 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation via Disentangled Representations: Application to Cross-Modality Liver Segmentation
Paper and Code
Aug 29, 2019
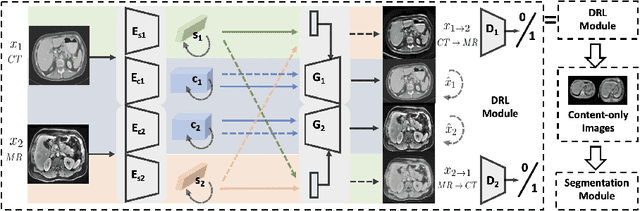
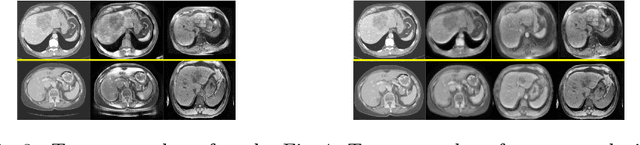
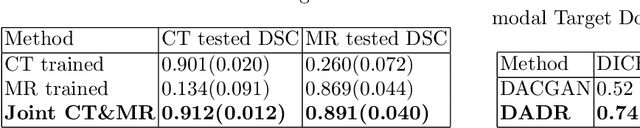
A deep learning model trained on some labeled data from a certain source domain generally performs poorly on data from different target domains due to domain shifts. Unsupervised domain adaptation methods address this problem by alleviating the domain shift between the labeled source data and the unlabeled target data. In this work, we achieve cross-modality domain adaptation, i.e. between CT and MRI images, via disentangled representations. Compared to learning a one-to-one mapping as the state-of-art CycleGAN, our model recovers a many-to-many mapping between domains to capture the complex cross-domain relations. It preserves semantic feature-level information by finding a shared content space instead of a direct pixelwise style transfer. Domain adaptation is achieved in two steps. First, images from each domain are embedded into two spaces, a shared domain-invariant content space and a domain-specific style space. Next, the representation in the content space is extracted to perform a task. We validated our method on a cross-modality liver segmentation task, to train a liver segmentation model on CT images that also performs well on MRI. Our method achieved Dice Similarity Coefficient (DSC) of 0.81, outperforming a CycleGAN-based method of 0.72. Moreover, our model achieved good generalization to joint-domain learning, in which unpaired data from different modalities are jointly learned to improve the segmentation performance on each individual modality. Lastly, under a multi-modal target domain with significant diversity, our approach exhibited the potential for diverse image generation and remained effective with DSC of 0.74 on multi-phasic MRI while the CycleGAN-based method performed poorly with a DSC of only 0.52.