 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA framework for predicting, interpreting, and improving Learning Outcomes
Oct 12, 2020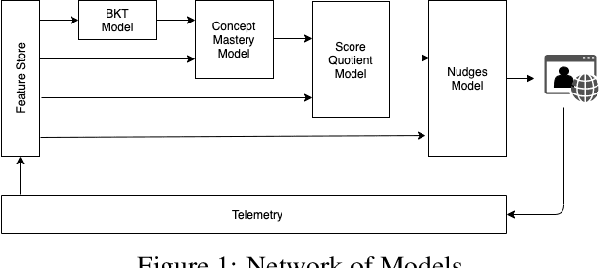

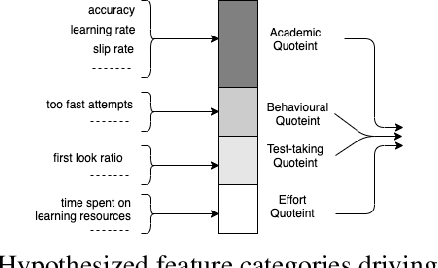
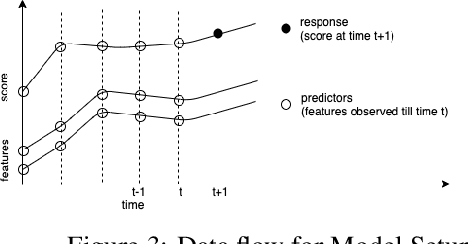
It has long been recognized that academic success is a result of both cognitive and non-cognitive dimensions acting together. Consequently, any intelligent learning platform designed to improve learning outcomes (LOs) must provide actionable inputs to the learner in these dimensions. However, operationalizing such inputs in a production setting that is scalable is not trivial. We develop an Embibe Score Quotient model (ESQ) to predict test scores based on observed academic, behavioral and test-taking features of a student. ESQ can be used to predict the future scoring potential of a student as well as offer personalized learning nudges, both critical to improving LOs. Multiple machine learning models are evaluated for the prediction task. In order to provide meaningful feedback to the learner, individualized Shapley feature attributions for each feature are computed. Prediction intervals are obtained by applying non-parametric quantile regression, in an attempt to quantify the uncertainty in the predictions. We apply the above modelling strategy on a dataset consisting of more than a hundred million learner interactions on the Embibe learning platform. We observe that the Median Absolute Error between the observed and predicted scores is 4.58% across several user segments, and the correlation between predicted and observed responses is 0.93. Game-like what-if scenarios are played out to see the changes in LOs, on counterfactual examples. We briefly discuss how a rational agent can then apply an optimal policy to affect the learning outcomes by treating the above model like an Oracle.
Selecting Biomarkers for building optimal treatment selection rules using Kernel Machines
Jun 06, 2019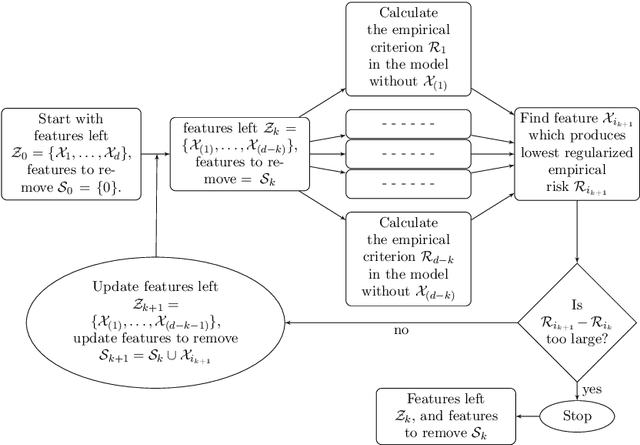
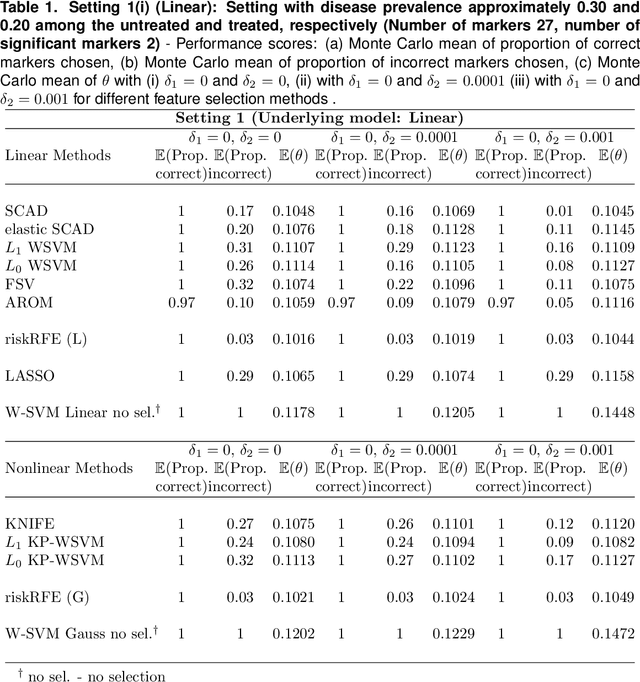
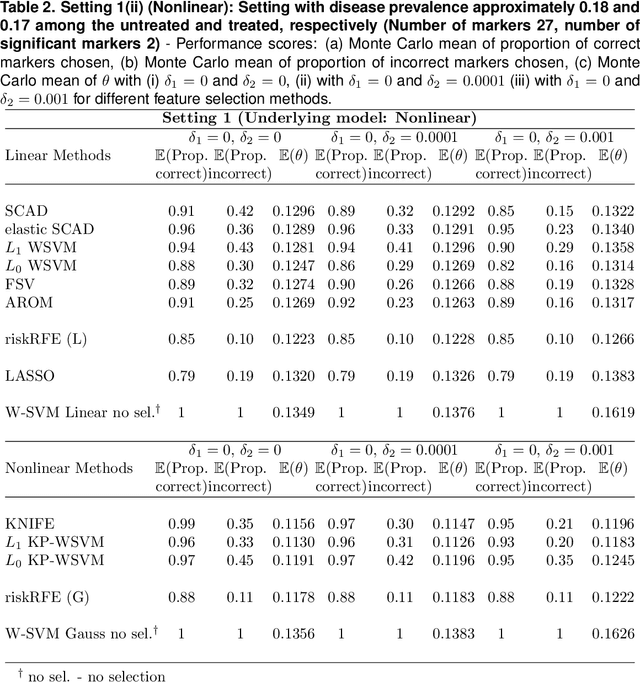

Optimal biomarker combinations for treatment-selection can be derived by minimizing total burden to the population caused by the targeted disease and its treatment. However, when multiple biomarkers are present, including all in the model can be expensive and hurt model performance. To remedy this, we consider feature selection in optimization by minimizing an extended total burden that additionally incorporates biomarker measurement costs. Formulating it as a 0-norm penalized weighted classification, we develop various procedures for estimating linear and nonlinear combinations. Through simulations and a real data example, we demonstrate the importance of incorporating feature-selection and marker cost when deriving treatment-selection rules.
Feature Elimination in Kernel Machines in moderately high dimensions
Dec 24, 2015
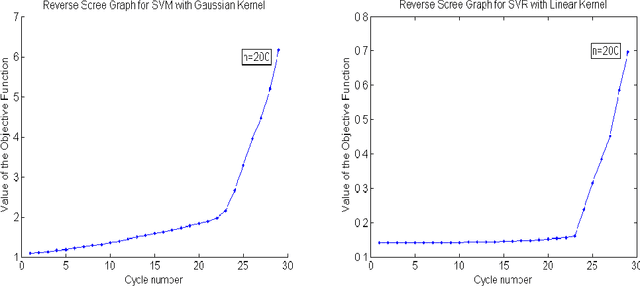
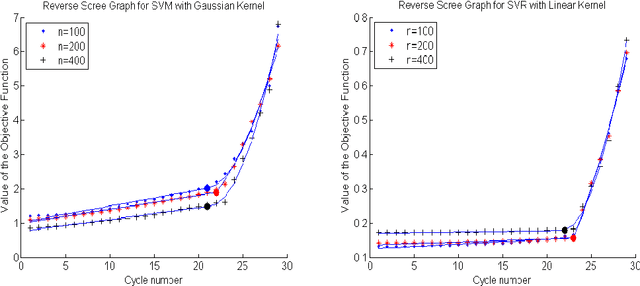
We develop an approach for feature elimination in statistical learning with kernel machines, based on recursive elimination of features.We present theoretical properties of this method and show that it is uniformly consistent in finding the correct feature space under certain generalized assumptions.We present four case studies to show that the assumptions are met in most practical situations and present simulation results to demonstrate performance of the proposed approach.