 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Modular Robot Visual-motor Locomotion Policies
Oct 31, 2022



Control policy learning for modular robot locomotion has previously been limited to proprioceptive feedback and flat terrain. This paper develops policies for modular systems with vision traversing more challenging environments. These modular robots can be reconfigured to form many different designs, where each design needs a controller to function. Though one could create a policy for individual designs and environments, such an approach is not scalable given the wide range of potential designs and environments. To address this challenge, we create a visual-motor policy that can generalize to both new designs and environments. The policy itself is modular, in that it is divided into components, each of which corresponds to a type of module (e.g., a leg, wheel, or body). The policy components can be recombined during training to learn to control multiple designs. We develop a deep reinforcement learning algorithm where visual observations are input to a modular policy interacting with multiple environments at once. We apply this algorithm to train robots with combinations of legs and wheels, then demonstrate the policy controlling real robots climbing stairs and curbs.
Learning Modular Robot Locomotion from Demonstrations
Oct 31, 2022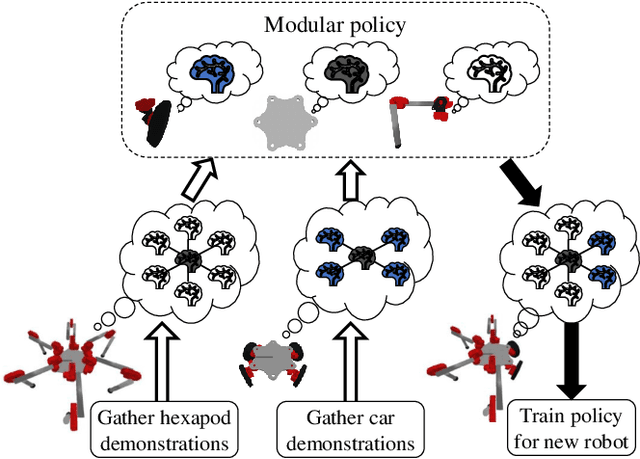

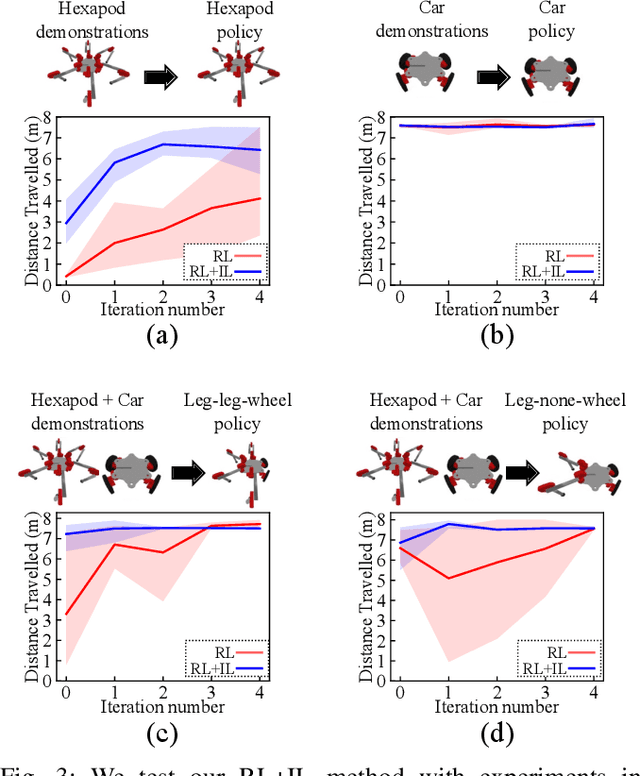
Modular robots can be reconfigured to create a variety of designs from a small set of components. But constructing a robot's hardware on its own is not enough -- each robot needs a controller. One could create controllers for some designs individually, but developing policies for additional designs can be time consuming. This work presents a method that uses demonstrations from one set of designs to accelerate policy learning for additional designs. We leverage a learning framework in which a graph neural network is made up of modular components, each component corresponds to a type of module (e.g., a leg, wheel, or body) and these components can be recombined to learn from multiple designs at once. In this paper we develop a combined reinforcement and imitation learning algorithm. Our method is novel because the policy is optimized to both maximize a reward for one design, and simultaneously imitate demonstrations from different designs, within one objective function. We show that when the modular policy is optimized with this combined objective, demonstrations from one set of designs influence how the policy behaves on a different design, decreasing the number of training iterations needed.
A general locomotion control framework for serially connected multi-legged robots
Dec 01, 2021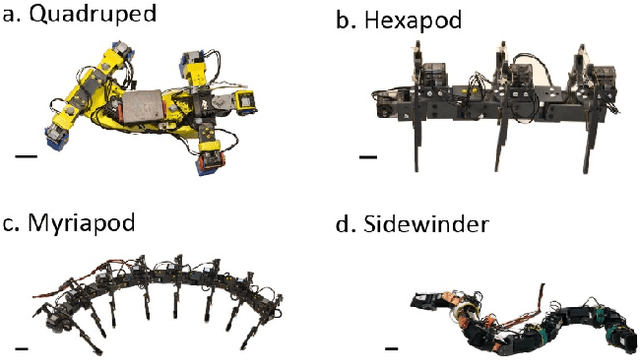

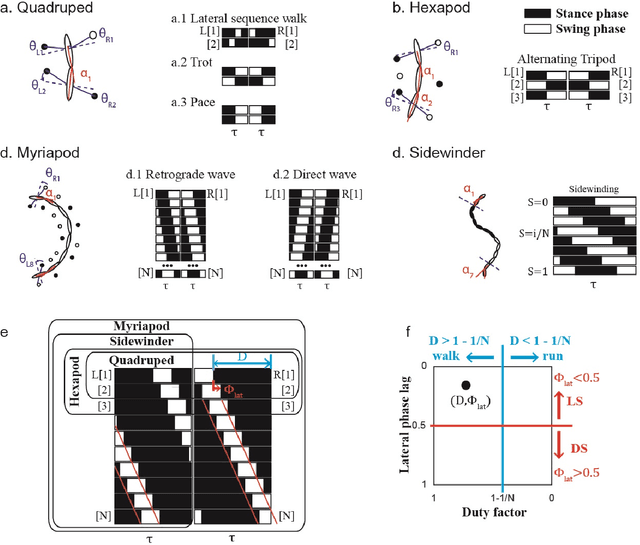
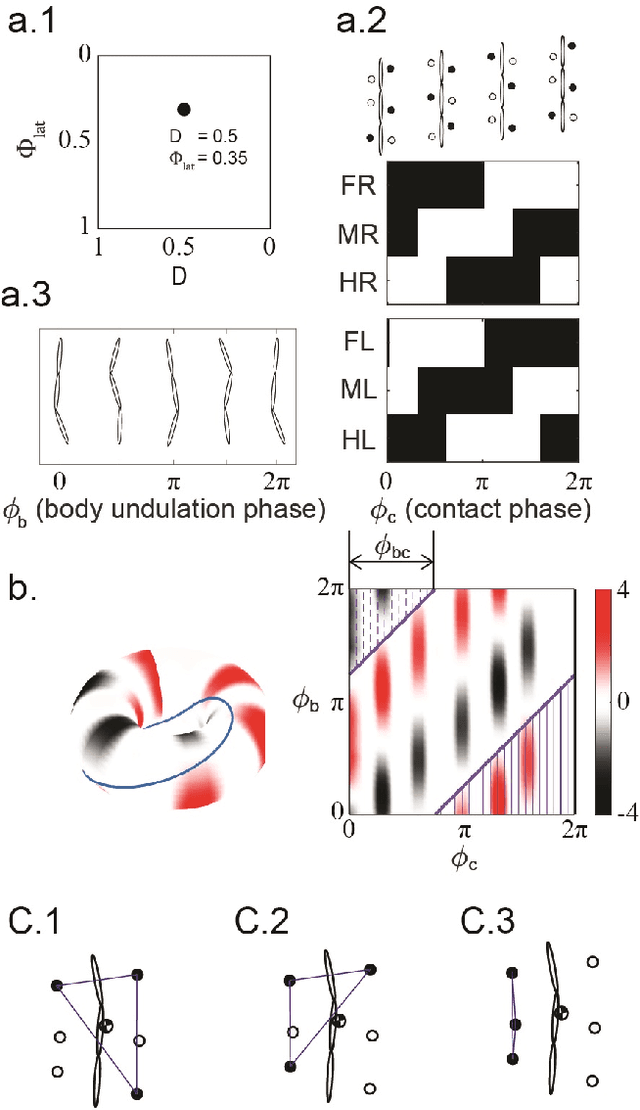
Serially connected robots are promising candidates for performing tasks in confined spaces such as search-and-rescue in large-scale disasters. Such robots are typically limbless, and we hypothesize that the addition of limbs could improve mobility. However, a challenge in designing and controlling such devices lies in the coordination of high-dimensional redundant modules in a way that improves mobility. Here we develop a general framework to control serially connected multi-legged robots. Specifically, we combine two approaches to build a general shape control scheme which can provide baseline patterns of self-deformation ("gaits") for effective locomotion in diverse robot morphologies. First, we take inspiration from a dimensionality reduction and a biological gait classification scheme to generate cyclic patterns of body deformation and foot lifting/lowering, which facilitate generation of arbitrary substrate contact patterns. Second, we use geometric mechanics methods to facilitates identification of optimal phasing of these undulations to maximize speed and/or stability. Our scheme allows the development of effective gaits in multi-legged robots locomoting on flat frictional terrain with diverse number of limbs (4, 6, 16, and even 0 limbs) and body actuation capabilities (including sidewinding gaits on limbless devices). By properly coordinating the body undulation and the leg placement, our framework combines the advantages of both limbless robots (modularity) and legged robots (mobility). We expect that our framework can provide general control schemes for the rapid deployment of general multi-legged robots, paving the ways toward machines that can traverse complex environments under real-life conditions.
Learning Modular Robot Control Policies
May 20, 2021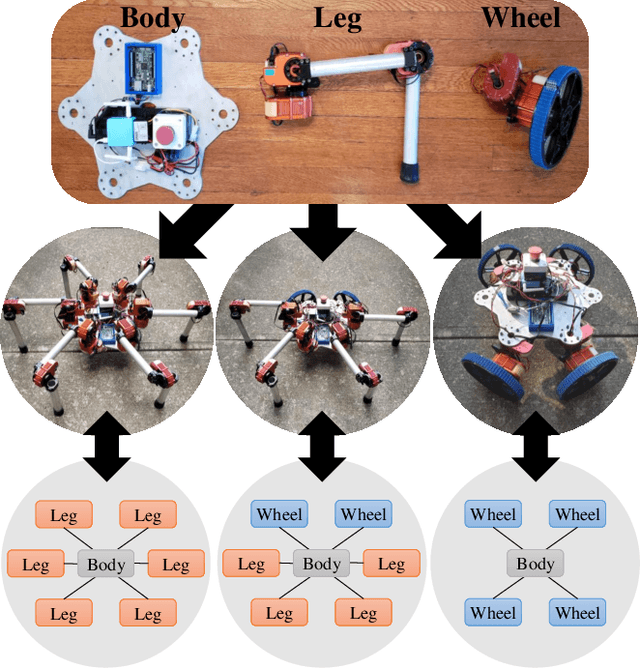



To make a modular robotic system both capable and scalable, the controller must be equally as modular as the mechanism. Given the large number of designs that can be generated from even a small set of modules, it becomes impractical to create a new system-wide controller for each design. Instead, we construct a modular control policy that handles a broad class of designs. We take the view that a module is both form and function, i.e. both mechanism and controller. As the modules are physically re-configured, the policy automatically re-configures to match the kinematic structure. This novel policy is trained with a new model-based reinforcement learning algorithm, which interleaves model learning and trajectory optimization to guide policy learning for multiple designs simultaneously. Training the policy on a varied set of designs teaches it how to adapt its behavior to the design. We show that the policy can then generalize to a larger set of designs not seen during training. We demonstrate one policy controlling many designs with different combinations of legs and wheels to locomote both in simulation and on real robots.
Reconstruction of Backbone Curves for Snake Robots
Dec 09, 2020
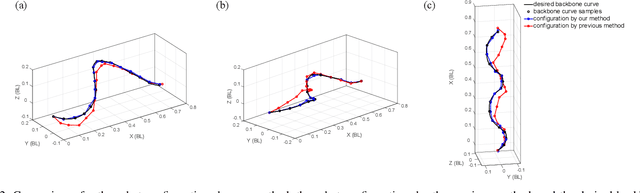
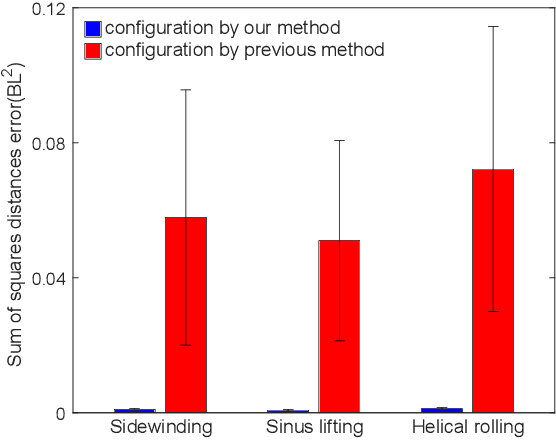
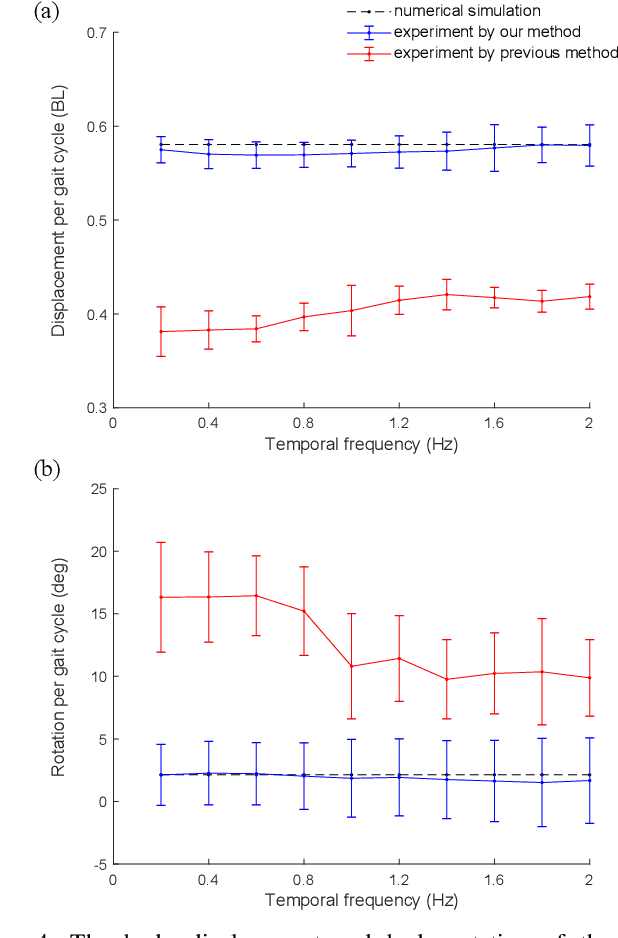
Snake robots composed of alternating single-axis pitch and yaw joints have many internal degrees of freedom, which make them capable of versatile three-dimensional locomotion. Often, snake robot motions are planned kinematically by a chronological sequence of continuous backbone curves that capture desired macroscopic shapes of the robot. However, as the geometric arrangement of single-axis rotary joints creates constraints on the rotations in the robot, it is challenging for the robot to reconstruct an arbitrary 3-D curve. When the robot configuration does not accurately achieve the desired shapes defined by these backbone curves, the robot can have undesired contact with the environment, such that the robot does not achieve the desired motion. In this work, we propose a method for snake robots to reconstruct desired backbone curves by posing an optimization problem that exploits the robot's geometric structure. We verified that our method enables accurate curve-configuration conversions through its applications to commonly used 3-D gaits. We also demonstrated via robot experiments that 1) our method results in smooth locomotion on the robot; 2) our method allows the robot to approach the numerically predicted locomotive performance of a sequence of continuous backbone curve.
Directional Compliance in Obstacle-Aided Navigation for Snake Robots
Apr 15, 2020
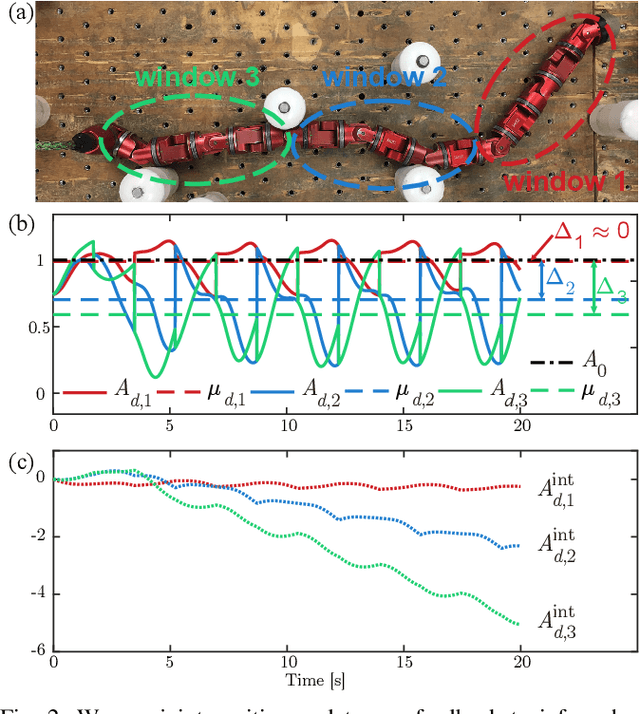
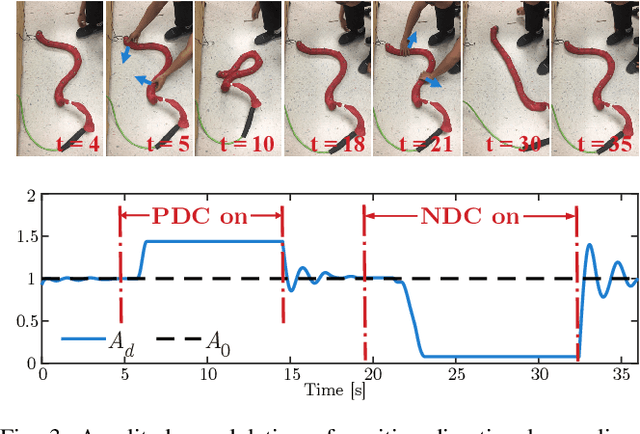
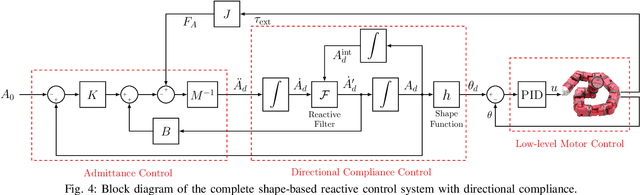
Snake robots have the potential to maneuver through tightly packed and complex environments. One challenge in enabling them to do so is the complexity in determining how to coordinate their many degrees-of-freedom to create purposeful motion. This is especially true in the types of terrains considered in this work: environments full of unmodeled features that even the best of maps would not capture, motivating us to develop closed-loop controls to react to those features. To accomplish this, this work uses proprioceptive sensing, mainly the force information measured by the snake robot's joints, to react to unmodeled terrain. We introduce a biologically-inspired strategy called directional compliance which modulates the effective stiffness of the robot so that it conforms to the terrain in some directions and resists in others. We present a dynamical system that switches between modes of locomotion to handle situations in which the robot gets wedged or stuck. This approach enables the snake robot to reliably traverse a planar peg array and an outdoor three-dimensional pile of rocks.