 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRice Plant Disease Detection and Diagnosis using Deep Convolutional Neural Networks and Multispectral Imaging
Sep 11, 2023Rice is considered a strategic crop in Egypt as it is regularly consumed in the Egyptian people's diet. Even though Egypt is the highest rice producer in Africa with a share of 6 million tons per year, it still imports rice to satisfy its local needs due to production loss, especially due to rice disease. Rice blast disease is responsible for 30% loss in rice production worldwide. Therefore, it is crucial to target limiting yield damage by detecting rice crops diseases in its early stages. This paper introduces a public multispectral and RGB images dataset and a deep learning pipeline for rice plant disease detection using multi-modal data. The collected multispectral images consist of Red, Green and Near-Infrared channels and we show that using multispectral along with RGB channels as input archives a higher F1 accuracy compared to using RGB input only.
Predictive models of RNA degradation through dual crowdsourcing
Oct 14, 2021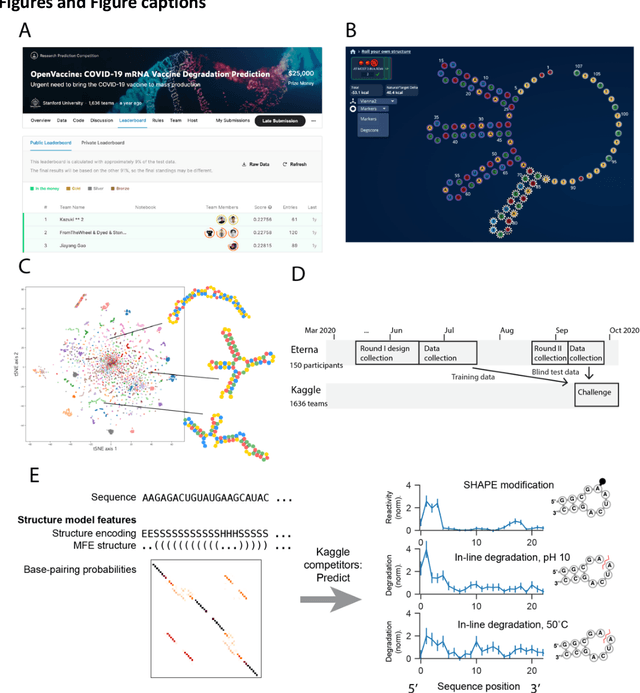
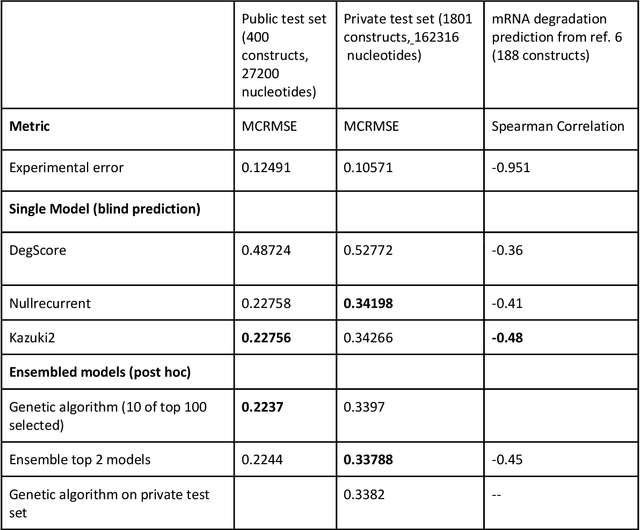
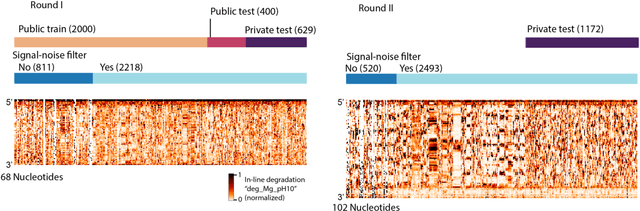
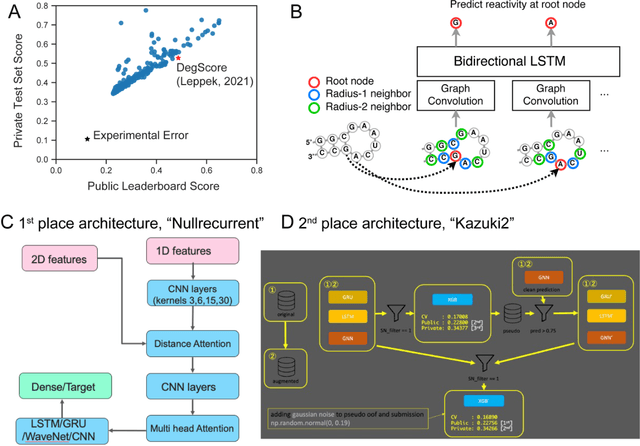
Messenger RNA-based medicines hold immense potential, as evidenced by their rapid deployment as COVID-19 vaccines. However, worldwide distribution of mRNA molecules has been limited by their thermostability, which is fundamentally limited by the intrinsic instability of RNA molecules to a chemical degradation reaction called in-line hydrolysis. Predicting the degradation of an RNA molecule is a key task in designing more stable RNA-based therapeutics. Here, we describe a crowdsourced machine learning competition ("Stanford OpenVaccine") on Kaggle, involving single-nucleotide resolution measurements on 6043 102-130-nucleotide diverse RNA constructs that were themselves solicited through crowdsourcing on the RNA design platform Eterna. The entire experiment was completed in less than 6 months. Winning models demonstrated test set errors that were better by 50% than the previous state-of-the-art DegScore model. Furthermore, these models generalized to blindly predicting orthogonal degradation data on much longer mRNA molecules (504-1588 nucleotides) with improved accuracy over DegScore and other models. Top teams integrated natural language processing architectures and data augmentation techniques with predictions from previous dynamic programming models for RNA secondary structure. These results indicate that such models are capable of representing in-line hydrolysis with excellent accuracy, supporting their use for designing stabilized messenger RNAs. The integration of two crowdsourcing platforms, one for data set creation and another for machine learning, may be fruitful for other urgent problems that demand scientific discovery on rapid timescales.
Robust Real-Time Pedestrian Detection on Embedded Devices
Dec 13, 2020
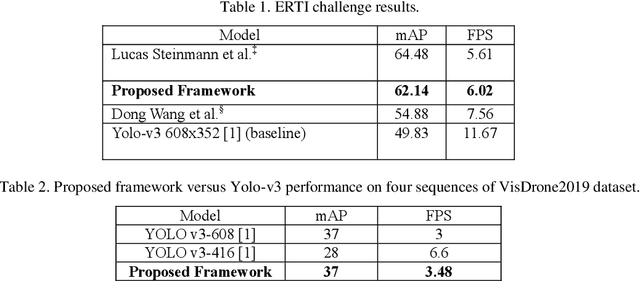
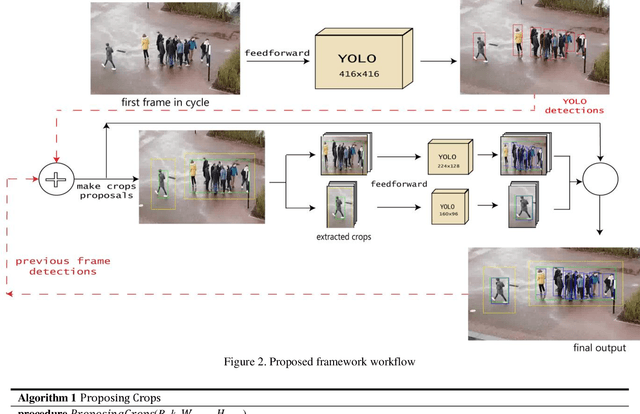

Detection of pedestrians on embedded devices, such as those on-board of robots and drones, has many applications including road intersection monitoring, security, crowd monitoring and surveillance, to name a few. However, the problem can be challenging due to continuously-changing camera viewpoint and varying object appearances as well as the need for lightweight algorithms suitable for embedded systems. This paper proposes a robust framework for pedestrian detection in many footages. The framework performs fine and coarse detections on different image regions and exploits temporal and spatial characteristics to attain enhanced accuracy and real time performance on embedded boards. The framework uses the Yolo-v3 object detection [1] as its backbone detector and runs on the Nvidia Jetson TX2 embedded board, however other detectors and/or boards can be used as well. The performance of the framework is demonstrated on two established datasets and its achievement of the second place in CVPR 2019 Embedded Real-Time Inference (ERTI) Challenge.
Multi Projection Fusion for Real-time Semantic Segmentation of 3D LiDAR Point Clouds
Nov 06, 2020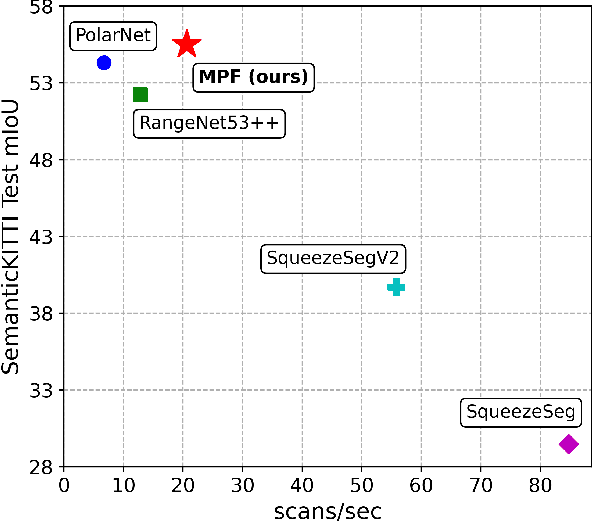

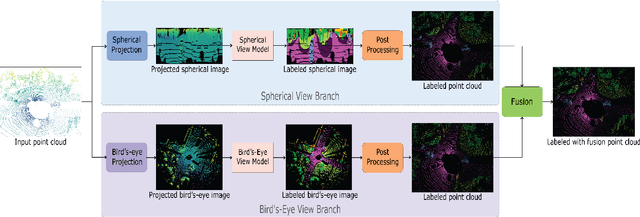
Semantic segmentation of 3D point cloud data is essential for enhanced high-level perception in autonomous platforms. Furthermore, given the increasing deployment of LiDAR sensors onboard of cars and drones, a special emphasis is also placed on non-computationally intensive algorithms that operate on mobile GPUs. Previous efficient state-of-the-art methods relied on 2D spherical projection of point clouds as input for 2D fully convolutional neural networks to balance the accuracy-speed trade-off. This paper introduces a novel approach for 3D point cloud semantic segmentation that exploits multiple projections of the point cloud to mitigate the loss of information inherent in single projection methods. Our Multi-Projection Fusion (MPF) framework analyzes spherical and bird's-eye view projections using two separate highly-efficient 2D fully convolutional models then combines the segmentation results of both views. The proposed framework is validated on the SemanticKITTI dataset where it achieved a mIoU of 55.5 which is higher than state-of-the-art projection-based methods RangeNet++ and PolarNet while being 1.6x faster than the former and 3.1x faster than the latter.
Robust Real-time Pedestrian Detection in Aerial Imagery on Jetson TX2
May 16, 2019
Detection of pedestrians in aerial imagery captured by drones has many applications including intersection monitoring, patrolling, and surveillance, to name a few. However, the problem is involved due to continuouslychanging camera viewpoint and object appearance as well as the need for lightweight algorithms to run on on-board embedded systems. To address this issue, the paper proposes a framework for pedestrian detection in videos based on the YOLO object detection network [6] while having a high throughput of more than 5 FPS on the Jetson TX2 embedded board. The framework exploits deep learning for robust operation and uses a pre-trained model without the need for any additional training which makes it flexible to apply on different setups with minimum amount of tuning. The method achieves ~81 mAP when applied on a sample video from the Embedded Real-Time Inference (ERTI) Challenge where pedestrians are monitored by a UAV.
Deep Convolutional Encoder-Decoders with Aggregated Multi-Resolution Skip Connections for Skin Lesion Segmentation
Jan 26, 2019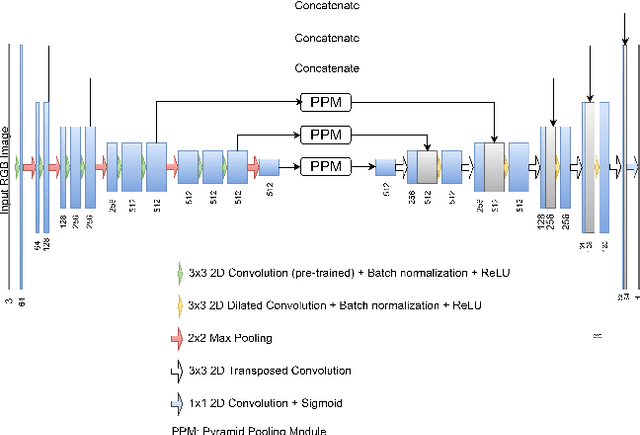
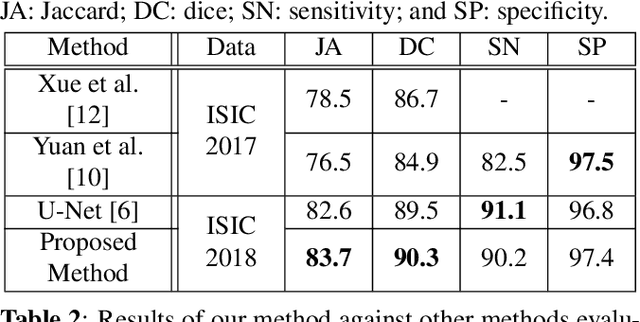
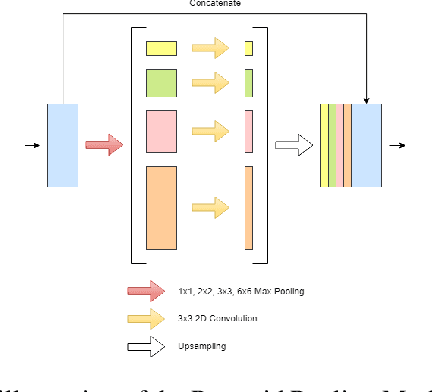
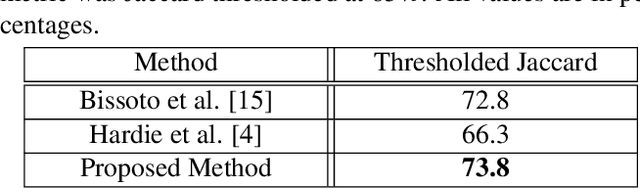
The prevalence of skin melanoma is rapidly increasing as well as the recorded death cases of its patients. Automatic image segmentation tools play an important role in providing standardized computer-assisted analysis for skin melanoma patients. Current state-of-the-art segmentation methods are based on fully convolutional neural networks, which utilize an encoder-decoder approach. However, these methods produce coarse segmentation masks due to the loss of location information during the encoding layers. Inspired by Pyramid Scene Parsing Network (PSP-Net), we propose an encoder-decoder model that utilizes pyramid pooling modules in the deep skip connections which aggregate the global context and compensate for the lost spatial information. We trained and validated our approach using ISIC 2018: Skin Lesion Analysis Towards Melanoma Detection grand challenge dataset. Our approach showed a validation accuracy with a Jaccard index of 0.837, which outperforms U-Net. We believe that with this reported reliable accuracy, this method can be introduced for clinical practice.