 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTARR: A fast and robust method for identifying anatomical regions on CT images via atlas registration
Oct 03, 2024Medical image analysis tasks often focus on regions or structures located in a particular location within the patient's body. Often large parts of the image may not be of interest for the image analysis task. When using deep-learning based approaches, this causes an unnecessary increases the computational burden during inference and raises the chance of errors. In this paper, we introduce CTARR, a novel generic method for CT Anatomical Region Recognition. The method serves as a pre-processing step for any deep learning-based CT image analysis pipeline by automatically identifying the pre-defined anatomical region that is relevant for the follow-up task and removing the rest. It can be used in (i) image segmentation to prevent false positives in anatomically implausible regions and speeding up the inference, (ii) image classification to produce image crops that are consistent in their anatomical context, and (iii) image registration by serving as a fast pre-registration step. Our proposed method is based on atlas registration and provides a fast and robust way to crop any anatomical region encoded as one or multiple bounding box(es) from any unlabeled CT scan of the brain, chest, abdomen and/or pelvis. We demonstrate the utility and robustness of the proposed method in the context of medical image segmentation by evaluating it on six datasets of public segmentation challenges. The foreground voxels in the regions of interest are preserved in the vast majority of cases and tasks (97.45-100%) while taking only fractions of a seconds to compute (0.1-0.21s) on a deep learning workstation and greatly reducing the segmentation runtime (2.0-12.7x). Our code is available at https://github.com/ThomasBudd/ctarr.
Calibrating Ensembles for Scalable Uncertainty Quantification in Deep Learning-based Medical Segmentation
Sep 20, 2022
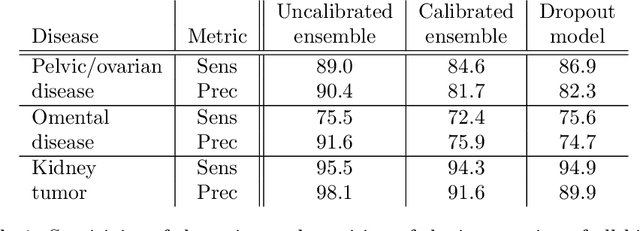
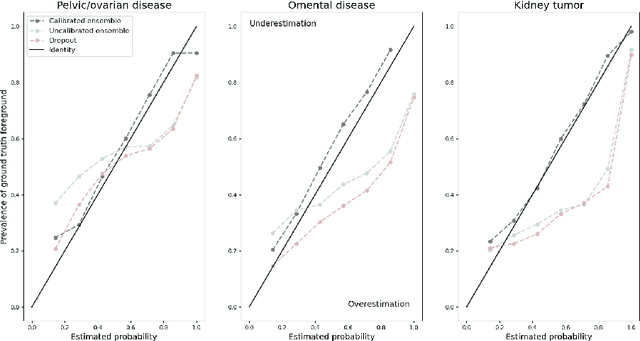
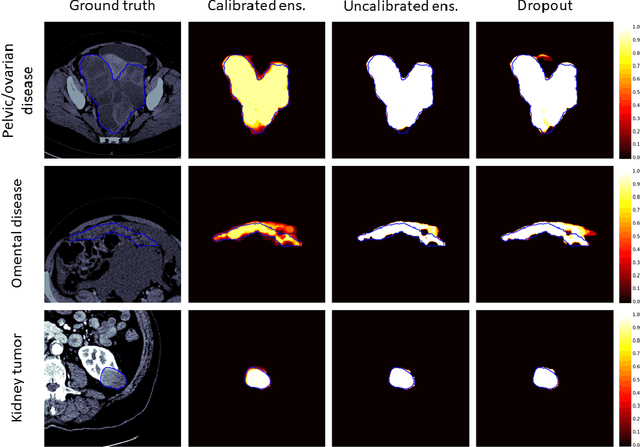
Uncertainty quantification in automated image analysis is highly desired in many applications. Typically, machine learning models in classification or segmentation are only developed to provide binary answers; however, quantifying the uncertainty of the models can play a critical role for example in active learning or machine human interaction. Uncertainty quantification is especially difficult when using deep learning-based models, which are the state-of-the-art in many imaging applications. The current uncertainty quantification approaches do not scale well in high-dimensional real-world problems. Scalable solutions often rely on classical techniques, such as dropout, during inference or training ensembles of identical models with different random seeds to obtain a posterior distribution. In this paper, we show that these approaches fail to approximate the classification probability. On the contrary, we propose a scalable and intuitive framework to calibrate ensembles of deep learning models to produce uncertainty quantification measurements that approximate the classification probability. On unseen test data, we demonstrate improved calibration, sensitivity (in two out of three cases) and precision when being compared with the standard approaches. We further motivate the usage of our method in active learning, creating pseudo-labels to learn from unlabeled images and human-machine collaboration.