 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealth Sentinel: An AI Pipeline For Real-time Disease Outbreak Detection
Jun 24, 2025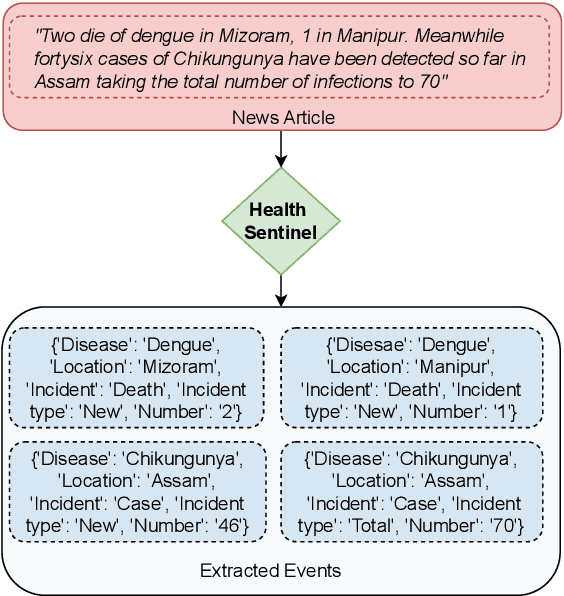
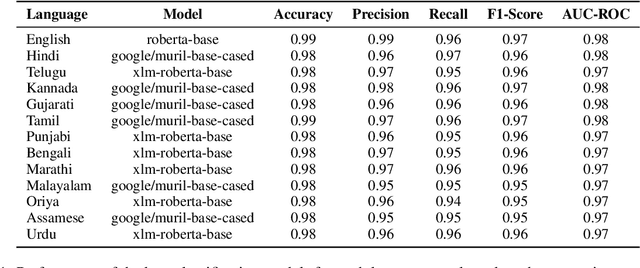
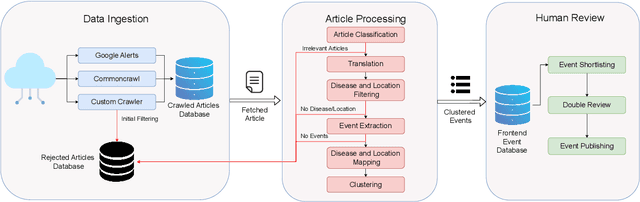
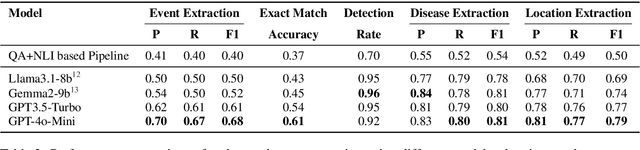
Early detection of disease outbreaks is crucial to ensure timely intervention by the health authorities. Due to the challenges associated with traditional indicator-based surveillance, monitoring informal sources such as online media has become increasingly popular. However, owing to the number of online articles getting published everyday, manual screening of the articles is impractical. To address this, we propose Health Sentinel. It is a multi-stage information extraction pipeline that uses a combination of ML and non-ML methods to extract events-structured information concerning disease outbreaks or other unusual health events-from online articles. The extracted events are made available to the Media Scanning and Verification Cell (MSVC) at the National Centre for Disease Control (NCDC), Delhi for analysis, interpretation and further dissemination to local agencies for timely intervention. From April 2022 till date, Health Sentinel has processed over 300 million news articles and identified over 95,000 unique health events across India of which over 3,500 events were shortlisted by the public health experts at NCDC as potential outbreaks.
LogGENE: A smooth alternative to check loss for Deep Healthcare Inference Tasks
Jun 19, 2022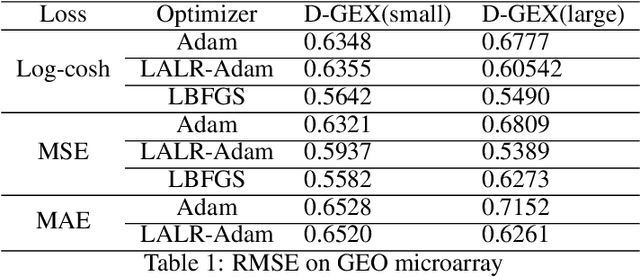
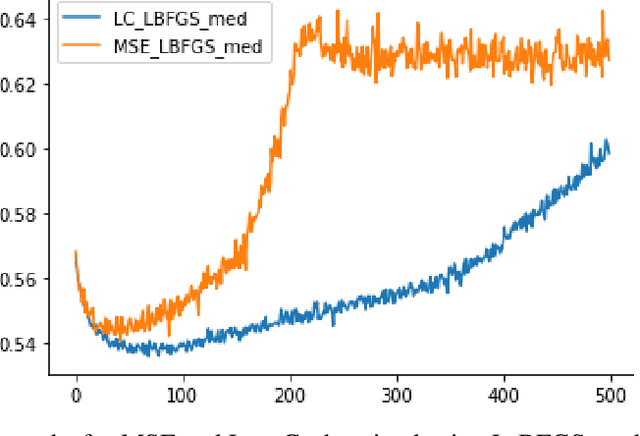


High-throughput Genomics is ushering a new era in personalized health care, and targeted drug design and delivery. Mining these large datasets, and obtaining calibrated predictions is of immediate relevance and utility. In our work, we develop methods for Gene Expression Inference based on Deep neural networks. However, unlike typical Deep learning methods, our inferential technique, while achieving state-of-the-art performance in terms of accuracy, can also provide explanations, and report uncertainty estimates. We adopt the Quantile Regression framework to predict full conditional quantiles for a given set of house keeping gene expressions. Conditional quantiles, in addition to being useful in providing rich interpretations of the predictions, are also robust to measurement noise. However, check loss, used in quantile regression to drive the estimation process is not differentiable. We propose log-cosh as a smooth-alternative to the check loss. We apply our methods on GEO microarray dataset. We also extend the method to binary classification setting. Furthermore, we investigate other consequences of the smoothness of the loss in faster convergence.
A framework for predicting, interpreting, and improving Learning Outcomes
Oct 12, 2020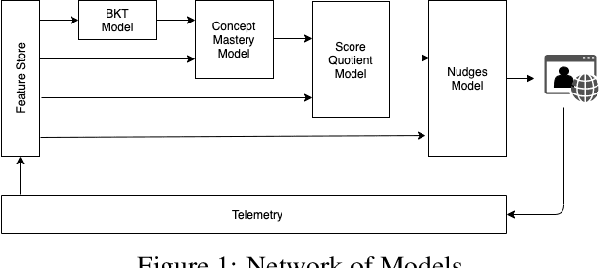

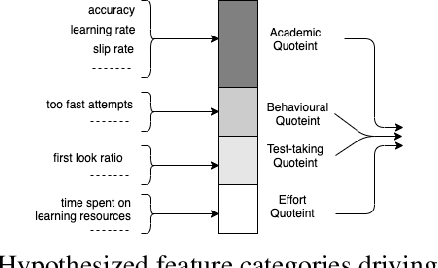
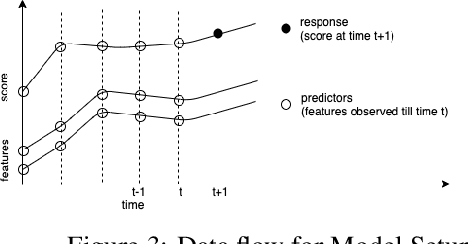
It has long been recognized that academic success is a result of both cognitive and non-cognitive dimensions acting together. Consequently, any intelligent learning platform designed to improve learning outcomes (LOs) must provide actionable inputs to the learner in these dimensions. However, operationalizing such inputs in a production setting that is scalable is not trivial. We develop an Embibe Score Quotient model (ESQ) to predict test scores based on observed academic, behavioral and test-taking features of a student. ESQ can be used to predict the future scoring potential of a student as well as offer personalized learning nudges, both critical to improving LOs. Multiple machine learning models are evaluated for the prediction task. In order to provide meaningful feedback to the learner, individualized Shapley feature attributions for each feature are computed. Prediction intervals are obtained by applying non-parametric quantile regression, in an attempt to quantify the uncertainty in the predictions. We apply the above modelling strategy on a dataset consisting of more than a hundred million learner interactions on the Embibe learning platform. We observe that the Median Absolute Error between the observed and predicted scores is 4.58% across several user segments, and the correlation between predicted and observed responses is 0.93. Game-like what-if scenarios are played out to see the changes in LOs, on counterfactual examples. We briefly discuss how a rational agent can then apply an optimal policy to affect the learning outcomes by treating the above model like an Oracle.