 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Classifier Calibration for Small Data Sets
Feb 24, 2020
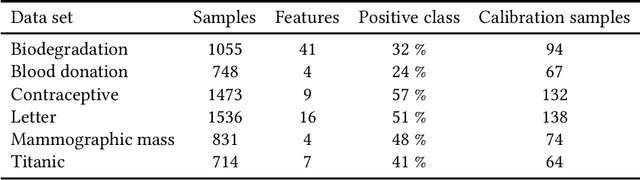
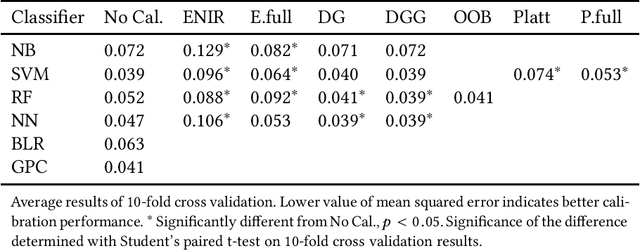
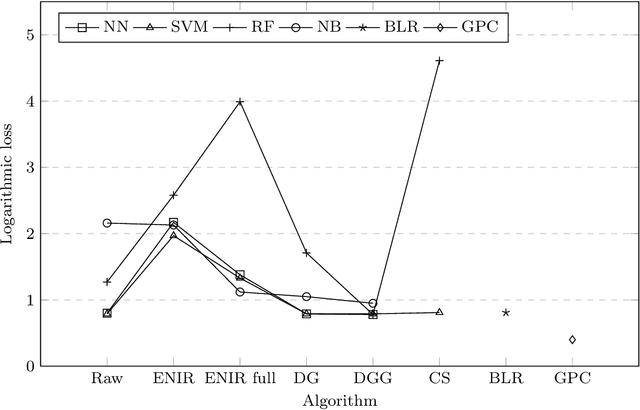
Classifier calibration does not always go hand in hand with the classifier's ability to separate the classes. There are applications where good classifier calibration, i.e. the ability to produce accurate probability estimates, is more important than class separation. When the amount of data for training is limited, the traditional approach to improve calibration starts to crumble. In this article we show how generating more data for calibration is able to improve calibration algorithm performance in many cases where a classifier is not naturally producing well-calibrated outputs and the traditional approach fails. The proposed approach adds computational cost but considering that the main use case is with small data sets this extra computational cost stays insignificant and is comparable to other methods in prediction time. From the tested classifiers the largest improvement was detected with the random forest and naive Bayes classifiers. Therefore, the proposed approach can be recommended at least for those classifiers when the amount of data available for training is limited and good calibration is essential.
Better Multi-class Probability Estimates for Small Data Sets
Jan 30, 2020
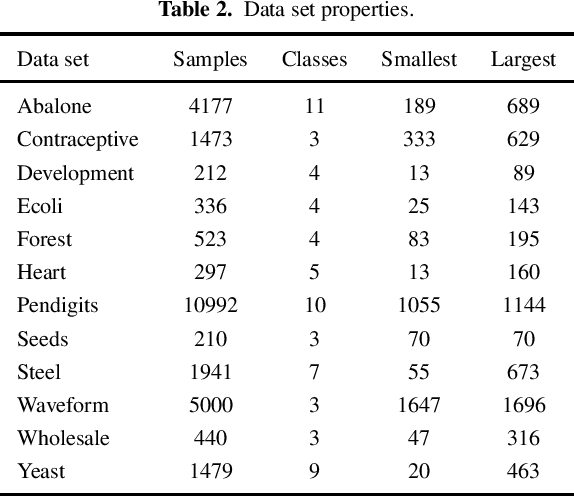

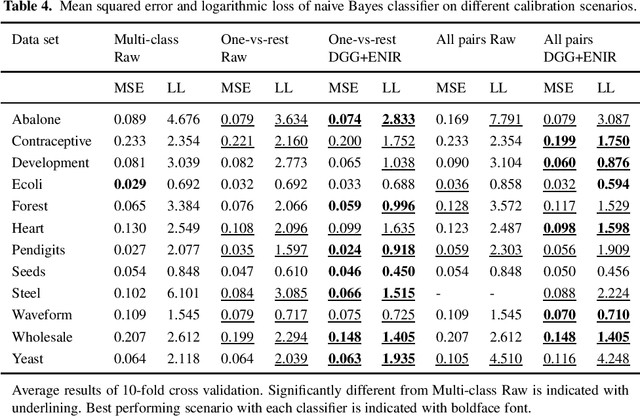
Many classification applications require accurate probability estimates in addition to good class separation but often classifiers are designed focusing only on the latter. Calibration is the process of improving probability estimates by post-processing but commonly used calibration algorithms work poorly on small data sets and assume the classification task to be binary. Both of these restrictions limit their real-world applicability. Previously introduced Data Generation and Grouping algorithm alleviates the problem posed by small data sets and in this article, we will demonstrate that its application to multi-class problems is also possible which solves the other limitation. Our experiments show that calibration error can be decreased using the proposed approach and the additional computational cost is acceptable.
Personalizing human activity recognition models using incremental learning
May 29, 2019
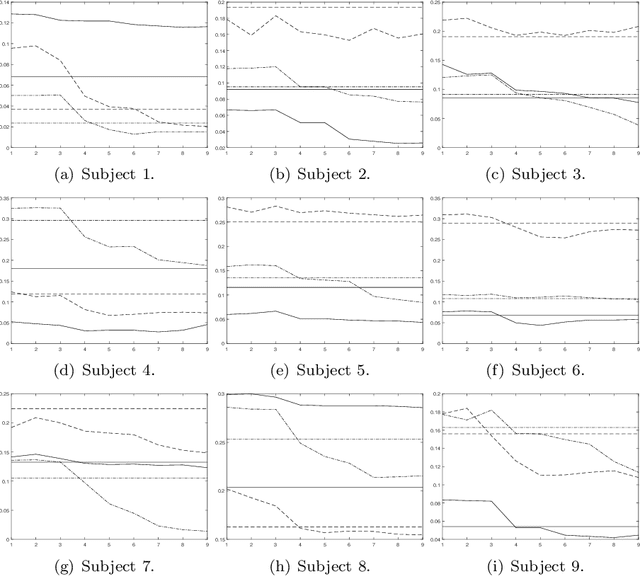
In this study, the aim is to personalize inertial sensor data-based human activity recognition models using incremental learning. At first, the recognition is based on user-independent model. However, when personal streaming data becomes available, the incremental learning-based recognition model can be updated, and therefore personalized, based on the data without user-interruption. The used incremental learning algorithm is Learn++ which is an ensemble method that can use any classifier as a base classifier. In fact, study compares three different base classifiers: linear discriminant analysis (LDA), quadratic discriminant analysis (QDA) and classification and regression tree (CART). Experiments are based on publicly open data set and they show that already a small personal training data set can improve the classification accuracy. Improvement using LDA as base classifier is 4.6 percentage units, using QDA 2.0 percentage units, and 2.3 percentage units using CART. However, if the user-independent model used in the first phase of the recognition process is not accurate enough, personalization cannot improve recognition accuracy.
From User-independent to Personal Human Activity Recognition Models Exploiting the Sensors of a Smartphone
May 29, 2019
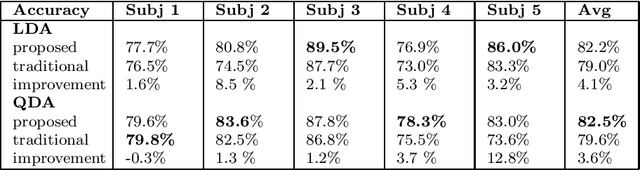
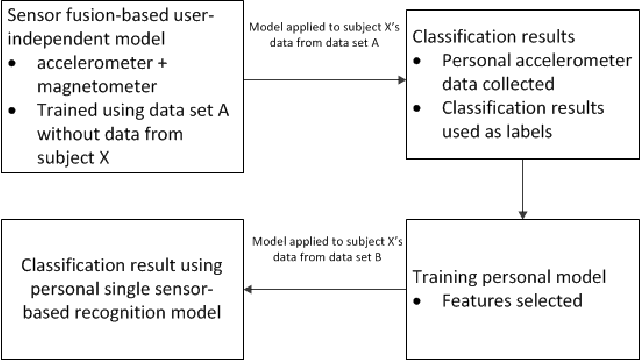

In this study, a novel method to obtain user-dependent human activity recognition models unobtrusively by exploiting the sensors of a smartphone is presented. The recognition consists of two models: sensor fusion-based user-independent model for data labeling and single sensor-based user-dependent model for final recognition. The functioning of the presented method is tested with human activity data set, including data from accelerometer and magnetometer, and with two classifiers. Comparison of the detection accuracies of the proposed method to traditional user-independent model shows that the presented method has potential, in nine cases out of ten it is better than the traditional method, but more experiments using different sensor combinations should be made to show the full potential of the method.
Importance of user inputs while using incremental learning to personalize human activity recognition models
May 28, 2019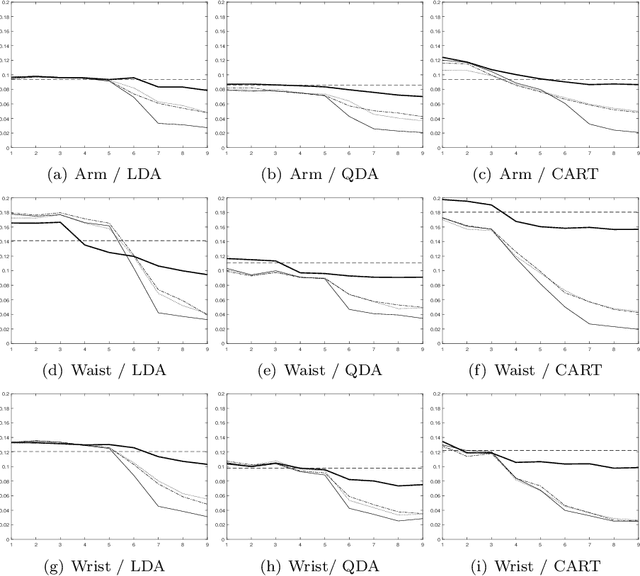
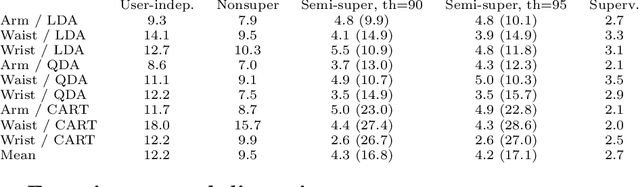
In this study, importance of user inputs is studied in the context of personalizing human activity recognition models using incremental learning. Inertial sensor data from three body positions are used, and the classification is based on Learn++ ensemble method. Three different approaches to update models are compared: non-supervised, semi-supervised and supervised. Non-supervised approach relies fully on predicted labels, supervised fully on user labeled data, and the proposed method for semi-supervised learning, is a combination of these two. In fact, our experiments show that by relying on predicted labels with high confidence, and asking the user to label only uncertain observations (from 12% to 26% of the observations depending on the used base classifier), almost as low error rates can be achieved as by using supervised approach. In fact, the difference was less than 2%-units. Moreover, unlike non-supervised approach, semi-supervised approach does not suffer from drastic concept drift, and thus, the error rate of the non-supervised approach is over 5%-units higher than using semi-supervised approach.