 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLung2Lung: Volumetric Style Transfer with Self-Ensembling for High-Resolution Cross-Volume Computed Tomography
Oct 06, 2022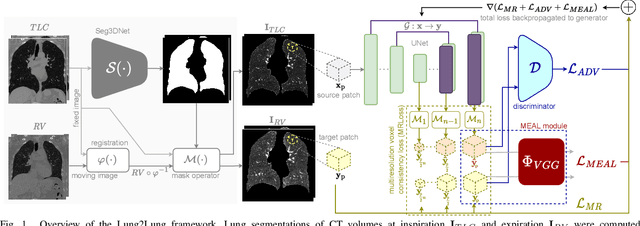
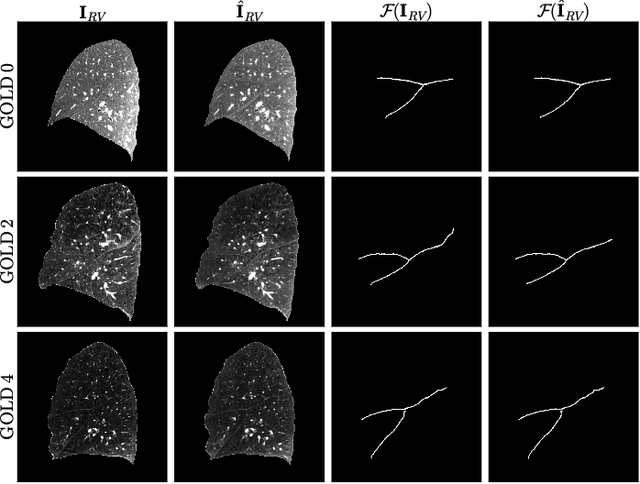
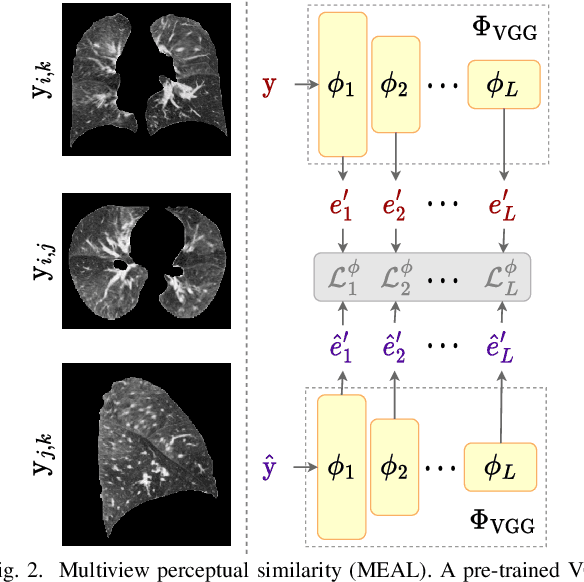

Chest computed tomography (CT) at inspiration is often complemented by an expiratory CT for identifying peripheral airways disease in the form of air trapping. Additionally, co-registered inspiratory-expiratory volumes are used to derive several clinically relevant measures of local lung function. Acquiring CT at different volumes, however, increases radiation dosage, acquisition time, and may not be achievable due to various complications, limiting the utility of registration-based measures, To address this, we propose Lung2Lung - a style-based generative adversarial approach for translating CT images from end-inspiratory to end-expiratory volume. Lung2Lung addresses several limitations of the traditional generative models including slicewise discontinuities, limited size of generated volumes, and their inability to model neural style at a volumetric level. We introduce multiview perceptual similarity (MEAL) to capture neural styles in 3D. To incorporate global information into the training process and refine the output of our model, we also propose self-ensembling (SE). Lung2Lung, with MEAL and SE, is able to generate large 3D volumes of size 320 x 320 x 320 that are validated using a diverse cohort of 1500 subjects with varying disease severity. The model shows superior performance against several state-of-the-art 2D and 3D generative models with a peak-signal-to-noise ratio of 24.53 dB and structural similarity of 0.904. Clinical validation shows that the synthetic volumes can be used to reliably extract several clinical endpoints of chronic obstructive pulmonary disease.
Localization supervision of chest x-ray classifiers using label-specific eye-tracking annotation
Jul 20, 2022

Convolutional neural networks (CNNs) have been successfully applied to chest x-ray (CXR) images. Moreover, annotated bounding boxes have been shown to improve the interpretability of a CNN in terms of localizing abnormalities. However, only a few relatively small CXR datasets containing bounding boxes are available, and collecting them is very costly. Opportunely, eye-tracking (ET) data can be collected in a non-intrusive way during the clinical workflow of a radiologist. We use ET data recorded from radiologists while dictating CXR reports to train CNNs. We extract snippets from the ET data by associating them with the dictation of keywords and use them to supervise the localization of abnormalities. We show that this method improves a model's interpretability without impacting its image-level classification.
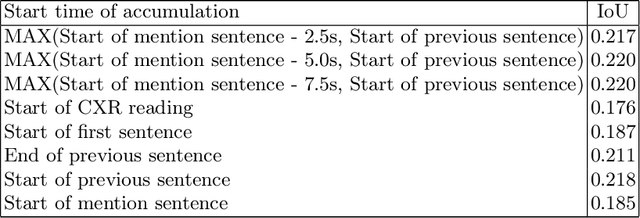
Comparing radiologists' gaze and saliency maps generated by interpretability methods for chest x-rays
Dec 22, 2021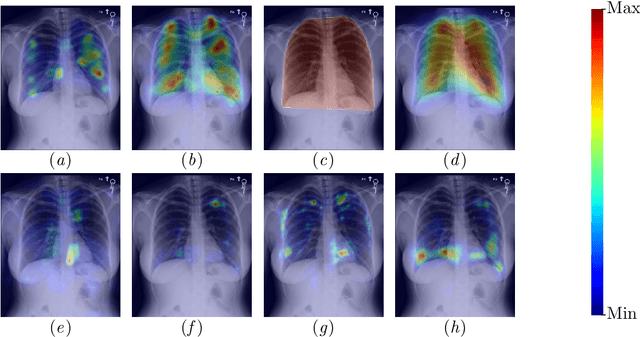
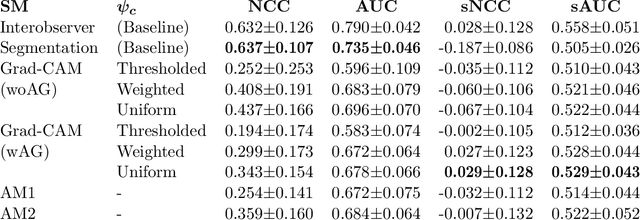
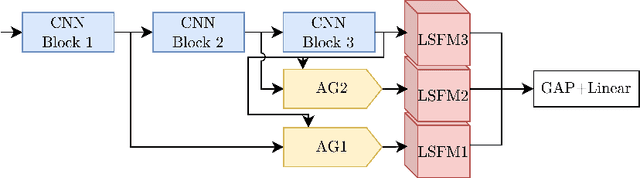
The interpretability of medical image analysis models is considered a key research field. We use a dataset of eye-tracking data from five radiologists to compare the outputs of interpretability methods against the heatmaps representing where radiologists looked. We conduct a class-independent analysis of the saliency maps generated by two methods selected from the literature: Grad-CAM and attention maps from an attention-gated model. For the comparison, we use shuffled metrics, which avoid biases from fixation locations. We achieve scores comparable to an interobserver baseline in one shuffled metric, highlighting the potential of saliency maps from Grad-CAM to mimic a radiologist's attention over an image. We also divide the dataset into subsets to evaluate in which cases similarities are higher.
Single volume lung biomechanics from chest computed tomography using a mode preserving generative adversarial network
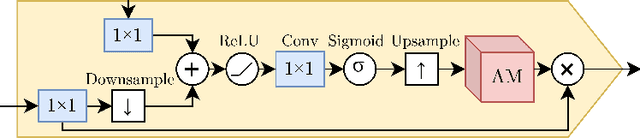
Oct 15, 2021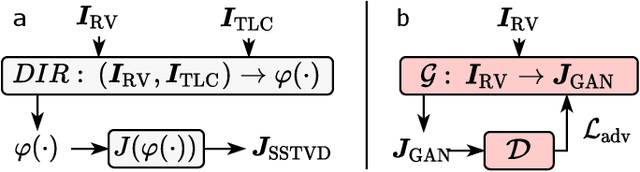
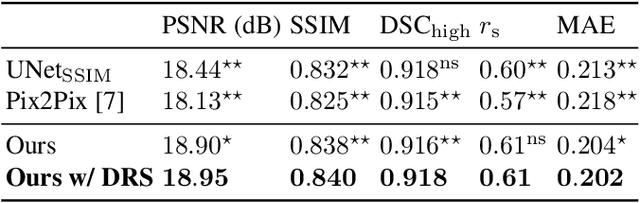

Local tissue expansion of the lungs is typically derived by registering computed tomography (CT) scans acquired at multiple lung volumes. However, acquiring multiple scans incurs increased radiation dose, time, and cost, and may not be possible in many cases, thus restricting the applicability of registration-based biomechanics. We propose a generative adversarial learning approach for estimating local tissue expansion directly from a single CT scan. The proposed framework was trained and evaluated on 2500 subjects from the SPIROMICS cohort. Once trained, the framework can be used as a registration-free method for predicting local tissue expansion. We evaluated model performance across varying degrees of disease severity and compared its performance with two image-to-image translation frameworks - UNet and Pix2Pix. Our model achieved an overall PSNR of 18.95 decibels, SSIM of 0.840, and Spearman's correlation of 0.61 at a high spatial resolution of 1 mm3.
REFLACX, a dataset of reports and eye-tracking data for localization of abnormalities in chest x-rays
Sep 29, 2021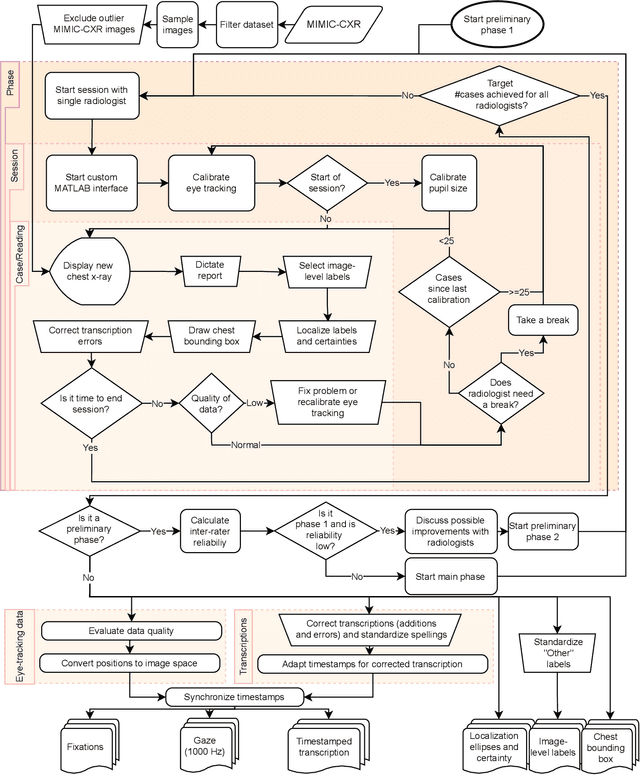


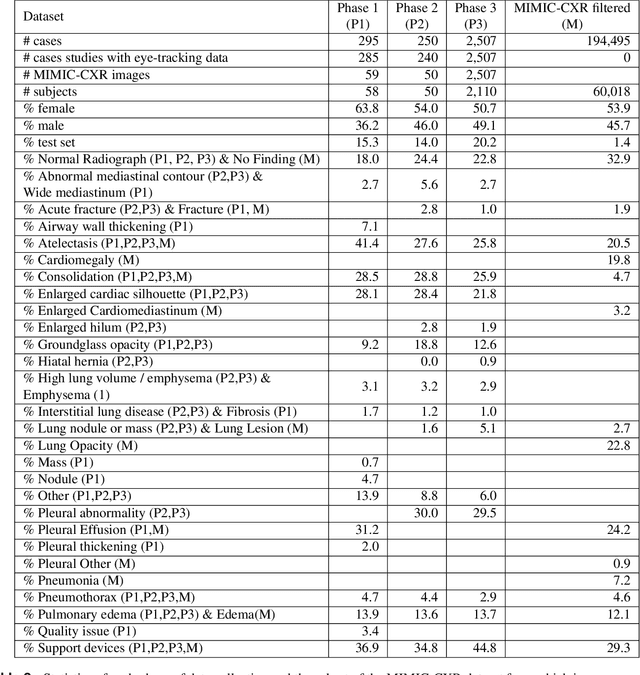
Deep learning has shown recent success in classifying anomalies in chest x-rays, but datasets are still small compared to natural image datasets. Supervision of abnormality localization has been shown to improve trained models, partially compensating for dataset sizes. However, explicitly labeling these anomalies requires an expert and is very time-consuming. We propose a method for collecting implicit localization data using an eye tracker to capture gaze locations and a microphone to capture a dictation of a report, imitating the setup of a reading room, and potentially scalable for large datasets. The resulting REFLACX (Reports and Eye-Tracking Data for Localization of Abnormalities in Chest X-rays) dataset was labeled by five radiologists and contains 3,032 synchronized sets of eye-tracking data and timestamped report transcriptions. We also provide bounding boxes around lungs and heart and validation labels consisting of ellipses localizing abnormalities and image-level labels. Furthermore, a small subset of the data contains readings from all radiologists, allowing for the calculation of inter-rater scores.
Quantifying the Preferential Direction of the Model Gradient in Adversarial Training With Projected Gradient Descent
Sep 10, 2020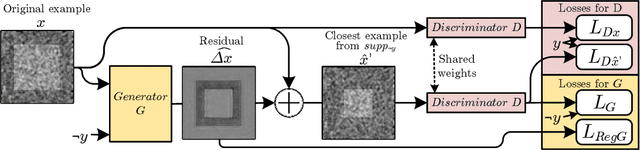

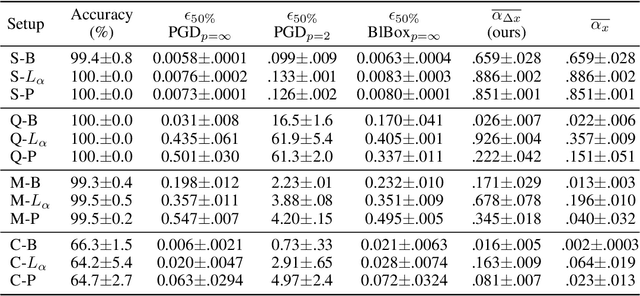
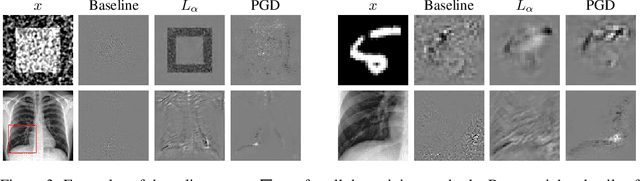
Adversarial training, especially projected gradient descent (PGD), has been the most successful approach for improving robustness against adversarial attacks. After adversarial training, gradients of models with respect to their inputs are meaningful and interpretable by humans. However, the concept of interpretability is not mathematically well established, making it difficult to evaluate it quantitatively. We define interpretability as the alignment of the model gradient with the vector pointing toward the closest point of the support of the other class. We propose a method for measuring this alignment for binary classification problems, using generative adversarial model training to produce the smallest residual needed to change the class present in the image. We show that PGD-trained models are more interpretable than the baseline according to our definition, and our metric presents higher alignment values than a competing metric formulation. We also show that enforcing this alignment increases the robustness of models without adversarial training.
Interpretation of Disease Evidence for Medical Images Using Adversarial Deformation Fields
Jul 04, 2020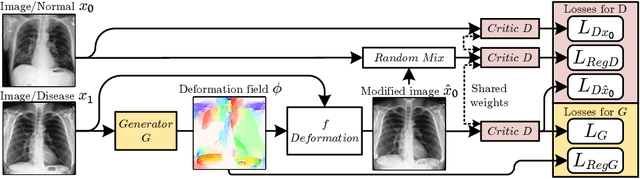
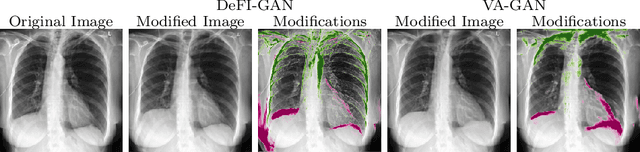
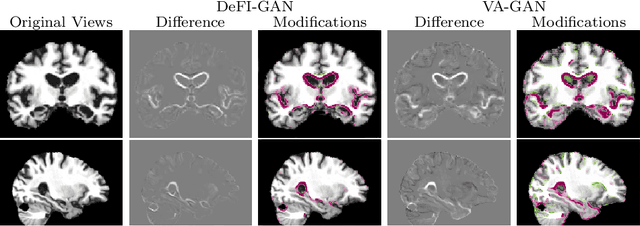

The high complexity of deep learning models is associated with the difficulty of explaining what evidence they recognize as correlating with specific disease labels. This information is critical for building trust in models and finding their biases. Until now, automated deep learning visualization solutions have identified regions of images used by classifiers, but these solutions are too coarse, too noisy, or have a limited representation of the way images can change. We propose a novel method for formulating and presenting spatial explanations of disease evidence, called deformation field interpretation with generative adversarial networks (DeFI-GAN). An adversarially trained generator produces deformation fields that modify images of diseased patients to resemble images of healthy patients. We validate the method studying chronic obstructive pulmonary disease (COPD) evidence in chest x-rays (CXRs) and Alzheimer's disease (AD) evidence in brain MRIs. When extracting disease evidence in longitudinal data, we show compelling results against a baseline producing difference maps. DeFI-GAN also highlights disease biomarkers not found by previous methods and potential biases that may help in investigations of the dataset and of the adopted learning methods.
Adversarial regression training for visualizing the progression of chronic obstructive pulmonary disease with chest x-rays
Aug 27, 2019
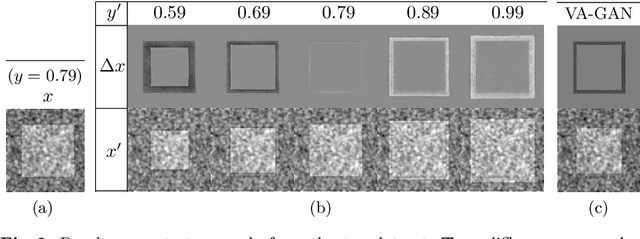

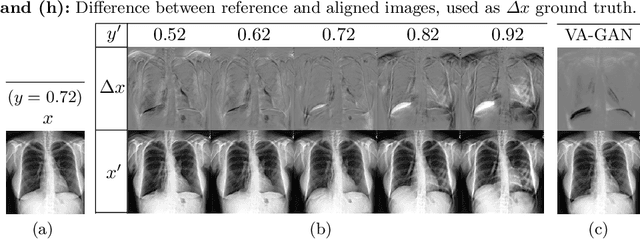
Knowledge of what spatial elements of medical images deep learning methods use as evidence is important for model interpretability, trustiness, and validation. There is a lack of such techniques for models in regression tasks. We propose a method, called visualization for regression with a generative adversarial network (VR-GAN), for formulating adversarial training specifically for datasets containing regression target values characterizing disease severity. We use a conditional generative adversarial network where the generator attempts to learn to shift the output of a regressor through creating disease effect maps that are added to the original images. Meanwhile, the regressor is trained to predict the original regression value for the modified images. A model trained with this technique learns to provide visualization for how the image would appear at different stages of the disease. We analyze our method in a dataset of chest x-rays associated with pulmonary function tests, used for diagnosing chronic obstructive pulmonary disease (COPD). For validation, we compute the difference of two registered x-rays of the same patient at different time points and correlate it to the generated disease effect map. The proposed method outperforms a technique based on classification and provides realistic-looking images, making modifications to images following what radiologists usually observe for this disease. Implementation code is available at https://github.com/ricbl/vrgan.