 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy-guided Multimodal Registration by Learning Segmentation without Ground Truth: Application to Intraprocedural CBCT/MR Liver Segmentation and Registration
Apr 14, 2021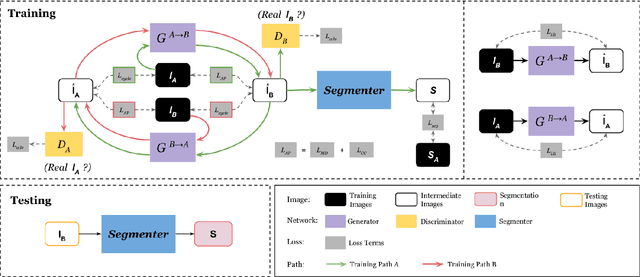


Multimodal image registration has many applications in diagnostic medical imaging and image-guided interventions, such as Transcatheter Arterial Chemoembolization (TACE) of liver cancer guided by intraprocedural CBCT and pre-operative MR. The ability to register peri-procedurally acquired diagnostic images into the intraprocedural environment can potentially improve the intra-procedural tumor targeting, which will significantly improve therapeutic outcomes. However, the intra-procedural CBCT often suffers from suboptimal image quality due to lack of signal calibration for Hounsfield unit, limited FOV, and motion/metal artifacts. These non-ideal conditions make standard intensity-based multimodal registration methods infeasible to generate correct transformation across modalities. While registration based on anatomic structures, such as segmentation or landmarks, provides an efficient alternative, such anatomic structure information is not always available. One can train a deep learning-based anatomy extractor, but it requires large-scale manual annotations on specific modalities, which are often extremely time-consuming to obtain and require expert radiological readers. To tackle these issues, we leverage annotated datasets already existing in a source modality and propose an anatomy-preserving domain adaptation to segmentation network (APA2Seg-Net) for learning segmentation without target modality ground truth. The segmenters are then integrated into our anatomy-guided multimodal registration based on the robust point matching machine. Our experimental results on in-house TACE patient data demonstrated that our APA2Seg-Net can generate robust CBCT and MR liver segmentation, and the anatomy-guided registration framework with these segmenters can provide high-quality multimodal registrations. Our code is available at https://github.com/bbbbbbzhou/APA2Seg-Net.
Unsupervised Wasserstein Distance Guided Domain Adaptation for 3D Multi-Domain Liver Segmentation
Sep 06, 2020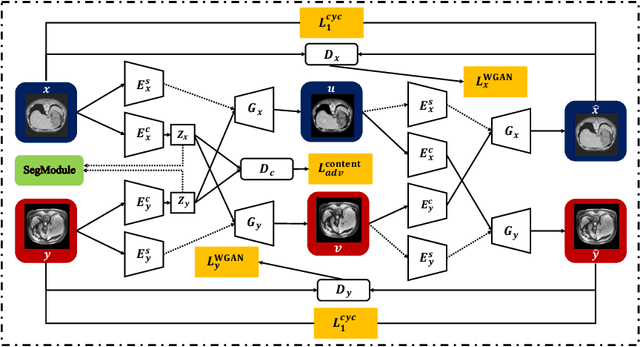

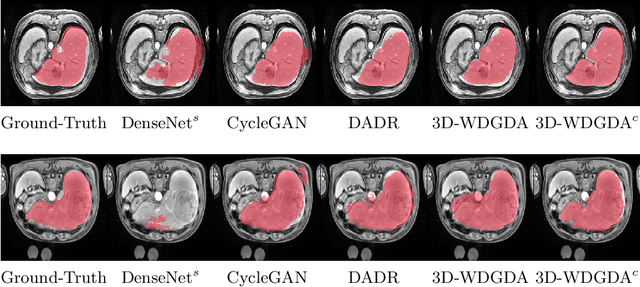

Deep neural networks have shown exceptional learning capability and generalizability in the source domain when massive labeled data is provided. However, the well-trained models often fail in the target domain due to the domain shift. Unsupervised domain adaptation aims to improve network performance when applying robust models trained on medical images from source domains to a new target domain. In this work, we present an approach based on the Wasserstein distance guided disentangled representation to achieve 3D multi-domain liver segmentation. Concretely, we embed images onto a shared content space capturing shared feature-level information across domains and domain-specific appearance spaces. The existing mutual information-based representation learning approaches often fail to capture complete representations in multi-domain medical imaging tasks. To mitigate these issues, we utilize Wasserstein distance to learn more complete representation, and introduces a content discriminator to further facilitate the representation disentanglement. Experiments demonstrate that our method outperforms the state-of-the-art on the multi-modality liver segmentation task.
Hepatocellular Carcinoma Intra-arterial Treatment Response Prediction for Improved Therapeutic Decision-Making
Dec 01, 2019
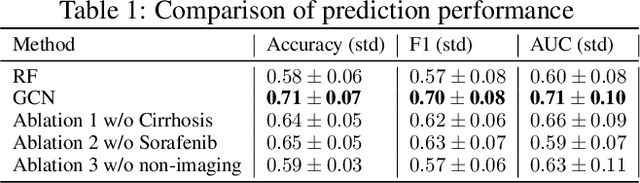
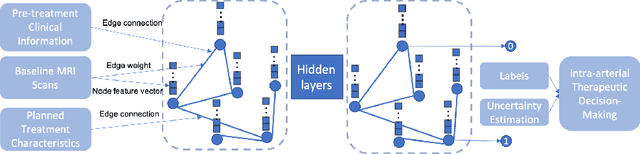
This work proposes a pipeline to predict treatment response to intra-arterial therapy of patients with Hepatocellular Carcinoma (HCC) for improved therapeutic decision-making. Our graph neural network model seamlessly combines heterogeneous inputs of baseline MR scans, pre-treatment clinical information, and planned treatment characteristics and has been validated on patients with HCC treated by transarterial chemoembolization (TACE). It achieves Accuracy of $0.713 \pm 0.075$, F1 of $0.702 \pm 0.082$ and AUC of $0.710 \pm 0.108$. In addition, the pipeline incorporates uncertainty estimation to select hard cases and most align with the misclassified cases. The proposed pipeline arrives at more informed intra-arterial therapeutic decisions for patients with HCC via improving model accuracy and incorporating uncertainty estimation.
Unsupervised Domain Adaptation via Disentangled Representations: Application to Cross-Modality Liver Segmentation
Aug 29, 2019
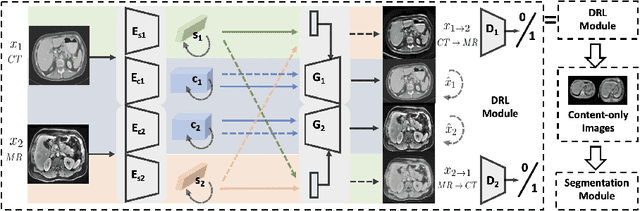
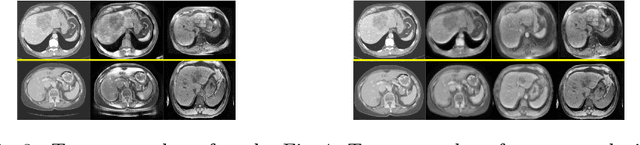
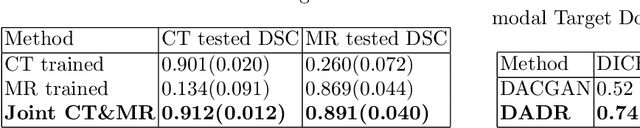
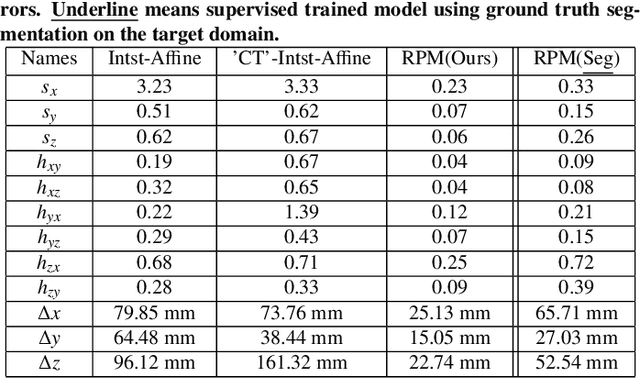
A deep learning model trained on some labeled data from a certain source domain generally performs poorly on data from different target domains due to domain shifts. Unsupervised domain adaptation methods address this problem by alleviating the domain shift between the labeled source data and the unlabeled target data. In this work, we achieve cross-modality domain adaptation, i.e. between CT and MRI images, via disentangled representations. Compared to learning a one-to-one mapping as the state-of-art CycleGAN, our model recovers a many-to-many mapping between domains to capture the complex cross-domain relations. It preserves semantic feature-level information by finding a shared content space instead of a direct pixelwise style transfer. Domain adaptation is achieved in two steps. First, images from each domain are embedded into two spaces, a shared domain-invariant content space and a domain-specific style space. Next, the representation in the content space is extracted to perform a task. We validated our method on a cross-modality liver segmentation task, to train a liver segmentation model on CT images that also performs well on MRI. Our method achieved Dice Similarity Coefficient (DSC) of 0.81, outperforming a CycleGAN-based method of 0.72. Moreover, our model achieved good generalization to joint-domain learning, in which unpaired data from different modalities are jointly learned to improve the segmentation performance on each individual modality. Lastly, under a multi-modal target domain with significant diversity, our approach exhibited the potential for diverse image generation and remained effective with DSC of 0.74 on multi-phasic MRI while the CycleGAN-based method performed poorly with a DSC of only 0.52.
Domain-Agnostic Learning with Anatomy-Consistent Embedding for Cross-Modality Liver Segmentation
Aug 27, 2019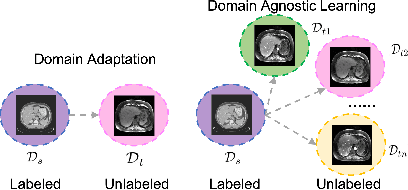
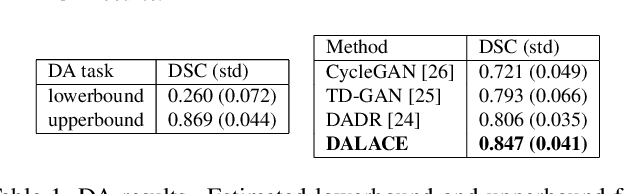
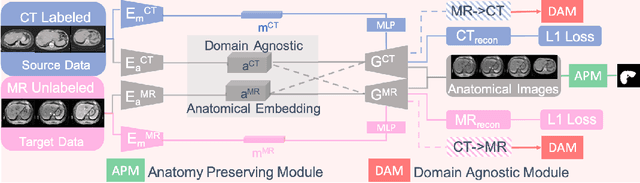
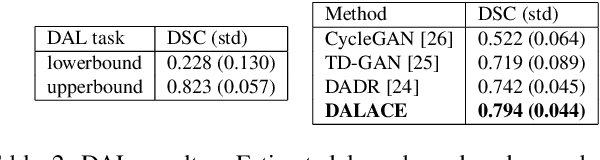
Domain Adaptation (DA) has the potential to greatly help the generalization of deep learning models. However, the current literature usually assumes to transfer the knowledge from the source domain to a specific known target domain. Domain Agnostic Learning (DAL) proposes a new task of transferring knowledge from the source domain to data from multiple heterogeneous target domains. In this work, we propose the Domain-Agnostic Learning framework with Anatomy-Consistent Embedding (DALACE) that works on both domain-transfer and task-transfer to learn a disentangled representation, aiming to not only be invariant to different modalities but also preserve anatomical structures for the DA and DAL tasks in cross-modality liver segmentation. We validated and compared our model with state-of-the-art methods, including CycleGAN, Task Driven Generative Adversarial Network (TD-GAN), and Domain Adaptation via Disentangled Representations (DADR). For the DA task, our DALACE model outperformed CycleGAN, TD-GAN ,and DADR with DSC of 0.847 compared to 0.721, 0.793 and 0.806. For the DAL task, our model improved the performance with DSC of 0.794 from 0.522, 0.719 and 0.742 by CycleGAN, TD-GAN, and DADR. Further, we visualized the success of disentanglement, which added human interpretability of the learned meaningful representations. Through ablation analysis, we specifically showed the concrete benefits of disentanglement for downstream tasks and the role of supervision for better disentangled representation with segmentation consistency to be invariant to domains with the proposed Domain-Agnostic Module (DAM) and to preserve anatomical information with the proposed Anatomy-Preserving Module (APM).