 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKI-BERT: Infusing Knowledge Context for Better Language and Domain Understanding
Paper and Code
Apr 09, 2021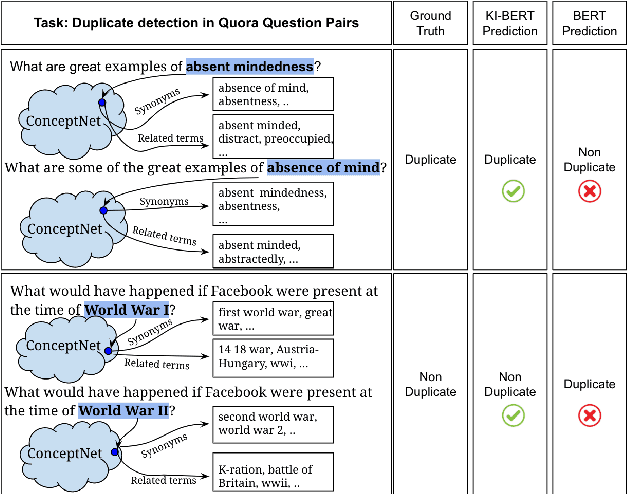
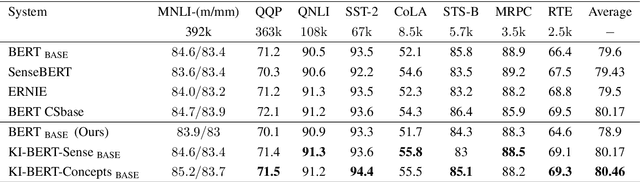
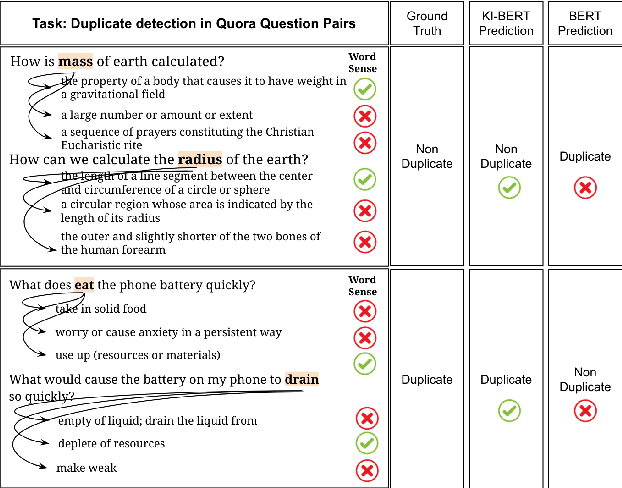

Contextualized entity representations learned by state-of-the-art deep learning models (BERT, GPT, T5, etc) leverage the attention mechanism to learn the data context. However, these models are still blind to leverage the knowledge context present in the knowledge graph. Knowledge context can be understood as semantics about entities, and their relationship with neighboring entities in knowledge graphs. We propose a novel and effective technique to infuse knowledge context from knowledge graphs for conceptual and ambiguous entities into models based on transformer architecture. Our novel technique project knowledge graph embedding in the homogeneous vector-space, introduces new token-types for entities, align entity position ids, and a selective attention mechanism. We take BERT as a baseline model and implement "KnowledgeInfused BERT" by infusing knowledge context from ConceptNet and WordNet, which significantly outperforms BERT over a wide range of NLP tasks over eight different GLUE datasets. KI-BERT-base model even outperforms BERT-large for domain-specific tasks like SciTail and academic subsets of QQP, QNLI, and MNLI.