 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeoneDAL Optimization for ARM Scalable Vector Extension: Maximizing Efficiency for High-Performance Data Science
Apr 05, 2025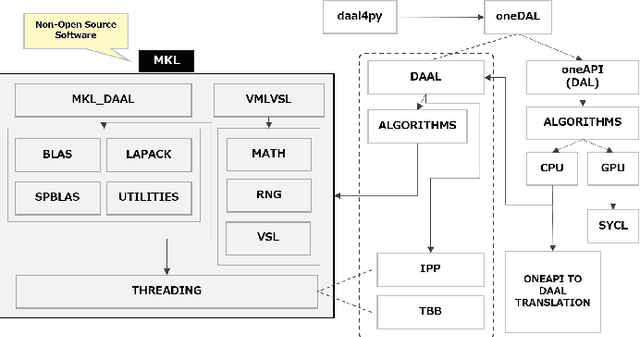
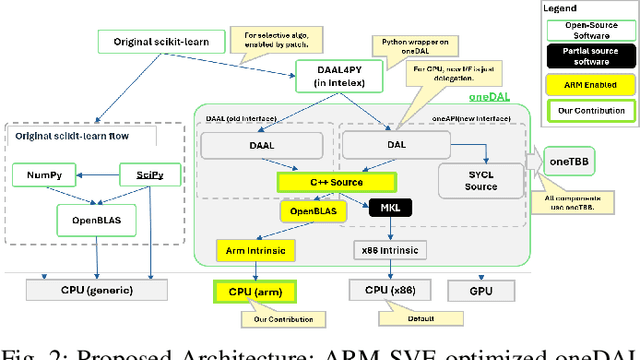

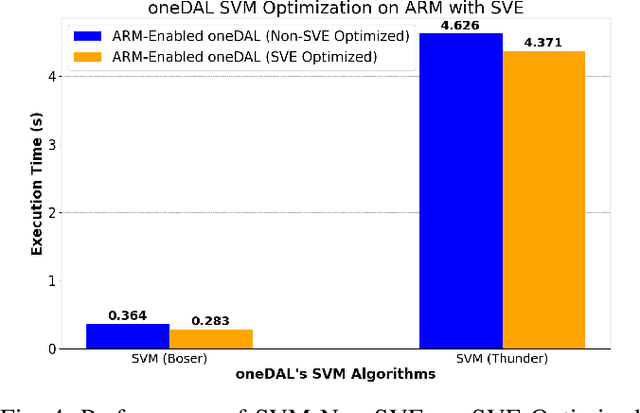
The evolution of ARM-based architectures, particularly those incorporating Scalable Vector Extension (SVE), has introduced transformative opportunities for high-performance computing (HPC) and machine learning (ML) workloads. The Unified Acceleration Foundation's (UXL) oneAPI Data Analytics Library (oneDAL) is a widely adopted library for accelerating ML and data analytics workflows, but its reliance on Intel's proprietary Math Kernel Library (MKL) has traditionally limited its compatibility to x86platforms. This paper details the porting of oneDAL to ARM architectures with SVE support, using OpenBLAS as an alternative backend to overcome architectural and performance challenges. Beyond porting, the research introduces novel ARM-specific optimizations, including custom sparse matrix routines, vectorized statistical functions, and a Scalable Vector Extension (SVE)-optimized Support Vector Machine (SVM) algorithm. The SVM enhancements leverage SVE's flexible vector lengths and predicate driven execution, achieving notable performance gains of 22% for the Boser method and 5% for the Thunder method. Benchmarks conducted on ARM SVE-enabled AWSGraviton3 instances showcase up to 200x acceleration in ML training and inference tasks compared to the original scikit-learn implementation on the ARM platform. Moreover, the ARM-optimized oneDAL achieves performance parity with, and in some cases exceeds, the x86 oneDAL implementation (MKL backend) on IceLake x86 systems, which are nearly twice as costly as AWSGraviton3 ARM instances. These findings highlight ARM's potential as a high-performance, energyefficient platform for dataintensive ML applications. By expanding cross-architecture compatibility and contributing to the opensource ecosystem, this work reinforces ARM's position as a competitive alternative in the HPC and ML domains, paving the way for future advancements in dataintensive computing.
MMTM: Multi-Tasking Multi-Decoder Transformer for Math Word Problems
Jun 02, 2022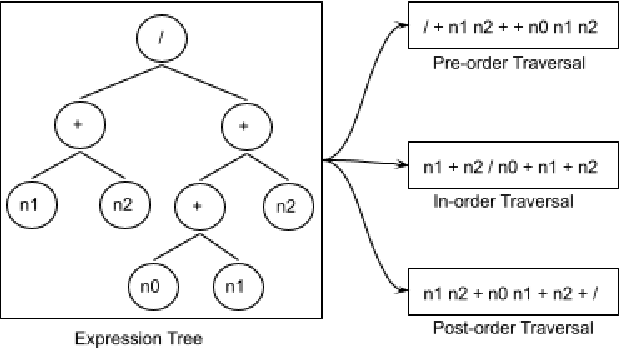
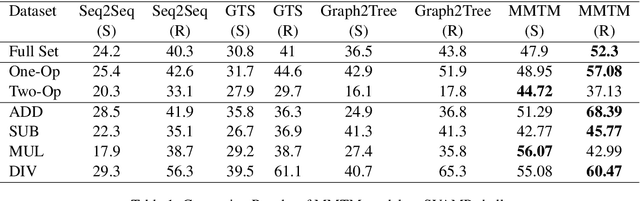
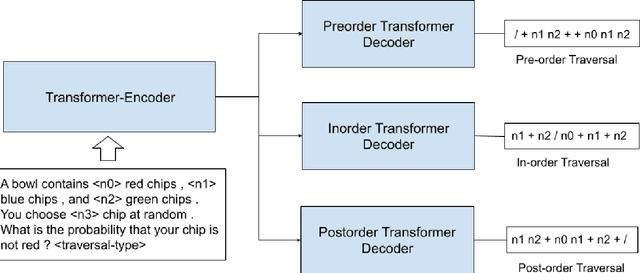

Recently, quite a few novel neural architectures were derived to solve math word problems by predicting expression trees. These architectures varied from seq2seq models, including encoders leveraging graph relationships combined with tree decoders. These models achieve good performance on various MWPs datasets but perform poorly when applied to an adversarial challenge dataset, SVAMP. We present a novel model MMTM that leverages multi-tasking and multi-decoder during pre-training. It creates variant tasks by deriving labels using pre-order, in-order and post-order traversal of expression trees, and uses task-specific decoders in a multi-tasking framework. We leverage transformer architectures with lower dimensionality and initialize weights from RoBERTa model. MMTM model achieves better mathematical reasoning ability and generalisability, which we demonstrate by outperforming the best state of the art baseline models from Seq2Seq, GTS, and Graph2Tree with a relative improvement of 19.4% on an adversarial challenge dataset SVAMP.