 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeoneDAL Optimization for ARM Scalable Vector Extension: Maximizing Efficiency for High-Performance Data Science
Apr 05, 2025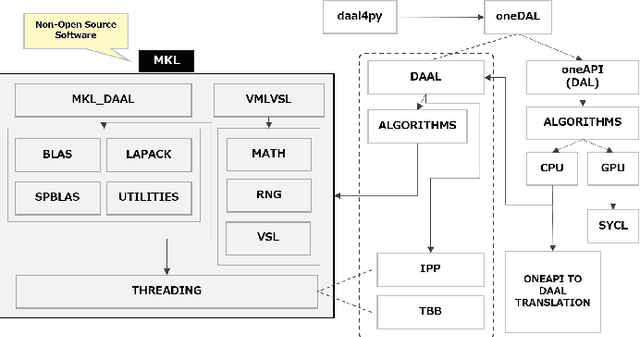
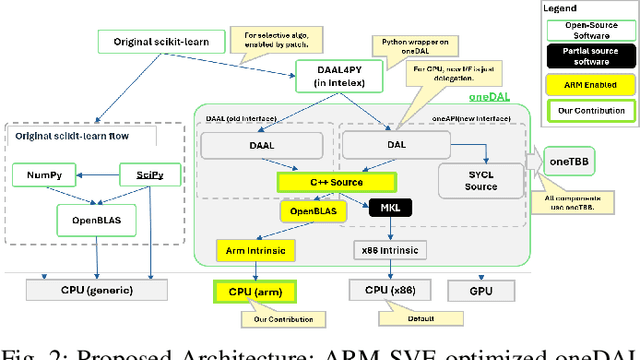

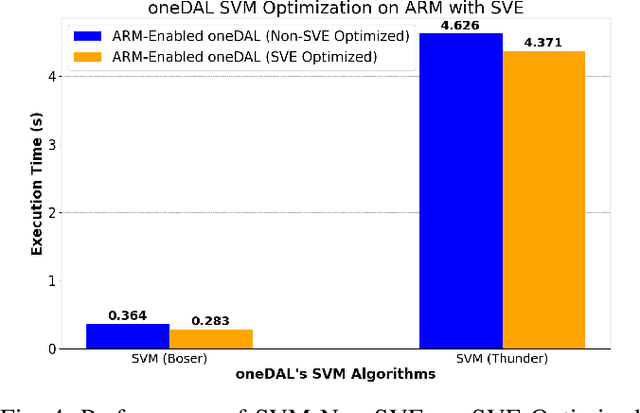
The evolution of ARM-based architectures, particularly those incorporating Scalable Vector Extension (SVE), has introduced transformative opportunities for high-performance computing (HPC) and machine learning (ML) workloads. The Unified Acceleration Foundation's (UXL) oneAPI Data Analytics Library (oneDAL) is a widely adopted library for accelerating ML and data analytics workflows, but its reliance on Intel's proprietary Math Kernel Library (MKL) has traditionally limited its compatibility to x86platforms. This paper details the porting of oneDAL to ARM architectures with SVE support, using OpenBLAS as an alternative backend to overcome architectural and performance challenges. Beyond porting, the research introduces novel ARM-specific optimizations, including custom sparse matrix routines, vectorized statistical functions, and a Scalable Vector Extension (SVE)-optimized Support Vector Machine (SVM) algorithm. The SVM enhancements leverage SVE's flexible vector lengths and predicate driven execution, achieving notable performance gains of 22% for the Boser method and 5% for the Thunder method. Benchmarks conducted on ARM SVE-enabled AWSGraviton3 instances showcase up to 200x acceleration in ML training and inference tasks compared to the original scikit-learn implementation on the ARM platform. Moreover, the ARM-optimized oneDAL achieves performance parity with, and in some cases exceeds, the x86 oneDAL implementation (MKL backend) on IceLake x86 systems, which are nearly twice as costly as AWSGraviton3 ARM instances. These findings highlight ARM's potential as a high-performance, energyefficient platform for dataintensive ML applications. By expanding cross-architecture compatibility and contributing to the opensource ecosystem, this work reinforces ARM's position as a competitive alternative in the HPC and ML domains, paving the way for future advancements in dataintensive computing.
Using LSTM for the Prediction of Disruption in ADITYA Tokamak
Jul 13, 2020
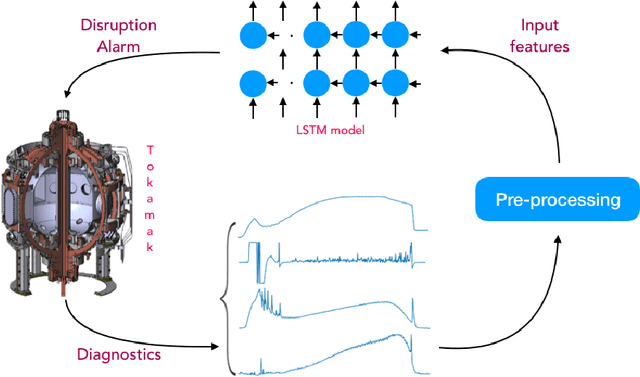
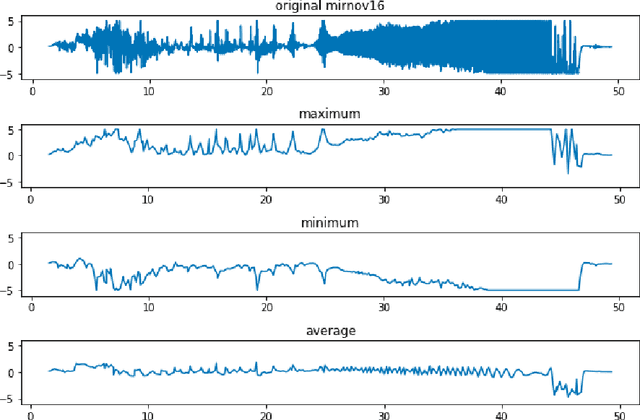
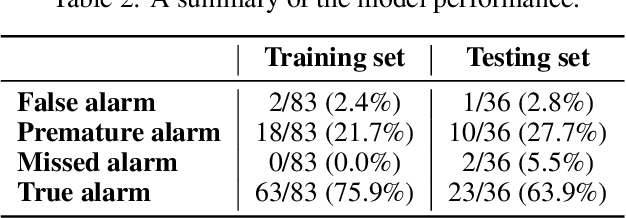
Major disruptions in tokamak pose a serious threat to the vessel and its surrounding pieces of equipment. The ability of the systems to detect any behavior that can lead to disruption can help in alerting the system beforehand and prevent its harmful effects. Many machine learning techniques have already been in use at large tokamaks like JET and ASDEX, but are not suitable for ADITYA, which is comparatively small. Through this work, we discuss a new real-time approach to predict the time of disruption in ADITYA tokamak and validate the results on an experimental dataset. The system uses selected diagnostics from the tokamak and after some pre-processing steps, sends them to a time-sequence Long Short-Term Memory (LSTM) network. The model can make the predictions 12 ms in advance at less computation cost that is quick enough to be deployed in real-time applications.
Virtual SAR: A Synthetic Dataset for Deep Learning based Speckle Noise Reduction Algorithms
Apr 23, 2020


Synthetic Aperture Radar (SAR) images contain a huge amount of information, however, the number of practical use-cases is limited due to the presence of speckle noise in them. In recent years, deep learning based techniques have brought significant improvement in the domain of denoising and image restoration. However, further research has been hampered by the lack of availability of data suitable for training deep neural network based systems. With this paper, we propose a standard way of generating synthetic data for the training of speckle reduction algorithms and demonstrate a use-case to advance research in this domain.