 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoGPA: Distilling Geometry Priors for 3D-Consistent Video Generation
Jan 30, 2026While recent video diffusion models (VDMs) produce visually impressive results, they fundamentally struggle to maintain 3D structural consistency, often resulting in object deformation or spatial drift. We hypothesize that these failures arise because standard denoising objectives lack explicit incentives for geometric coherence. To address this, we introduce VideoGPA (Video Geometric Preference Alignment), a data-efficient self-supervised framework that leverages a geometry foundation model to automatically derive dense preference signals that guide VDMs via Direct Preference Optimization (DPO). This approach effectively steers the generative distribution toward inherent 3D consistency without requiring human annotations. VideoGPA significantly enhances temporal stability, physical plausibility, and motion coherence using minimal preference pairs, consistently outperforming state-of-the-art baselines in extensive experiments.
Fighting Fires from Space: Leveraging Vision Transformers for Enhanced Wildfire Detection and Characterization
Apr 18, 2025Wildfires are increasing in intensity, frequency, and duration across large parts of the world as a result of anthropogenic climate change. Modern hazard detection and response systems that deal with wildfires are under-equipped for sustained wildfire seasons. Recent work has proved automated wildfire detection using Convolutional Neural Networks (CNNs) trained on satellite imagery are capable of high-accuracy results. However, CNNs are computationally expensive to train and only incorporate local image context. Recently, Vision Transformers (ViTs) have gained popularity for their efficient training and their ability to include both local and global contextual information. In this work, we show that ViT can outperform well-trained and specialized CNNs to detect wildfires on a previously published dataset of LandSat-8 imagery. One of our ViTs outperforms the baseline CNN comparison by 0.92%. However, we find our own implementation of CNN-based UNet to perform best in every category, showing their sustained utility in image tasks. Overall, ViTs are comparably capable in detecting wildfires as CNNs, though well-tuned CNNs are still the best technique for detecting wildfire with our UNet providing an IoU of 93.58%, better than the baseline UNet by some 4.58%.
Explain to me like I am five -- Sentence Simplification Using Transformers
Dec 08, 2022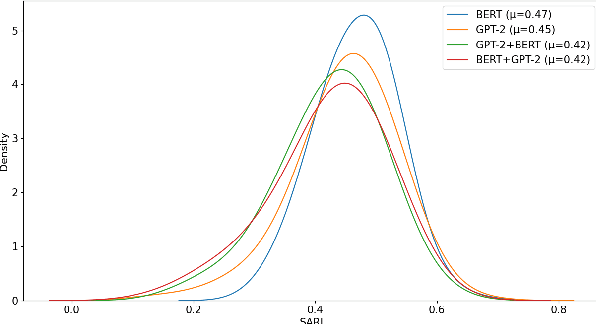

Sentence simplification aims at making the structure of text easier to read and understand while maintaining its original meaning. This can be helpful for people with disabilities, new language learners, or those with low literacy. Simplification often involves removing difficult words and rephrasing the sentence. Previous research have focused on tackling this task by either using external linguistic databases for simplification or by using control tokens for desired fine-tuning of sentences. However, in this paper we purely use pre-trained transformer models. We experiment with a combination of GPT-2 and BERT models, achieving the best SARI score of 46.80 on the Mechanical Turk dataset, which is significantly better than previous state-of-the-art results. The code can be found at https://github.com/amanbasu/sentence-simplification.
Using LSTM for the Prediction of Disruption in ADITYA Tokamak
Jul 13, 2020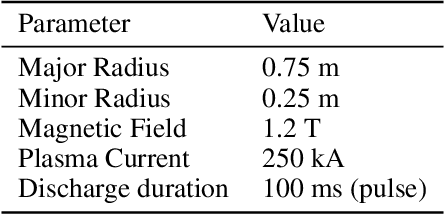
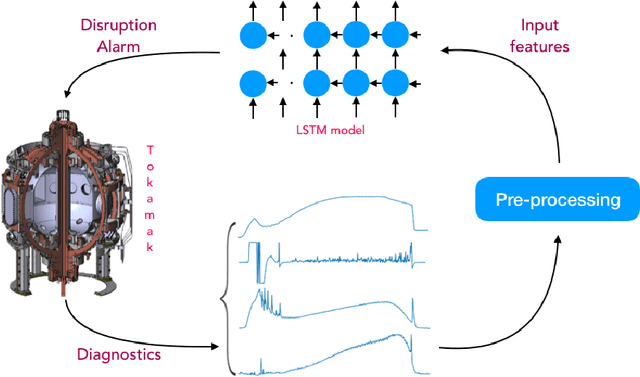
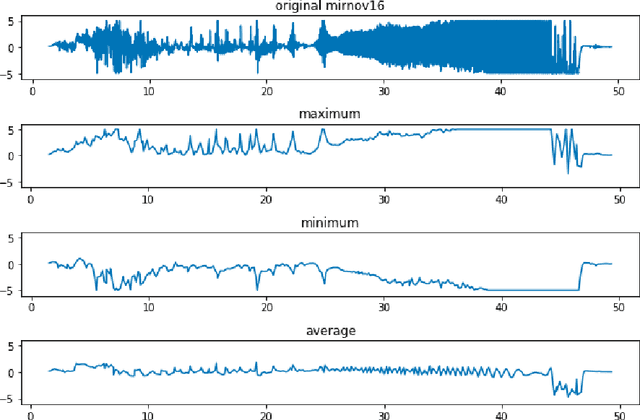
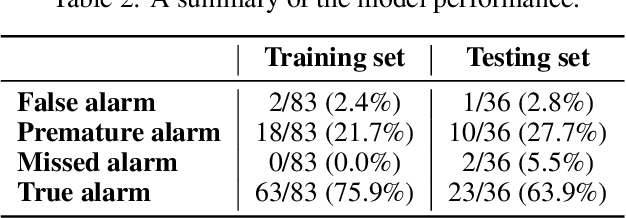
Major disruptions in tokamak pose a serious threat to the vessel and its surrounding pieces of equipment. The ability of the systems to detect any behavior that can lead to disruption can help in alerting the system beforehand and prevent its harmful effects. Many machine learning techniques have already been in use at large tokamaks like JET and ASDEX, but are not suitable for ADITYA, which is comparatively small. Through this work, we discuss a new real-time approach to predict the time of disruption in ADITYA tokamak and validate the results on an experimental dataset. The system uses selected diagnostics from the tokamak and after some pre-processing steps, sends them to a time-sequence Long Short-Term Memory (LSTM) network. The model can make the predictions 12 ms in advance at less computation cost that is quick enough to be deployed in real-time applications.
Counterfactual Learning-to-Rank for Additive Metrics and Deep Models
Jun 22, 2018
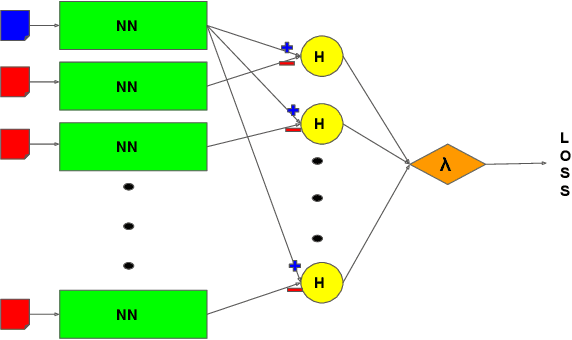

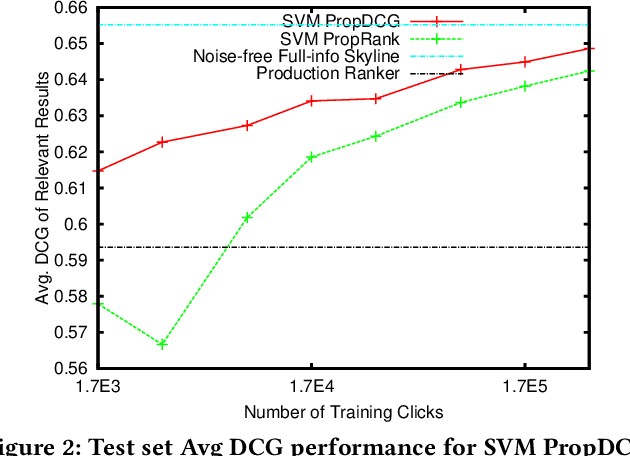
Implicit feedback (e.g., clicks, dwell times) is an attractive source of training data for Learning-to-Rank, but it inevitably suffers from biases such as position bias. It was recently shown how counterfactual inference techniques can provide a rigorous approach for handling these biases, but existing methods are restricted to the special case of optimizing average rank for linear ranking functions. In this work, we generalize the counterfactual learning-to-rank approach to a broad class of additive rank metrics -- like Discounted Cumulative Gain (DCG) and Precision@k -- as well as non-linear deep network models. Focusing on DCG, this conceptual generalization gives rise to two new learning methods that both directly optimize an unbiased estimate of DCG despite the bias in the implicit feedback data. The first, SVM PropDCG, generalizes the Propensity Ranking SVM (SVM PropRank), and we show how the resulting optimization problem can be addressed via the Convex Concave Procedure (CCP). The second, Deep PropDCG, further generalizes the counterfactual learning-to-rank approach to deep networks as non-linear ranking functions. In addition to the theoretical support, we empirically find that SVM PropDCG significantly outperforms SVM PropRank in terms of DCG, and that it is robust to varying severity of presentation bias, noise, and propensity-model misspecification. Moreover, the ability to train non-linear ranking functions via Deep PropDCG further improves DCG.
Consistent Position Bias Estimation without Online Interventions for Learning-to-Rank
Jun 09, 2018
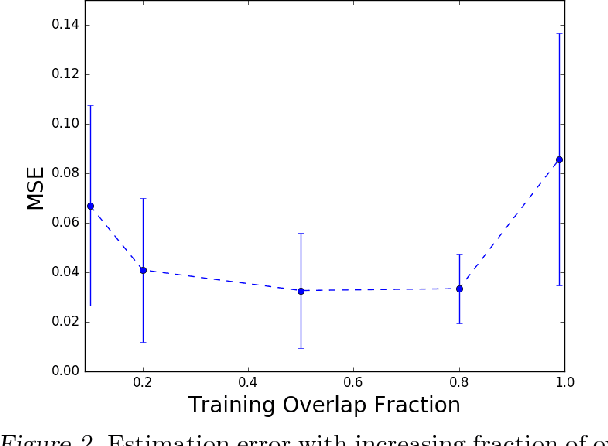
Presentation bias is one of the key challenges when learning from implicit feedback in search engines, as it confounds the relevance signal with uninformative signals due to position in the ranking, saliency, and other presentation factors. While it was recently shown how counterfactual learning-to-rank (LTR) approaches \cite{Joachims/etal/17a} can provably overcome presentation bias if observation propensities are known, it remains to show how to accurately estimate these propensities. In this paper, we propose the first method for producing consistent propensity estimates without manual relevance judgments, disruptive interventions, or restrictive relevance modeling assumptions. We merely require that we have implicit feedback data from multiple different ranking functions. Furthermore, we argue that our estimation technique applies to an extended class of Contextual Position-Based Propensity Models, where propensities not only depend on position but also on observable features of the query and document. Initial simulation studies confirm that the approach is scalable, accurate, and robust.
Effective Evaluation using Logged Bandit Feedback from Multiple Loggers
Jun 26, 2017


Accurately evaluating new policies (e.g. ad-placement models, ranking functions, recommendation functions) is one of the key prerequisites for improving interactive systems. While the conventional approach to evaluation relies on online A/B tests, recent work has shown that counterfactual estimators can provide an inexpensive and fast alternative, since they can be applied offline using log data that was collected from a different policy fielded in the past. In this paper, we address the question of how to estimate the performance of a new target policy when we have log data from multiple historic policies. This question is of great relevance in practice, since policies get updated frequently in most online systems. We show that naively combining data from multiple logging policies can be highly suboptimal. In particular, we find that the standard Inverse Propensity Score (IPS) estimator suffers especially when logging and target policies diverge -- to a point where throwing away data improves the variance of the estimator. We therefore propose two alternative estimators which we characterize theoretically and compare experimentally. We find that the new estimators can provide substantially improved estimation accuracy.