 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Mistake Bounds for Transductive Online Learning
Dec 14, 2025We resolve a 30-year-old open problem concerning the power of unlabeled data in online learning by tightly quantifying the gap between transductive and standard online learning. In the standard setting, the optimal mistake bound is characterized by the Littlestone dimension $d$ of the concept class $H$ (Littlestone 1987). We prove that in the transductive setting, the mistake bound is at least $Ω(\sqrt{d})$. This constitutes an exponential improvement over previous lower bounds of $Ω(\log\log d)$, $Ω(\sqrt{\log d})$, and $Ω(\log d)$, due respectively to Ben-David, Kushilevitz, and Mansour (1995, 1997) and Hanneke, Moran, and Shafer (2023). We also show that this lower bound is tight: for every $d$, there exists a class of Littlestone dimension $d$ with transductive mistake bound $O(\sqrt{d})$. Our upper bound also improves upon the best known upper bound of $(2/3)d$ from Ben-David, Kushilevitz, and Mansour (1997). These results establish a quadratic gap between transductive and standard online learning, thereby highlighting the benefit of advance access to the unlabeled instance sequence. This contrasts with the PAC setting, where transductive and standard learning exhibit similar sample complexities.
Oblivious Defense in ML Models: Backdoor Removal without Detection
Nov 05, 2024
As society grows more reliant on machine learning, ensuring the security of machine learning systems against sophisticated attacks becomes a pressing concern. A recent result of Goldwasser, Kim, Vaikuntanathan, and Zamir (2022) shows that an adversary can plant undetectable backdoors in machine learning models, allowing the adversary to covertly control the model's behavior. Backdoors can be planted in such a way that the backdoored machine learning model is computationally indistinguishable from an honest model without backdoors. In this paper, we present strategies for defending against backdoors in ML models, even if they are undetectable. The key observation is that it is sometimes possible to provably mitigate or even remove backdoors without needing to detect them, using techniques inspired by the notion of random self-reducibility. This depends on properties of the ground-truth labels (chosen by nature), and not of the proposed ML model (which may be chosen by an attacker). We give formal definitions for secure backdoor mitigation, and proceed to show two types of results. First, we show a "global mitigation" technique, which removes all backdoors from a machine learning model under the assumption that the ground-truth labels are close to a Fourier-heavy function. Second, we consider distributions where the ground-truth labels are close to a linear or polynomial function in $\mathbb{R}^n$. Here, we show "local mitigation" techniques, which remove backdoors with high probability for every inputs of interest, and are computationally cheaper than global mitigation. All of our constructions are black-box, so our techniques work without needing access to the model's representation (i.e., its code or parameters). Along the way we prove a simple result for robust mean estimation.
Which Algorithms Have Tight Generalization Bounds?
Oct 02, 2024



We study which machine learning algorithms have tight generalization bounds. First, we present conditions that preclude the existence of tight generalization bounds. Specifically, we show that algorithms that have certain inductive biases that cause them to be unstable do not admit tight generalization bounds. Next, we show that algorithms that are sufficiently stable do have tight generalization bounds. We conclude with a simple characterization that relates the existence of tight generalization bounds to the conditional variance of the algorithm's loss.
A Trichotomy for Transductive Online Learning
Nov 29, 2023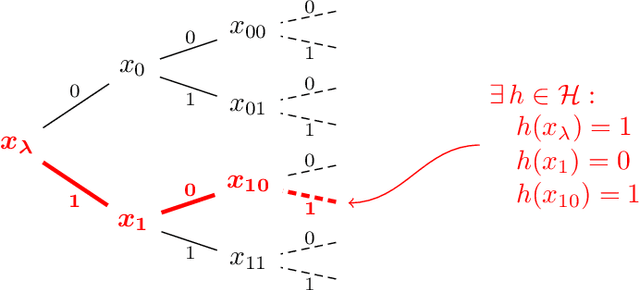
We present new upper and lower bounds on the number of learner mistakes in the `transductive' online learning setting of Ben-David, Kushilevitz and Mansour (1997). This setting is similar to standard online learning, except that the adversary fixes a sequence of instances $x_1,\dots,x_n$ to be labeled at the start of the game, and this sequence is known to the learner. Qualitatively, we prove a trichotomy, stating that the minimal number of mistakes made by the learner as $n$ grows can take only one of precisely three possible values: $n$, $\Theta\left(\log (n)\right)$, or $\Theta(1)$. Furthermore, this behavior is determined by a combination of the VC dimension and the Littlestone dimension. Quantitatively, we show a variety of bounds relating the number of mistakes to well-known combinatorial dimensions. In particular, we improve the known lower bound on the constant in the $\Theta(1)$ case from $\Omega\left(\sqrt{\log(d)}\right)$ to $\Omega(\log(d))$ where $d$ is the Littlestone dimension. Finally, we extend our results to cover multiclass classification and the agnostic setting.
The Bayesian Stability Zoo
Oct 27, 2023We show that many definitions of stability found in the learning theory literature are equivalent to one another. We distinguish between two families of definitions of stability: distribution-dependent and distribution-independent Bayesian stability. Within each family, we establish equivalences between various definitions, encompassing approximate differential privacy, pure differential privacy, replicability, global stability, perfect generalization, TV stability, mutual information stability, KL-divergence stability, and R\'enyi-divergence stability. Along the way, we prove boosting results that enable the amplification of the stability of a learning rule. This work is a step towards a more systematic taxonomy of stability notions in learning theory, which can promote clarity and an improved understanding of an array of stability concepts that have emerged in recent years.
Fantastic Generalization Measures are Nowhere to be Found
Sep 24, 2023

Numerous generalization bounds have been proposed in the literature as potential explanations for the ability of neural networks to generalize in the overparameterized setting. However, none of these bounds are tight. For instance, in their paper ``Fantastic Generalization Measures and Where to Find Them'', Jiang et al. (2020) examine more than a dozen generalization bounds, and show empirically that none of them imply guarantees that can explain the remarkable performance of neural networks. This raises the question of whether tight generalization bounds are at all possible. We consider two types of generalization bounds common in the literature: (1) bounds that depend on the training set and the output of the learning algorithm. There are multiple bounds of this type in the literature (e.g., norm-based and margin-based bounds), but we prove mathematically that no such bound can be uniformly tight in the overparameterized setting; (2) bounds that depend on the training set and on the learning algorithm (e.g., stability bounds). For these bounds, we show a trade-off between the algorithm's performance and the bound's tightness. Namely, if the algorithm achieves good accuracy on certain distributions in the overparameterized setting, then no generalization bound can be tight for it. We conclude that generalization bounds in the overparameterized setting cannot be tight without suitable assumptions on the population distribution.
PAC Verification of Statistical Algorithms
Nov 28, 2022Goldwasser et al.\ (2021) recently proposed the setting of PAC verification, where a hypothesis (machine learning model) that purportedly satisfies the agnostic PAC learning objective is verified using an interactive proof. In this paper we develop this notion further in a number of ways. First, we prove a lower bound for PAC verification of $\Omega(\sqrt{d})$ i.i.d.\ samples for hypothesis classes of VC dimension $d$. Second, we present a protocol for PAC verification of unions of intervals over $\mathbb{R}$ that improves upon their proposed protocol for that task, and matches our lower bound. Third, we introduce a natural generalization of their definition to verification of general statistical algorithms, which is applicable to a wider variety of practical algorithms beyond agnostic PAC learning. Showcasing our proposed definition, our final result is a protocol for the verification of statistical query algorithms that satisfy a combinatorial constraint on their queries.
Fine-Grained Distribution-Dependent Learning Curves
Aug 31, 2022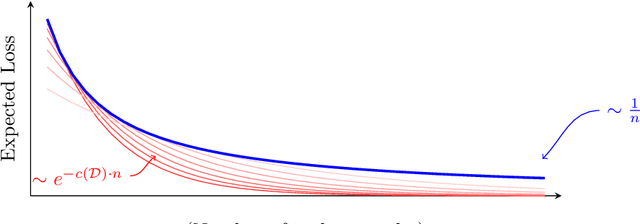
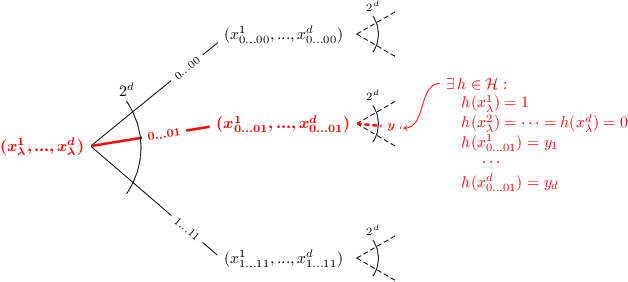
Learning curves plot the expected error of a learning algorithm as a function of the number of labeled input samples. They are widely used by machine learning practitioners as a measure of an algorithm's performance, but classic PAC learning theory cannot explain their behavior. In this paper we introduce a new combinatorial characterization called the VCL dimension that improves and refines the recent results of Bousquet et al. (2021). Our characterization sheds new light on the structure of learning curves by providing fine-grained bounds, and showing that for classes with finite VCL, the rate of decay can be decomposed into a linear component that depends only on the hypothesis class and an exponential component that depends also on the target distribution. In particular, the finer nuance of the VCL dimension implies lower bounds that are quantitatively stronger than the bounds of Bousquet et al. (2021) and qualitatively stronger than classic 'no free lunch' lower bounds. The VCL characterization solves an open problem studied by Antos and Lugosi (1998), who asked in what cases such lower bounds exist. As a corollary, we recover their lower bound for half-spaces in $\mathbb{R}^d$, and we do so in a principled way that should be applicable to other cases as well. Finally, to provide another viewpoint on our work and how it compares to traditional PAC learning bounds, we also present an alternative formulation of our results in a language that is closer to the PAC setting.
A Direct Sum Result for the Information Complexity of Learning
Apr 16, 2018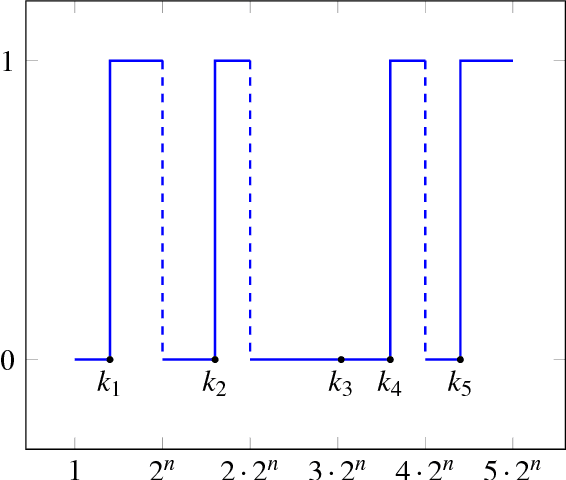
How many bits of information are required to PAC learn a class of hypotheses of VC dimension $d$? The mathematical setting we follow is that of Bassily et al. (2018), where the value of interest is the mutual information $\mathrm{I}(S;A(S))$ between the input sample $S$ and the hypothesis outputted by the learning algorithm $A$. We introduce a class of functions of VC dimension $d$ over the domain $\mathcal{X}$ with information complexity at least $\Omega\left(d\log \log \frac{|\mathcal{X}|}{d}\right)$ bits for any consistent and proper algorithm (deterministic or random). Bassily et al. proved a similar (but quantitatively weaker) result for the case $d=1$. The above result is in fact a special case of a more general phenomenon we explore. We define the notion of information complexity of a given class of functions $\mathcal{H}$. Intuitively, it is the minimum amount of information that an algorithm for $\mathcal{H}$ must retain about its input to ensure consistency and properness. We prove a direct sum result for information complexity in this context; roughly speaking, the information complexity sums when combining several classes.
Learners that Use Little Information
Feb 28, 2018We study learning algorithms that are restricted to using a small amount of information from their input sample. We introduce a category of learning algorithms we term $d$-bit information learners, which are algorithms whose output conveys at most $d$ bits of information of their input. A central theme in this work is that such algorithms generalize. We focus on the learning capacity of these algorithms, and prove sample complexity bounds with tight dependencies on the confidence and error parameters. We also observe connections with well studied notions such as sample compression schemes, Occam's razor, PAC-Bayes and differential privacy. We discuss an approach that allows us to prove upper bounds on the amount of information that algorithms reveal about their inputs, and also provide a lower bound by showing a simple concept class for which every (possibly randomized) empirical risk minimizer must reveal a lot of information. On the other hand, we show that in the distribution-dependent setting every VC class has empirical risk minimizers that do not reveal a lot of information.