 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Modular Robot Locomotion from Demonstrations
Paper and Code
Oct 31, 2022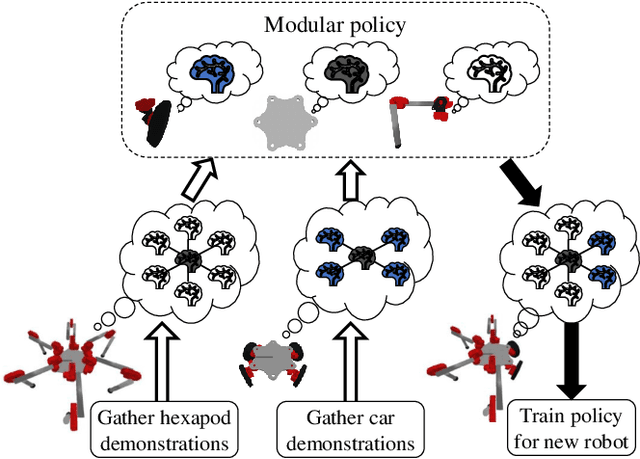

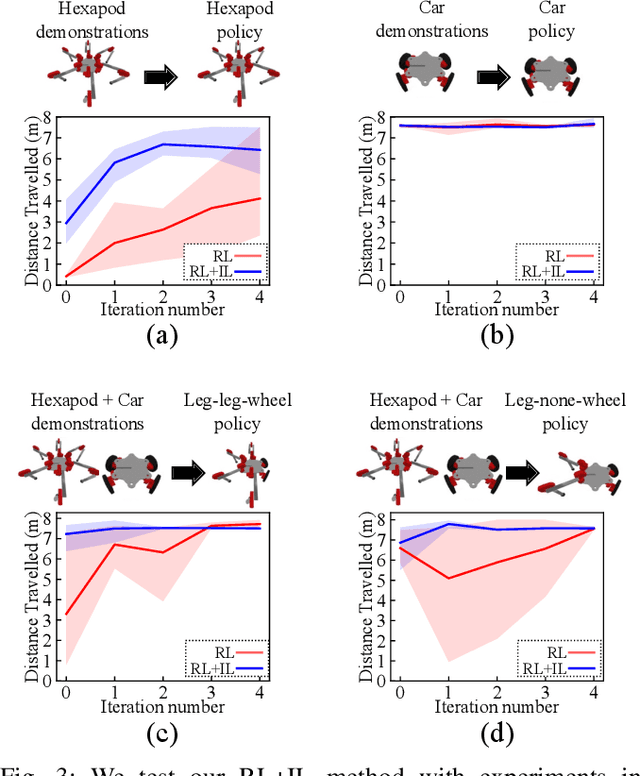
Modular robots can be reconfigured to create a variety of designs from a small set of components. But constructing a robot's hardware on its own is not enough -- each robot needs a controller. One could create controllers for some designs individually, but developing policies for additional designs can be time consuming. This work presents a method that uses demonstrations from one set of designs to accelerate policy learning for additional designs. We leverage a learning framework in which a graph neural network is made up of modular components, each component corresponds to a type of module (e.g., a leg, wheel, or body) and these components can be recombined to learn from multiple designs at once. In this paper we develop a combined reinforcement and imitation learning algorithm. Our method is novel because the policy is optimized to both maximize a reward for one design, and simultaneously imitate demonstrations from different designs, within one objective function. We show that when the modular policy is optimized with this combined objective, demonstrations from one set of designs influence how the policy behaves on a different design, decreasing the number of training iterations needed.