 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTARR: A fast and robust method for identifying anatomical regions on CT images via atlas registration
Oct 03, 2024Medical image analysis tasks often focus on regions or structures located in a particular location within the patient's body. Often large parts of the image may not be of interest for the image analysis task. When using deep-learning based approaches, this causes an unnecessary increases the computational burden during inference and raises the chance of errors. In this paper, we introduce CTARR, a novel generic method for CT Anatomical Region Recognition. The method serves as a pre-processing step for any deep learning-based CT image analysis pipeline by automatically identifying the pre-defined anatomical region that is relevant for the follow-up task and removing the rest. It can be used in (i) image segmentation to prevent false positives in anatomically implausible regions and speeding up the inference, (ii) image classification to produce image crops that are consistent in their anatomical context, and (iii) image registration by serving as a fast pre-registration step. Our proposed method is based on atlas registration and provides a fast and robust way to crop any anatomical region encoded as one or multiple bounding box(es) from any unlabeled CT scan of the brain, chest, abdomen and/or pelvis. We demonstrate the utility and robustness of the proposed method in the context of medical image segmentation by evaluating it on six datasets of public segmentation challenges. The foreground voxels in the regions of interest are preserved in the vast majority of cases and tasks (97.45-100%) while taking only fractions of a seconds to compute (0.1-0.21s) on a deep learning workstation and greatly reducing the segmentation runtime (2.0-12.7x). Our code is available at https://github.com/ThomasBudd/ctarr.
Leveraging the Mahalanobis Distance to enhance Unsupervised Brain MRI Anomaly Detection
Jul 17, 2024

Unsupervised Anomaly Detection (UAD) methods rely on healthy data distributions to identify anomalies as outliers. In brain MRI, a common approach is reconstruction-based UAD, where generative models reconstruct healthy brain MRIs, and anomalies are detected as deviations between input and reconstruction. However, this method is sensitive to imperfect reconstructions, leading to false positives that impede the segmentation. To address this limitation, we construct multiple reconstructions with probabilistic diffusion models. We then analyze the resulting distribution of these reconstructions using the Mahalanobis distance to identify anomalies as outliers. By leveraging information about normal variations and covariance of individual pixels within this distribution, we effectively refine anomaly scoring, leading to improved segmentation. Our experimental results demonstrate substantial performance improvements across various data sets. Specifically, compared to relying solely on single reconstructions, our approach achieves relative improvements of 15.9%, 35.4%, 48.0%, and 4.7% in terms of AUPRC for the BRATS21, ATLAS, MSLUB and WMH data sets, respectively.
Diffusion Models with Ensembled Structure-Based Anomaly Scoring for Unsupervised Anomaly Detection
Mar 21, 2024


Supervised deep learning techniques show promise in medical image analysis. However, they require comprehensive annotated data sets, which poses challenges, particularly for rare diseases. Consequently, unsupervised anomaly detection (UAD) emerges as a viable alternative for pathology segmentation, as only healthy data is required for training. However, recent UAD anomaly scoring functions often focus on intensity only and neglect structural differences, which impedes the segmentation performance. This work investigates the potential of Structural Similarity (SSIM) to bridge this gap. SSIM captures both intensity and structural disparities and can be advantageous over the classical $l1$ error. However, we show that there is more than one optimal kernel size for the SSIM calculation for different pathologies. Therefore, we investigate an adaptive ensembling strategy for various kernel sizes to offer a more pathology-agnostic scoring mechanism. We demonstrate that this ensembling strategy can enhance the performance of DMs and mitigate the sensitivity to different kernel sizes across varying pathologies, highlighting its promise for brain MRI anomaly detection.
Guided Reconstruction with Conditioned Diffusion Models for Unsupervised Anomaly Detection in Brain MRIs
Dec 07, 2023



Unsupervised anomaly detection in Brain MRIs aims to identify abnormalities as outliers from a healthy training distribution. Reconstruction-based approaches that use generative models to learn to reconstruct healthy brain anatomy are commonly used for this task. Diffusion models are an emerging class of deep generative models that show great potential regarding reconstruction fidelity. However, they face challenges in preserving intensity characteristics in the reconstructed images, limiting their performance in anomaly detection. To address this challenge, we propose to condition the denoising mechanism of diffusion models with additional information about the image to reconstruct coming from a latent representation of the noise-free input image. This conditioning enables high-fidelity reconstruction of healthy brain structures while aligning local intensity characteristics of input-reconstruction pairs. We evaluate our method's reconstruction quality, domain adaptation features and finally segmentation performance on publicly available data sets with various pathologies. Using our proposed conditioning mechanism we can reduce the false-positive predictions and enable a more precise delineation of anomalies which significantly enhances the anomaly detection performance compared to established state-of-the-art approaches to unsupervised anomaly detection in brain MRI. Furthermore, our approach shows promise in domain adaptation across different MRI acquisitions and simulated contrasts, a crucial property of general anomaly detection methods.
Patched Diffusion Models for Unsupervised Anomaly Detection in Brain MRI
Mar 07, 2023



The use of supervised deep learning techniques to detect pathologies in brain MRI scans can be challenging due to the diversity of brain anatomy and the need for annotated data sets. An alternative approach is to use unsupervised anomaly detection, which only requires sample-level labels of healthy brains to create a reference representation. This reference representation can then be compared to unhealthy brain anatomy in a pixel-wise manner to identify abnormalities. To accomplish this, generative models are needed to create anatomically consistent MRI scans of healthy brains. While recent diffusion models have shown promise in this task, accurately generating the complex structure of the human brain remains a challenge. In this paper, we propose a method that reformulates the generation task of diffusion models as a patch-based estimation of healthy brain anatomy, using spatial context to guide and improve reconstruction. We evaluate our approach on data of tumors and multiple sclerosis lesions and demonstrate a relative improvement of 25.1% compared to existing baselines.
Data-Efficient Vision Transformers for Multi-Label Disease Classification on Chest Radiographs
Aug 17, 2022
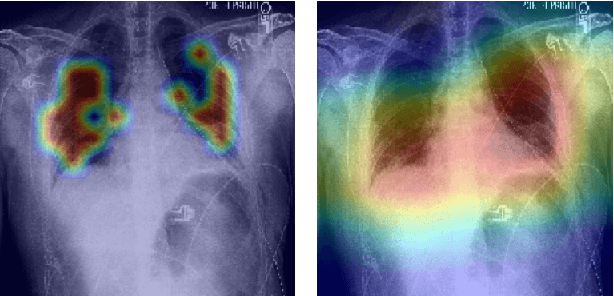
Radiographs are a versatile diagnostic tool for the detection and assessment of pathologies, for treatment planning or for navigation and localization purposes in clinical interventions. However, their interpretation and assessment by radiologists can be tedious and error-prone. Thus, a wide variety of deep learning methods have been proposed to support radiologists interpreting radiographs. Mostly, these approaches rely on convolutional neural networks (CNN) to extract features from images. Especially for the multi-label classification of pathologies on chest radiographs (Chest X-Rays, CXR), CNNs have proven to be well suited. On the Contrary, Vision Transformers (ViTs) have not been applied to this task despite their high classification performance on generic images and interpretable local saliency maps which could add value to clinical interventions. ViTs do not rely on convolutions but on patch-based self-attention and in contrast to CNNs, no prior knowledge of local connectivity is present. While this leads to increased capacity, ViTs typically require an excessive amount of training data which represents a hurdle in the medical domain as high costs are associated with collecting large medical data sets. In this work, we systematically compare the classification performance of ViTs and CNNs for different data set sizes and evaluate more data-efficient ViT variants (DeiT). Our results show that while the performance between ViTs and CNNs is on par with a small benefit for ViTs, DeiTs outperform the former if a reasonably large data set is available for training.
Unsupervised Anomaly Detection in 3D Brain MRI using Deep Learning with impured training data
Apr 12, 2022
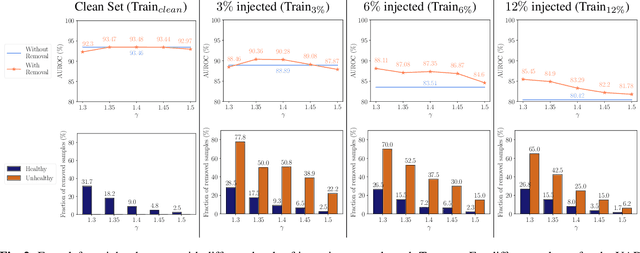
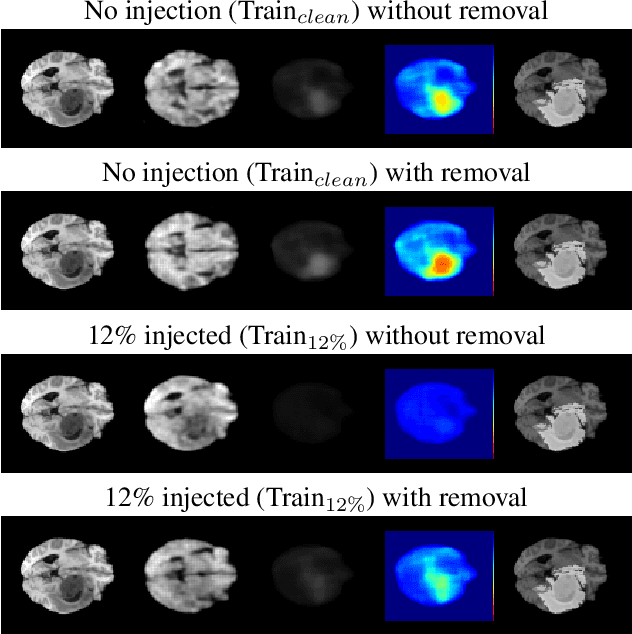
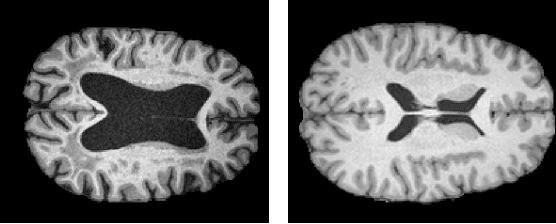
The detection of lesions in magnetic resonance imaging (MRI)-scans of human brains remains challenging, time-consuming and error-prone. Recently, unsupervised anomaly detection (UAD) methods have shown promising results for this task. These methods rely on training data sets that solely contain healthy samples. Compared to supervised approaches, this significantly reduces the need for an extensive amount of labeled training data. However, data labelling remains error-prone. We study how unhealthy samples within the training data affect anomaly detection performance for brain MRI-scans. For our evaluations, we consider three publicly available data sets and use autoencoders (AE) as a well-established baseline method for UAD. We systematically evaluate the effect of impured training data by injecting different quantities of unhealthy samples to our training set of healthy samples from T1-weighted MRI-scans. We evaluate a method to identify falsely labeled samples directly during training based on the reconstruction error of the AE. Our results show that training with impured data decreases the UAD performance notably even with few falsely labeled samples. By performing outlier removal directly during training based on the reconstruction-loss, we demonstrate that falsely labeled data can be detected and removed to mitigate the effect of falsely labeled data. Overall, we highlight the importance of clean data sets for UAD in brain MRI and demonstrate an approach for detecting falsely labeled data directly during training.
Unsupervised Anomaly Detection in 3D Brain MRI using Deep Learning with Multi-Task Brain Age Prediction
Jan 31, 2022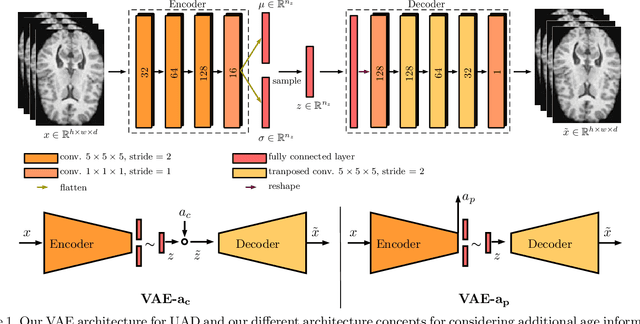

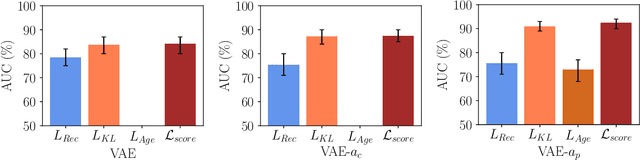
Lesion detection in brain Magnetic Resonance Images (MRIs) remains a challenging task. MRIs are typically read and interpreted by domain experts, which is a tedious and time-consuming process. Recently, unsupervised anomaly detection (UAD) in brain MRI with deep learning has shown promising results to provide a quick, initial assessment. So far, these methods only rely on the visual appearance of healthy brain anatomy for anomaly detection. Another biomarker for abnormal brain development is the deviation between the brain age and the chronological age, which is unexplored in combination with UAD. We propose deep learning for UAD in 3D brain MRI considering additional age information. We analyze the value of age information during training, as an additional anomaly score, and systematically study several architecture concepts. Based on our analysis, we propose a novel deep learning approach for UAD with multi-task age prediction. We use clinical T1-weighted MRIs of 1735 healthy subjects and the publicly available BraTs 2019 data set for our study. Our novel approach significantly improves UAD performance with an AUC of 92.60% compared to an AUC-score of 84.37% using previous approaches without age information.
3-Dimensional Deep Learning with Spatial Erasing for Unsupervised Anomaly Segmentation in Brain MRI
Sep 14, 2021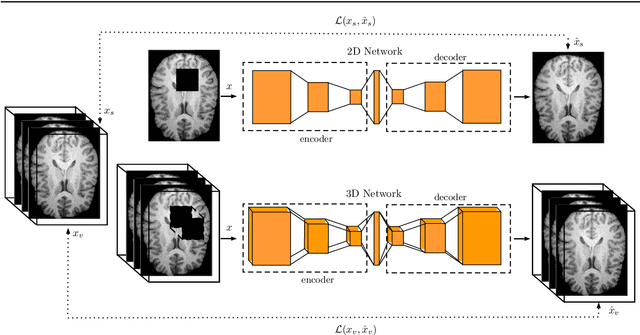
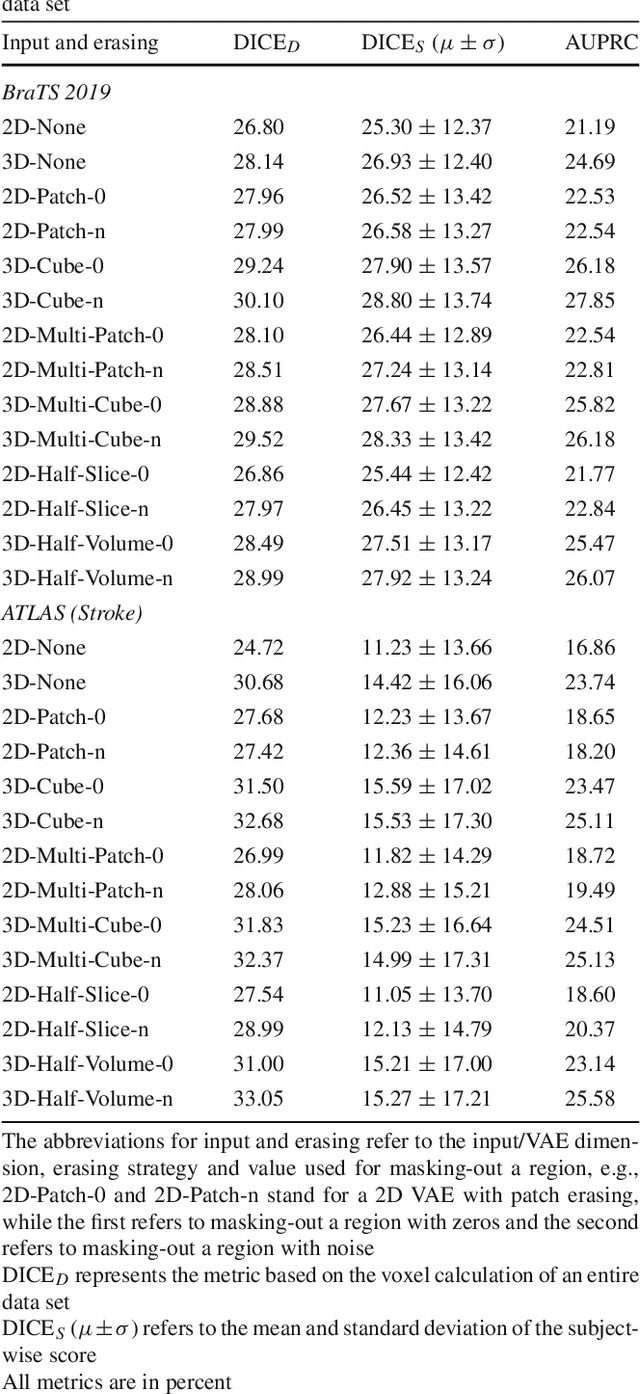
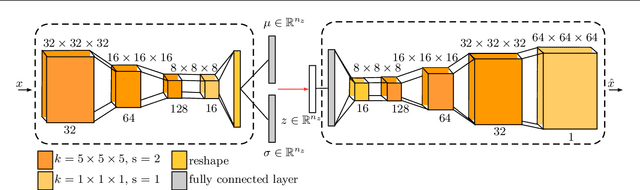
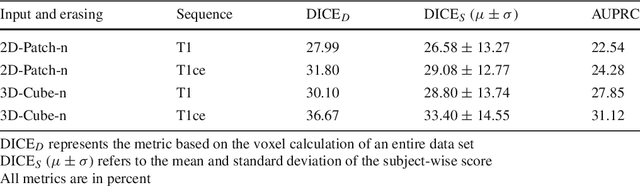
Purpose. Brain Magnetic Resonance Images (MRIs) are essential for the diagnosis of neurological diseases. Recently, deep learning methods for unsupervised anomaly detection (UAD) have been proposed for the analysis of brain MRI. These methods rely on healthy brain MRIs and eliminate the requirement of pixel-wise annotated data compared to supervised deep learning. While a wide range of methods for UAD have been proposed, these methods are mostly 2D and only learn from MRI slices, disregarding that brain lesions are inherently 3D and the spatial context of MRI volumes remains unexploited. Methods. We investigate whether using increased spatial context by using MRI volumes combined with spatial erasing leads to improved unsupervised anomaly segmentation performance compared to learning from slices. We evaluate and compare 2D variational autoencoder (VAE) to their 3D counterpart, propose 3D input erasing, and systemically study the impact of the data set size on the performance. Results. Using two publicly available segmentation data sets for evaluation, 3D VAE outperform their 2D counterpart, highlighting the advantage of volumetric context. Also, our 3D erasing methods allow for further performance improvements. Our best performing 3D VAE with input erasing leads to an average DICE score of 31.40% compared to 25.76% for the 2D VAE. Conclusions. We propose 3D deep learning methods for UAD in brain MRI combined with 3D erasing and demonstrate that 3D methods clearly outperform their 2D counterpart for anomaly segmentation. Also, our spatial erasing method allows for further performance improvements and reduces the requirement for large data sets.
Multiple Sclerosis Lesion Activity Segmentation with Attention-Guided Two-Path CNNs
Aug 05, 2020


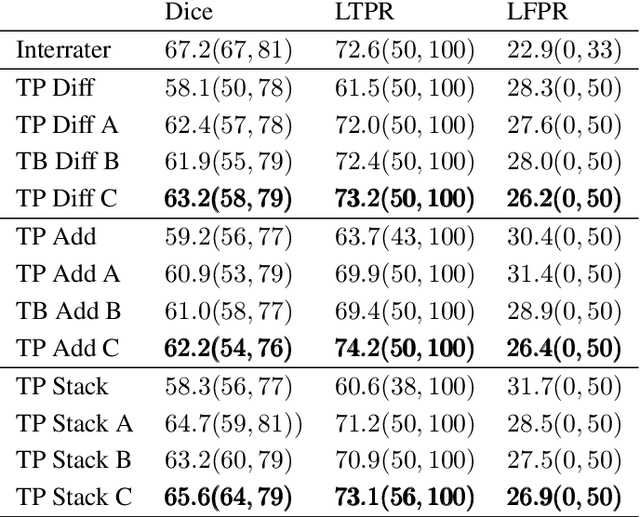
Multiple sclerosis is an inflammatory autoimmune demyelinating disease that is characterized by lesions in the central nervous system. Typically, magnetic resonance imaging (MRI) is used for tracking disease progression. Automatic image processing methods can be used to segment lesions and derive quantitative lesion parameters. So far, methods have focused on lesion segmentation for individual MRI scans. However, for monitoring disease progression, \textit{lesion activity} in terms of new and enlarging lesions between two time points is a crucial biomarker. For this problem, several classic methods have been proposed, e.g., using difference volumes. Despite their success for single-volume lesion segmentation, deep learning approaches are still rare for lesion activity segmentation. In this work, convolutional neural networks (CNNs) are studied for lesion activity segmentation from two time points. For this task, CNNs are designed and evaluated that combine the information from two points in different ways. In particular, two-path architectures with attention-guided interactions are proposed that enable effective information exchange between the two time point's processing paths. It is demonstrated that deep learning-based methods outperform classic approaches and it is shown that attention-guided interactions significantly improve performance. Furthermore, the attention modules produce plausible attention maps that have a masking effect that suppresses old, irrelevant lesions. A lesion-wise false positive rate of 26.4% is achieved at a true positive rate of 74.2%, which is not significantly different from the interrater performance.