 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Aware Range Image-Based Model for Point Cloud Segmentation
Mar 19, 2025Point cloud segmentation (PCS) aims to separate points into different and meaningful groups. The task plays an important role in robotics because PCS enables robots to understand their physical environments directly. To process sparse and large-scale outdoor point clouds in real time, range image-based models are commonly adopted. However, in a range image, the lack of explicit depth information inevitably causes some separate objects in 3D space to touch each other, bringing difficulty for the range image-based models in correctly segmenting the objects. Moreover, previous PCS models are usually derived from the existing color image-based models and unable to make full use of the implicit but ordered depth information inherent in the range image, thereby achieving inferior performance. In this paper, we propose Depth-Aware Module (DAM) and Fast FMVNet V3. DAM perceives the ordered depth information in the range image by explicitly modelling the interdependence among channels. Fast FMVNet V3 incorporates DAM by integrating it into the last block in each architecture stage. Extensive experiments conducted on SemanticKITTI, nuScenes, and SemanticPOSS demonstrate that DAM brings a significant improvement for Fast FMVNet V3 with negligible computational cost.
An Experimental Study of SOTA LiDAR Segmentation Models
Feb 18, 2025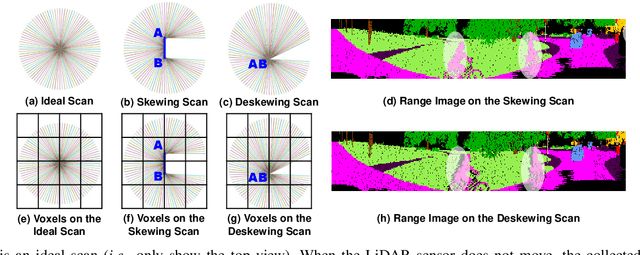
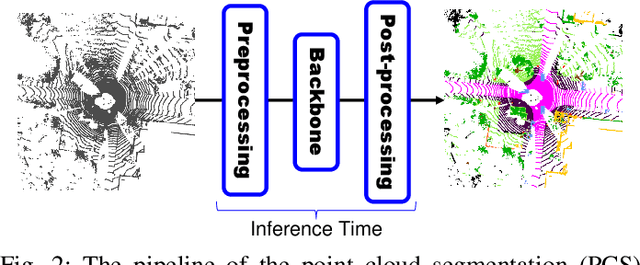
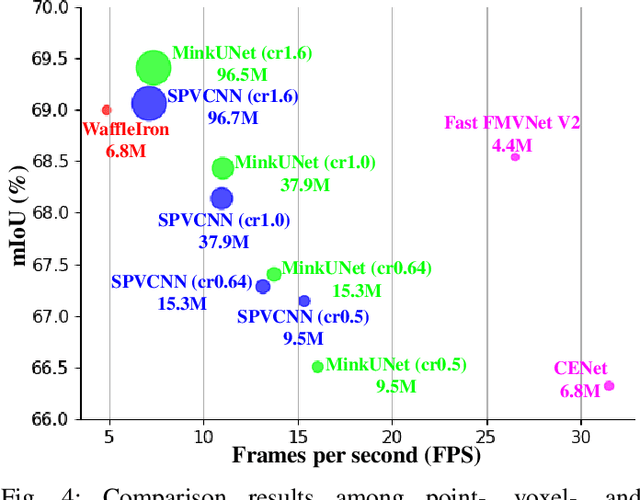
Point cloud segmentation (PCS) is to classify each point in point clouds. The task enables robots to parse their 3D surroundings and run autonomously. According to different point cloud representations, existing PCS models can be roughly divided into point-, voxel-, and range image-based models. However, no work has been found to report comprehensive comparisons among the state-of-the-art point-, voxel-, and range image-based models from an application perspective, bringing difficulty in utilizing these models for real-world scenarios. In this paper, we provide thorough comparisons among the models by considering the LiDAR data motion compensation and the metrics of model parameters, max GPU memory allocated during testing, inference latency, frames per second, intersection-over-union (IoU) and mean IoU (mIoU) scores. The experimental results benefit engineers when choosing a reasonable PCS model for an application and inspire researchers in the PCS field to design more practical models for a real-world scenario.
Trainable Pointwise Decoder Module for Point Cloud Segmentation
Aug 02, 2024



Point cloud segmentation (PCS) aims to make per-point predictions and enables robots and autonomous driving cars to understand the environment. The range image is a dense representation of a large-scale outdoor point cloud, and segmentation models built upon the image commonly execute efficiently. However, the projection of the point cloud onto the range image inevitably leads to dropping points because, at each image coordinate, only one point is kept despite multiple points being projected onto the same location. More importantly, it is challenging to assign correct predictions to the dropped points that belong to the classes different from the kept point class. Besides, existing post-processing methods, such as K-nearest neighbor (KNN) search and kernel point convolution (KPConv), cannot be trained with the models in an end-to-end manner or cannot process varying-density outdoor point clouds well, thereby enabling the models to achieve sub-optimal performance. To alleviate this problem, we propose a trainable pointwise decoder module (PDM) as the post-processing approach, which gathers weighted features from the neighbors and then makes the final prediction for the query point. In addition, we introduce a virtual range image-guided copy-rotate-paste (VRCrop) strategy in data augmentation. VRCrop constrains the total number of points and eliminates undesirable artifacts in the augmented point cloud. With PDM and VRCrop, existing range image-based segmentation models consistently perform better than their counterparts on the SemanticKITTI, SemanticPOSS, and nuScenes datasets.
UAV-based Intelligent Information Systems on Winter Road Safety for Autonomous Vehicles
Jun 18, 2024



As autonomous vehicles continue to revolutionize transportation, addressing challenges posed by adverse weather conditions, particularly during winter, becomes paramount for ensuring safe and efficient operations. One of the most important aspects of a road safety inspection during adverse weather is when a limited lane width can reduce the capacity of the road and raise the risk of serious accidents involving autonomous vehicles. In this research, a method for improving driving challenges on roads in winter conditions, with a model that segments and estimates the width of the road from the perspectives of Uncrewed aerial vehicles and autonomous vehicles. The proposed approach in this article is needed to empower self-driving cars with up-to-date and accurate insights, enhancing their adaptability and decision-making capabilities in winter landscapes.
Filling Missing Values Matters for Range Image-Based Point Cloud Segmentation
May 16, 2024

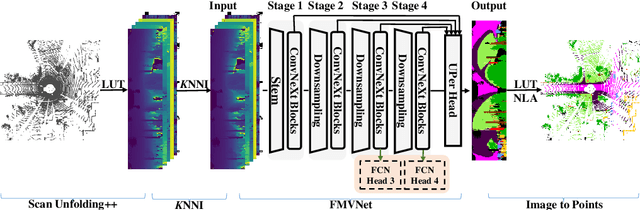

Point cloud segmentation (PCS) plays an essential role in robot perception and navigation tasks. To efficiently understand large-scale outdoor point clouds, their range image representation is commonly adopted. This image-like representation is compact and structured, making range image-based PCS models practical. However, undesirable missing values in the range images damage the shapes and patterns of objects. This problem creates difficulty for the models in learning coherent and complete geometric information from the objects. Consequently, the PCS models only achieve inferior performance. Delving deeply into this issue, we find that the use of unreasonable projection approaches and deskewing scans mainly leads to unwanted missing values in the range images. Besides, almost all previous works fail to consider filling in the unexpected missing values in the PCS task. To alleviate this problem, we first propose a new projection method, namely scan unfolding++ (SU++), to avoid massive missing values in the generated range images. Then, we introduce a simple yet effective approach, namely range-dependent $K$-nearest neighbor interpolation ($K$NNI), to further fill in missing values. Finally, we introduce the Filling Missing Values Network (FMVNet) and Fast FMVNet. Extensive experimental results on SemanticKITTI, SemanticPOSS, and nuScenes datasets demonstrate that by employing the proposed SU++ and $K$NNI, existing range image-based PCS models consistently achieve better performance than the baseline models. Besides, both FMVNet and Fast FMVNet achieve state-of-the-art performance in terms of the speed-accuracy trade-off. The proposed methods can be applied to other range image-based tasks and practical applications.
Feature Relevance Analysis to Explain Concept Drift -- A Case Study in Human Activity Recognition
Jan 20, 2023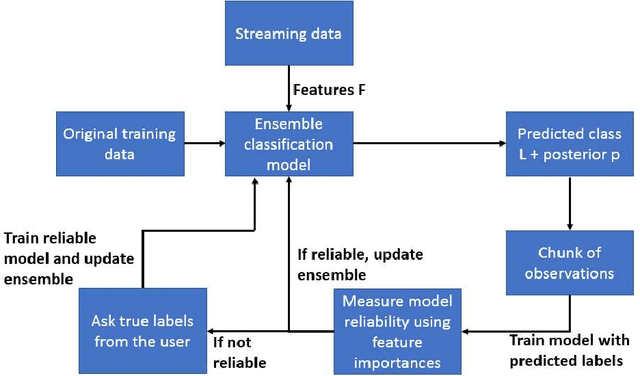
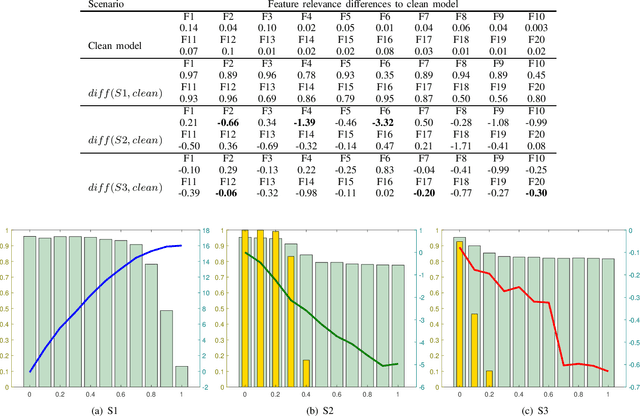
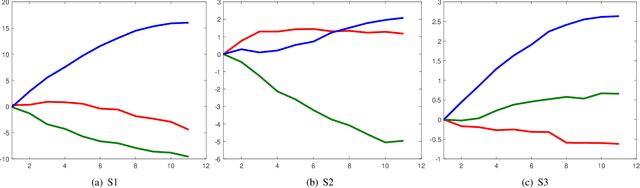

This article studies how to detect and explain concept drift. Human activity recognition is used as a case study together with a online batch learning situation where the quality of the labels used in the model updating process starts to decrease. Drift detection is based on identifying a set of features having the largest relevance difference between the drifting model and a model that is known to be accurate and monitoring how the relevance of these features changes over time. As a main result of this article, it is shown that feature relevance analysis cannot only be used to detect the concept drift but also to explain the reason for the drift when a limited number of typical reasons for the concept drift are predefined. To explain the reason for the concept drift, it is studied how these predefined reasons effect to feature relevance. In fact, it is shown that each of these has an unique effect to features relevance and these can be used to explain the reason for concept drift.
Hyperbolic Uncertainty Aware Semantic Segmentation
Mar 16, 2022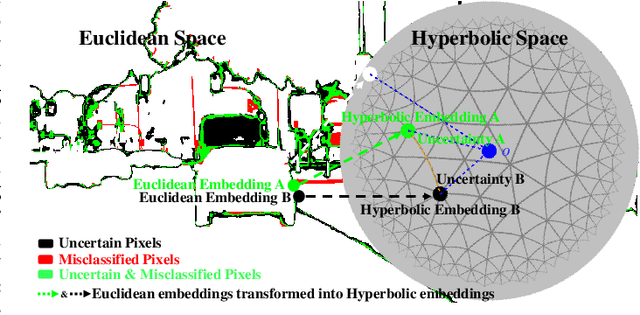
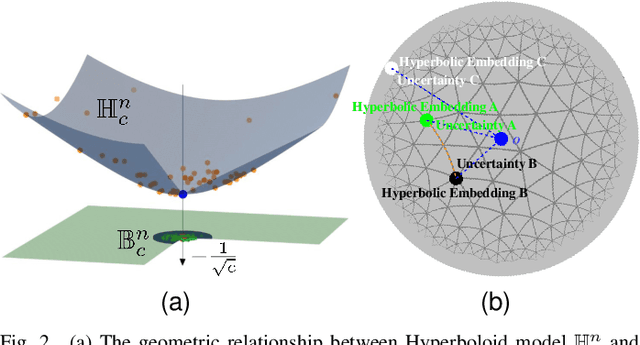
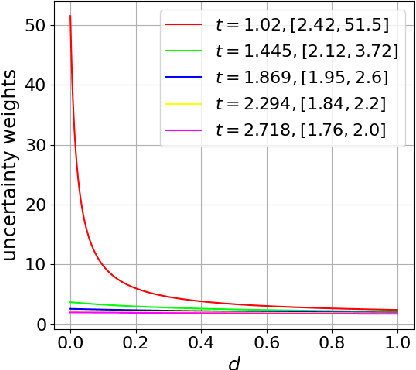

Semantic segmentation (SS) aims to classify each pixel into one of the pre-defined classes. This task plays an important role in self-driving cars and autonomous drones. In SS, many works have shown that most misclassified pixels are commonly near object boundaries with high uncertainties. However, existing SS loss functions are not tailored to handle these uncertain pixels during training, as these pixels are usually treated equally as confidently classified pixels and cannot be embedded with arbitrary low distortion in Euclidean space, thereby degenerating the performance of SS. To overcome this problem, this paper designs a "Hyperbolic Uncertainty Loss" (HyperUL), which dynamically highlights the misclassified and high-uncertainty pixels in Hyperbolic space during training via the hyperbolic distances. The proposed HyperUL is model agnostic and can be easily applied to various neural architectures. After employing HyperUL to three recent SS models, the experimental results on Cityscapes and UAVid datasets reveal that the segmentation performance of existing SS models can be consistently improved.
Efficient Task Allocation in Smart Warehouses with Multi-delivery Stations and Heterogeneous Robots
Feb 28, 2022
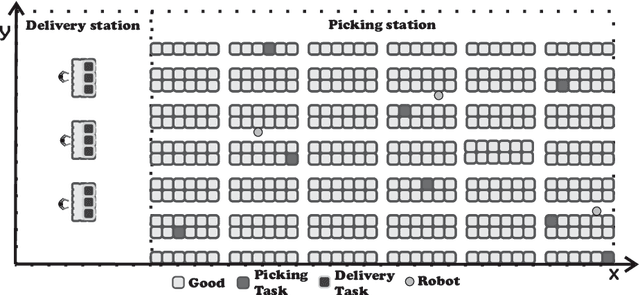
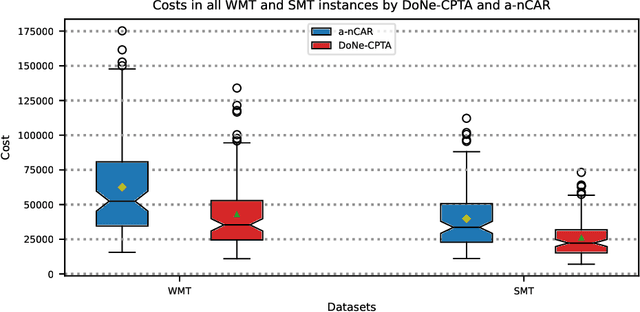
The task allocation problem in multi-robot systems (MRTA) is an NP-hard problem whose viable solutions are usually found by heuristic algorithms. Considering the increasing need of improvement on logistics, the use of robots for increasing the efficiency of logistics warehouses is becoming a requirement. In a smart warehouse the main tasks consist of employing a fleet of automated picking and mobile robots that coordinate by picking up items from a set of orders from the shelves and dropping them at the delivery stations. Two aspects generally justify multi-robot task allocation complexity: (i) environmental aspects, such as multi-delivery stations and dispersed robots (since they remain in constant motion) and (ii) fleet heterogeneity, where robots' traffic speed and capacity loads are different from each other. Despite these properties have been widely researched in the literature, they usually are investigated separately. This work proposes a scalable and efficient task allocation algorithm for smart warehouses with multi-delivery stations and heterogeneous fleets. Our strategy employs a novel cost estimator, which computes costs as a function of the robots' variable characteristics and capacity while they receive new tasks. For validating the strategy a series of experiments is performed simulating the operation of smart warehouses with multiple delivery stations and heteregenous fleets. The results show that our strategy generates routes costing up to $33$\% less than the routes generated by a state-of-the-art task allocation algorithm and $96$\% faster in test instances representing our target scenario. Considering single-delivery stations and non-dispersed robots, we reduced the number of robots by up to $18$\%, allocating tasks $92$\% faster, and generating routes whose costs are statistically similar to the routes generated by the state-of-the-art algorithm.
Better Classifier Calibration for Small Data Sets
Feb 24, 2020
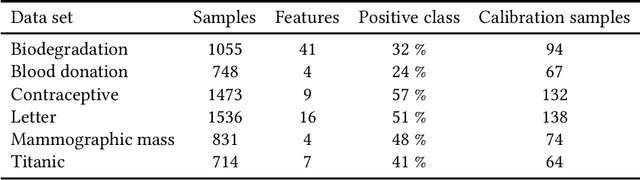
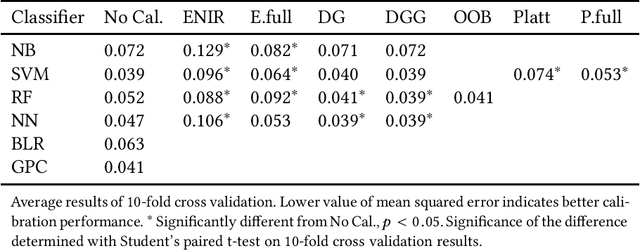
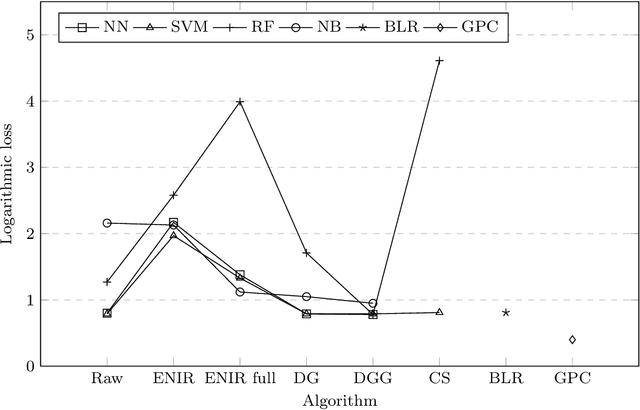
Classifier calibration does not always go hand in hand with the classifier's ability to separate the classes. There are applications where good classifier calibration, i.e. the ability to produce accurate probability estimates, is more important than class separation. When the amount of data for training is limited, the traditional approach to improve calibration starts to crumble. In this article we show how generating more data for calibration is able to improve calibration algorithm performance in many cases where a classifier is not naturally producing well-calibrated outputs and the traditional approach fails. The proposed approach adds computational cost but considering that the main use case is with small data sets this extra computational cost stays insignificant and is comparable to other methods in prediction time. From the tested classifiers the largest improvement was detected with the random forest and naive Bayes classifiers. Therefore, the proposed approach can be recommended at least for those classifiers when the amount of data available for training is limited and good calibration is essential.
Better Multi-class Probability Estimates for Small Data Sets
Jan 30, 2020

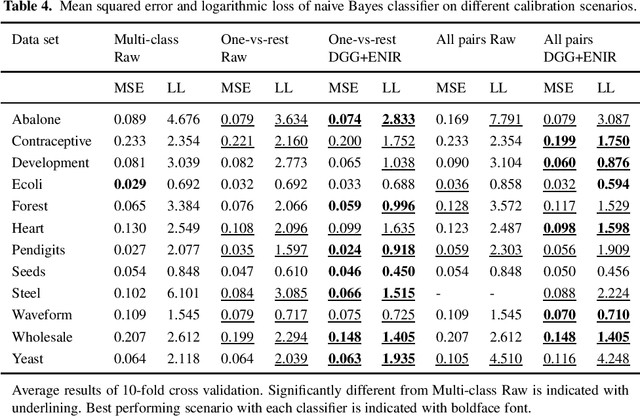
Many classification applications require accurate probability estimates in addition to good class separation but often classifiers are designed focusing only on the latter. Calibration is the process of improving probability estimates by post-processing but commonly used calibration algorithms work poorly on small data sets and assume the classification task to be binary. Both of these restrictions limit their real-world applicability. Previously introduced Data Generation and Grouping algorithm alleviates the problem posed by small data sets and in this article, we will demonstrate that its application to multi-class problems is also possible which solves the other limitation. Our experiments show that calibration error can be decreased using the proposed approach and the additional computational cost is acceptable.