Embibe learning platform. We observe that the Median Absolute Error between the observed and predicted scores is 4.58% across several user segments, and the correlation between predicted and observed responses is 0.93. Game-like what-if scenarios are played out to see the changes in LOs, on counterfactual examples. We briefly discuss how a rational agent can then apply an optimal policy to affect the learning outcomes by treating the above model like an Oracle.