 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeterministic and probabilistic neural surrogates of global hybrid-Vlasov simulations
Jan 21, 2026Hybrid-Vlasov simulations resolve ion-kinetic effects for modeling the solar wind-magnetosphere interaction, but even 5D (2D + 3V) simulations are computationally expensive. We show that graph-based machine learning emulators can learn the spatiotemporal evolution of electromagnetic fields and lower order moments of ion velocity distribution in the near-Earth space environment from four 5D Vlasiator runs performed with identical steady solar wind conditions. The initial ion number density is systematically varied, while the grid spacing is held constant, to scan the ratio of the characteristic ion skin depth to the numerical grid size. Using a graph neural network architecture operating on the 2D spatial simulation grid comprising 670k cells, we demonstrate that both a deterministic forecasting model (Graph-FM) and a probabilistic ensemble forecasting model (Graph-EFM) based on a latent variable formulation are capable of producing accurate predictions of future plasma states. A divergence penalty is incorporated during training to encourage divergence-freeness in the magnetic fields and improve physical consistency. For the probabilistic model, a continuous ranked probability score objective is added to improve the calibration of the ensemble forecasts. When trained, the emulators achieve more than two orders of magnitude speedup in generating the next time step relative to the original simulation on a single GPU compared to 100 CPUs for the Vlasiator runs, while closely matching physical magnetospheric response of the different runs. These results demonstrate that machine learning offers a way to make hybrid-Vlasov simulation tractable for real-time use while providing forecast uncertainty.
Graph Representation of the Magnetic Field Topology in High-Fidelity Plasma Simulations for Machine Learning Applications
Jul 26, 2023Topological analysis of the magnetic field in simulated plasmas allows the study of various physical phenomena in a wide range of settings. One such application is magnetic reconnection, a phenomenon related to the dynamics of the magnetic field topology, which is difficult to detect and characterize in three dimensions. We propose a scalable pipeline for topological data analysis and spatiotemporal graph representation of three-dimensional magnetic vector fields. We demonstrate our methods on simulations of the Earth's magnetosphere produced by Vlasiator, a supercomputer-scale Vlasov theory-based simulation for near-Earth space. The purpose of this work is to challenge the machine learning community to explore graph-based machine learning approaches to address a largely open scientific problem with wide-ranging potential impact.
Counterfactual Learning-to-Rank for Additive Metrics and Deep Models
Jun 22, 2018
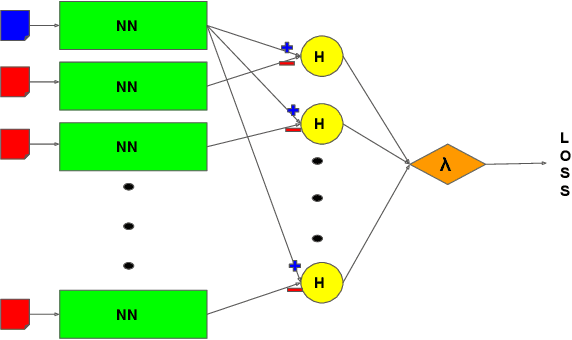

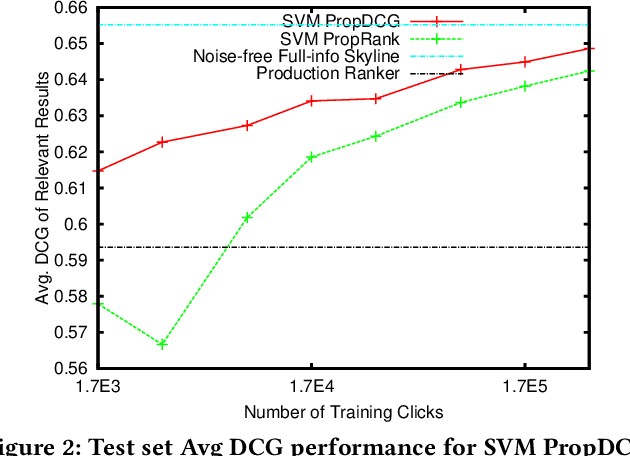
Implicit feedback (e.g., clicks, dwell times) is an attractive source of training data for Learning-to-Rank, but it inevitably suffers from biases such as position bias. It was recently shown how counterfactual inference techniques can provide a rigorous approach for handling these biases, but existing methods are restricted to the special case of optimizing average rank for linear ranking functions. In this work, we generalize the counterfactual learning-to-rank approach to a broad class of additive rank metrics -- like Discounted Cumulative Gain (DCG) and Precision@k -- as well as non-linear deep network models. Focusing on DCG, this conceptual generalization gives rise to two new learning methods that both directly optimize an unbiased estimate of DCG despite the bias in the implicit feedback data. The first, SVM PropDCG, generalizes the Propensity Ranking SVM (SVM PropRank), and we show how the resulting optimization problem can be addressed via the Convex Concave Procedure (CCP). The second, Deep PropDCG, further generalizes the counterfactual learning-to-rank approach to deep networks as non-linear ranking functions. In addition to the theoretical support, we empirically find that SVM PropDCG significantly outperforms SVM PropRank in terms of DCG, and that it is robust to varying severity of presentation bias, noise, and propensity-model misspecification. Moreover, the ability to train non-linear ranking functions via Deep PropDCG further improves DCG.
Consistent Position Bias Estimation without Online Interventions for Learning-to-Rank
Jun 09, 2018
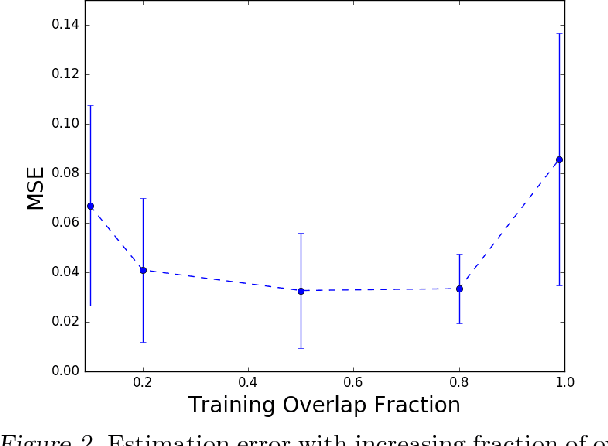
Presentation bias is one of the key challenges when learning from implicit feedback in search engines, as it confounds the relevance signal with uninformative signals due to position in the ranking, saliency, and other presentation factors. While it was recently shown how counterfactual learning-to-rank (LTR) approaches \cite{Joachims/etal/17a} can provably overcome presentation bias if observation propensities are known, it remains to show how to accurately estimate these propensities. In this paper, we propose the first method for producing consistent propensity estimates without manual relevance judgments, disruptive interventions, or restrictive relevance modeling assumptions. We merely require that we have implicit feedback data from multiple different ranking functions. Furthermore, we argue that our estimation technique applies to an extended class of Contextual Position-Based Propensity Models, where propensities not only depend on position but also on observable features of the query and document. Initial simulation studies confirm that the approach is scalable, accurate, and robust.