 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMTM: Multi-Tasking Multi-Decoder Transformer for Math Word Problems
Jun 02, 2022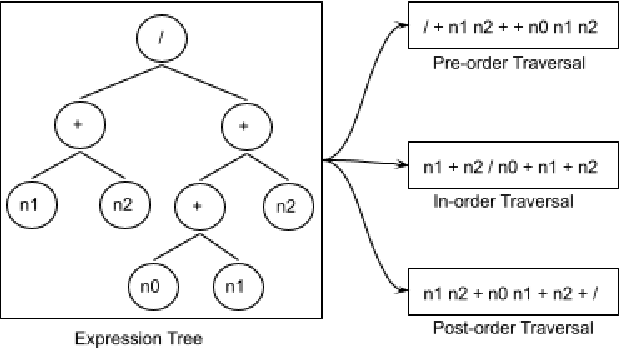
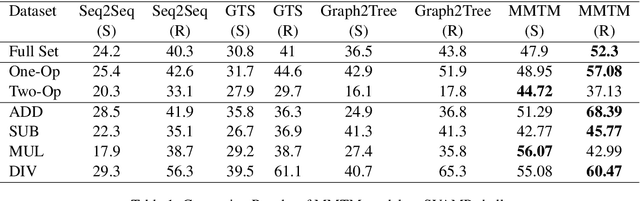
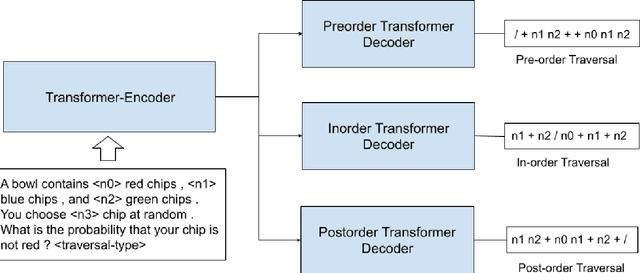

Recently, quite a few novel neural architectures were derived to solve math word problems by predicting expression trees. These architectures varied from seq2seq models, including encoders leveraging graph relationships combined with tree decoders. These models achieve good performance on various MWPs datasets but perform poorly when applied to an adversarial challenge dataset, SVAMP. We present a novel model MMTM that leverages multi-tasking and multi-decoder during pre-training. It creates variant tasks by deriving labels using pre-order, in-order and post-order traversal of expression trees, and uses task-specific decoders in a multi-tasking framework. We leverage transformer architectures with lower dimensionality and initialize weights from RoBERTa model. MMTM model achieves better mathematical reasoning ability and generalisability, which we demonstrate by outperforming the best state of the art baseline models from Seq2Seq, GTS, and Graph2Tree with a relative improvement of 19.4% on an adversarial challenge dataset SVAMP.
Towards Tractable Mathematical Reasoning: Challenges, Strategies, and Opportunities for Solving Math Word Problems
Oct 29, 2021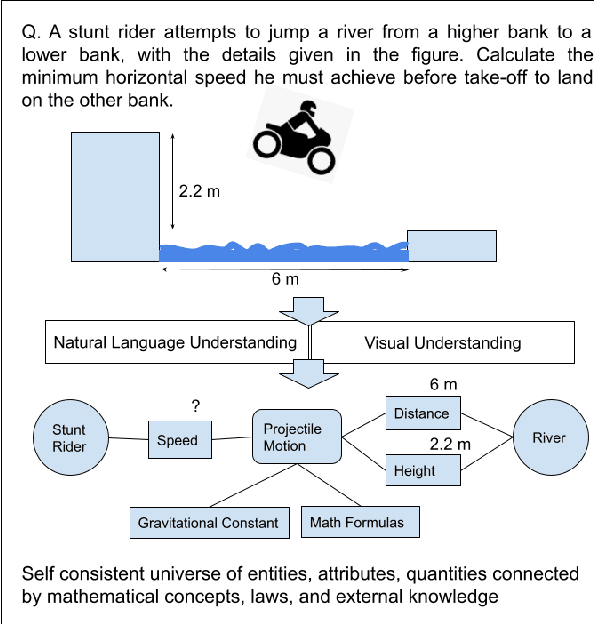

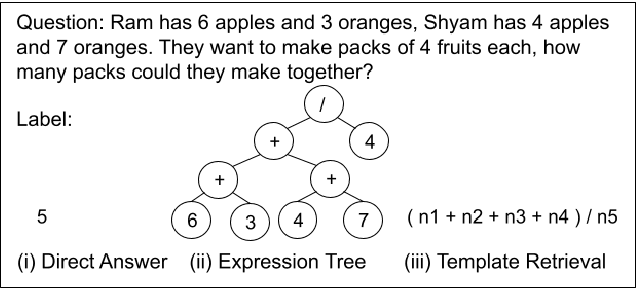
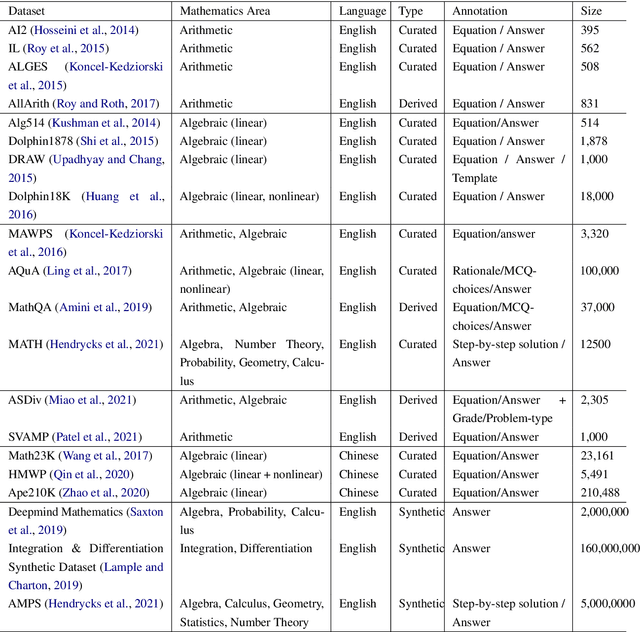
Mathematical reasoning would be one of the next frontiers for artificial intelligence to make significant progress. The ongoing surge to solve math word problems (MWPs) and hence achieve better mathematical reasoning ability would continue to be a key line of research in the coming time. We inspect non-neural and neural methods to solve math word problems narrated in a natural language. We also highlight the ability of these methods to be generalizable, mathematically reasonable, interpretable, and explainable. Neural approaches dominate the current state of the art, and we survey them highlighting three strategies to MWP solving: (1) direct answer generation, (2) expression tree generation for inferring answers, and (3) template retrieval for answer computation. Moreover, we discuss technological approaches, review the evolution of intuitive design choices to solve MWPs, and examine them for mathematical reasoning ability. We finally identify several gaps that warrant the need for external knowledge and knowledge-infused learning, among several other opportunities in solving MWPs.
KI-BERT: Infusing Knowledge Context for Better Language and Domain Understanding
Apr 09, 2021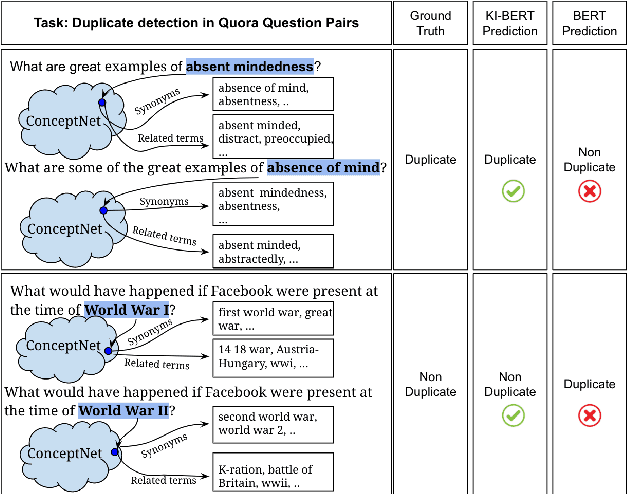
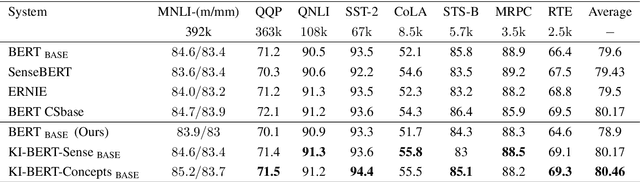
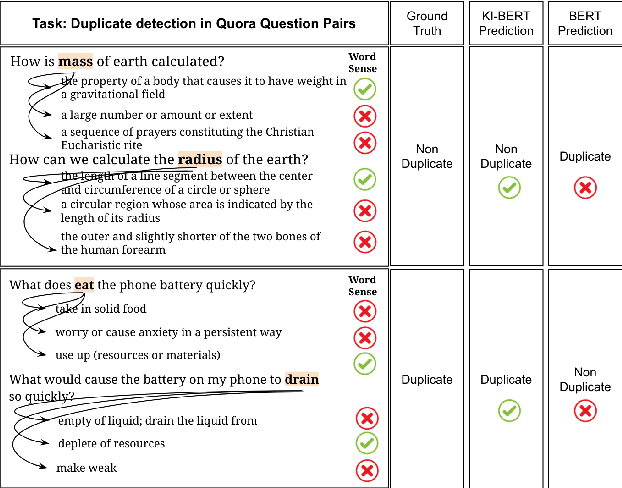

Contextualized entity representations learned by state-of-the-art deep learning models (BERT, GPT, T5, etc) leverage the attention mechanism to learn the data context. However, these models are still blind to leverage the knowledge context present in the knowledge graph. Knowledge context can be understood as semantics about entities, and their relationship with neighboring entities in knowledge graphs. We propose a novel and effective technique to infuse knowledge context from knowledge graphs for conceptual and ambiguous entities into models based on transformer architecture. Our novel technique project knowledge graph embedding in the homogeneous vector-space, introduces new token-types for entities, align entity position ids, and a selective attention mechanism. We take BERT as a baseline model and implement "KnowledgeInfused BERT" by infusing knowledge context from ConceptNet and WordNet, which significantly outperforms BERT over a wide range of NLP tasks over eight different GLUE datasets. KI-BERT-base model even outperforms BERT-large for domain-specific tasks like SciTail and academic subsets of QQP, QNLI, and MNLI.