 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Aware Range Image-Based Model for Point Cloud Segmentation
Mar 19, 2025Point cloud segmentation (PCS) aims to separate points into different and meaningful groups. The task plays an important role in robotics because PCS enables robots to understand their physical environments directly. To process sparse and large-scale outdoor point clouds in real time, range image-based models are commonly adopted. However, in a range image, the lack of explicit depth information inevitably causes some separate objects in 3D space to touch each other, bringing difficulty for the range image-based models in correctly segmenting the objects. Moreover, previous PCS models are usually derived from the existing color image-based models and unable to make full use of the implicit but ordered depth information inherent in the range image, thereby achieving inferior performance. In this paper, we propose Depth-Aware Module (DAM) and Fast FMVNet V3. DAM perceives the ordered depth information in the range image by explicitly modelling the interdependence among channels. Fast FMVNet V3 incorporates DAM by integrating it into the last block in each architecture stage. Extensive experiments conducted on SemanticKITTI, nuScenes, and SemanticPOSS demonstrate that DAM brings a significant improvement for Fast FMVNet V3 with negligible computational cost.
An Experimental Study of SOTA LiDAR Segmentation Models
Feb 18, 2025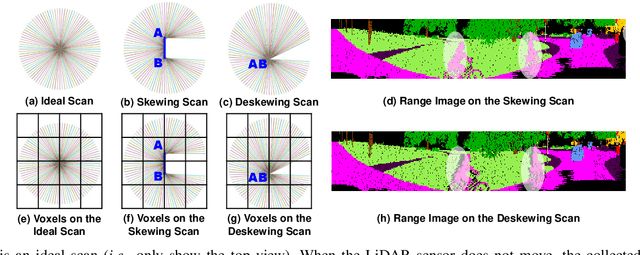
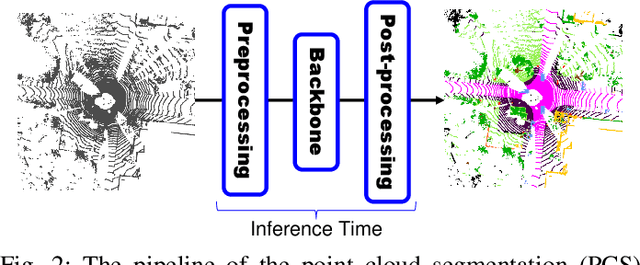
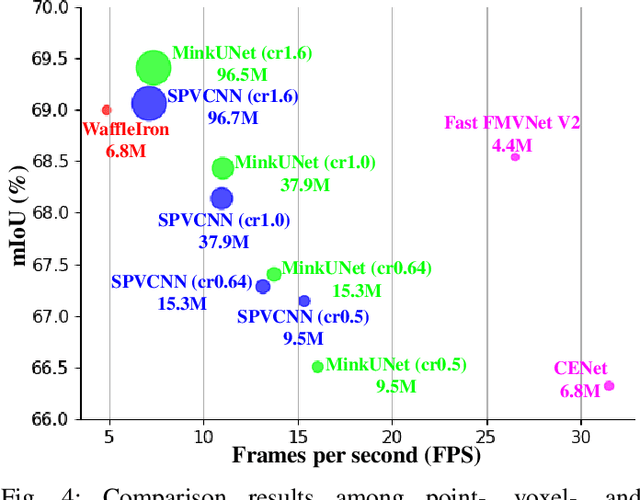
Point cloud segmentation (PCS) is to classify each point in point clouds. The task enables robots to parse their 3D surroundings and run autonomously. According to different point cloud representations, existing PCS models can be roughly divided into point-, voxel-, and range image-based models. However, no work has been found to report comprehensive comparisons among the state-of-the-art point-, voxel-, and range image-based models from an application perspective, bringing difficulty in utilizing these models for real-world scenarios. In this paper, we provide thorough comparisons among the models by considering the LiDAR data motion compensation and the metrics of model parameters, max GPU memory allocated during testing, inference latency, frames per second, intersection-over-union (IoU) and mean IoU (mIoU) scores. The experimental results benefit engineers when choosing a reasonable PCS model for an application and inspire researchers in the PCS field to design more practical models for a real-world scenario.
Trainable Pointwise Decoder Module for Point Cloud Segmentation
Aug 02, 2024



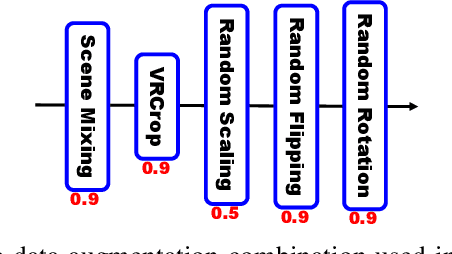
Point cloud segmentation (PCS) aims to make per-point predictions and enables robots and autonomous driving cars to understand the environment. The range image is a dense representation of a large-scale outdoor point cloud, and segmentation models built upon the image commonly execute efficiently. However, the projection of the point cloud onto the range image inevitably leads to dropping points because, at each image coordinate, only one point is kept despite multiple points being projected onto the same location. More importantly, it is challenging to assign correct predictions to the dropped points that belong to the classes different from the kept point class. Besides, existing post-processing methods, such as K-nearest neighbor (KNN) search and kernel point convolution (KPConv), cannot be trained with the models in an end-to-end manner or cannot process varying-density outdoor point clouds well, thereby enabling the models to achieve sub-optimal performance. To alleviate this problem, we propose a trainable pointwise decoder module (PDM) as the post-processing approach, which gathers weighted features from the neighbors and then makes the final prediction for the query point. In addition, we introduce a virtual range image-guided copy-rotate-paste (VRCrop) strategy in data augmentation. VRCrop constrains the total number of points and eliminates undesirable artifacts in the augmented point cloud. With PDM and VRCrop, existing range image-based segmentation models consistently perform better than their counterparts on the SemanticKITTI, SemanticPOSS, and nuScenes datasets.