 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMTM: Multi-Tasking Multi-Decoder Transformer for Math Word Problems
Paper and Code
Jun 02, 2022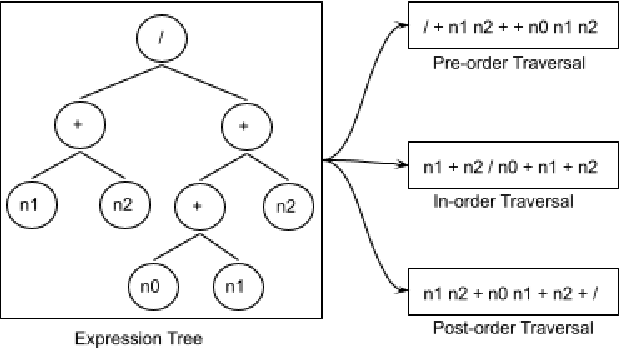
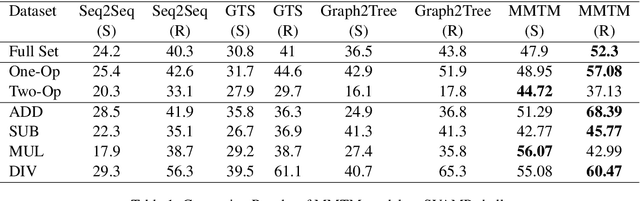
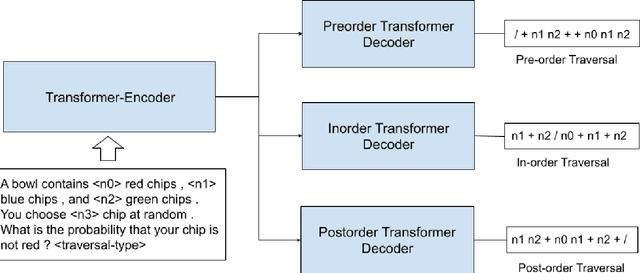

Recently, quite a few novel neural architectures were derived to solve math word problems by predicting expression trees. These architectures varied from seq2seq models, including encoders leveraging graph relationships combined with tree decoders. These models achieve good performance on various MWPs datasets but perform poorly when applied to an adversarial challenge dataset, SVAMP. We present a novel model MMTM that leverages multi-tasking and multi-decoder during pre-training. It creates variant tasks by deriving labels using pre-order, in-order and post-order traversal of expression trees, and uses task-specific decoders in a multi-tasking framework. We leverage transformer architectures with lower dimensionality and initialize weights from RoBERTa model. MMTM model achieves better mathematical reasoning ability and generalisability, which we demonstrate by outperforming the best state of the art baseline models from Seq2Seq, GTS, and Graph2Tree with a relative improvement of 19.4% on an adversarial challenge dataset SVAMP.