 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOblivious Defense in ML Models: Backdoor Removal without Detection
Paper and Code
Nov 05, 2024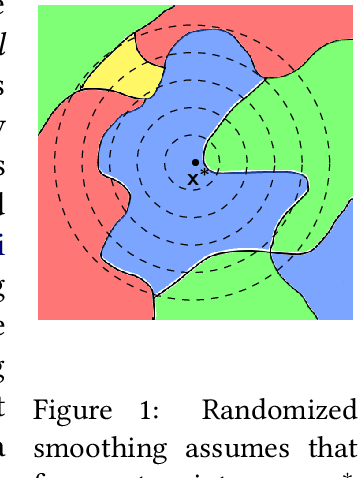
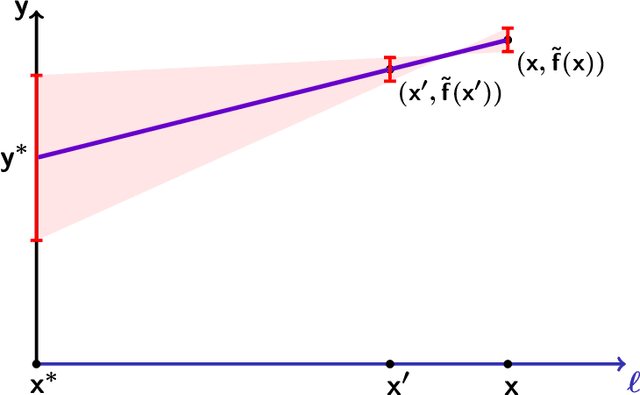
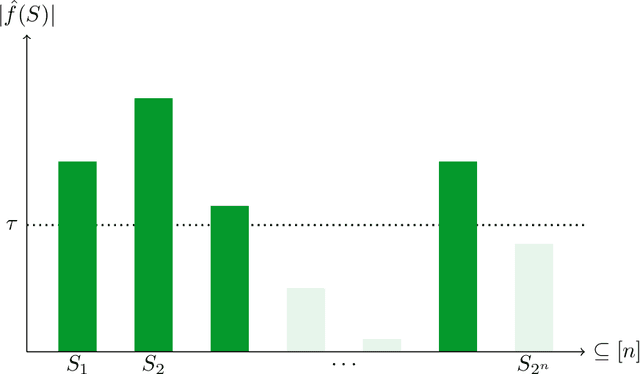
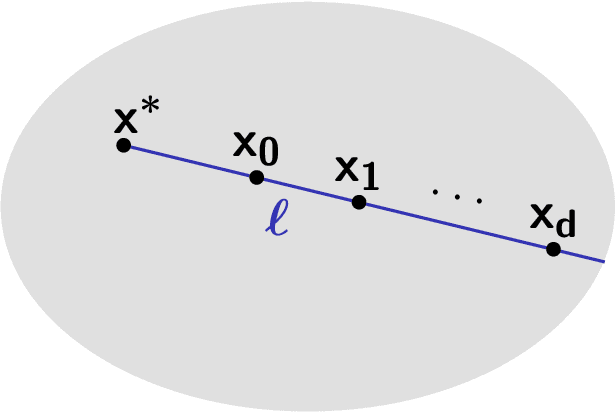
As society grows more reliant on machine learning, ensuring the security of machine learning systems against sophisticated attacks becomes a pressing concern. A recent result of Goldwasser, Kim, Vaikuntanathan, and Zamir (2022) shows that an adversary can plant undetectable backdoors in machine learning models, allowing the adversary to covertly control the model's behavior. Backdoors can be planted in such a way that the backdoored machine learning model is computationally indistinguishable from an honest model without backdoors. In this paper, we present strategies for defending against backdoors in ML models, even if they are undetectable. The key observation is that it is sometimes possible to provably mitigate or even remove backdoors without needing to detect them, using techniques inspired by the notion of random self-reducibility. This depends on properties of the ground-truth labels (chosen by nature), and not of the proposed ML model (which may be chosen by an attacker). We give formal definitions for secure backdoor mitigation, and proceed to show two types of results. First, we show a "global mitigation" technique, which removes all backdoors from a machine learning model under the assumption that the ground-truth labels are close to a Fourier-heavy function. Second, we consider distributions where the ground-truth labels are close to a linear or polynomial function in $\mathbb{R}^n$. Here, we show "local mitigation" techniques, which remove backdoors with high probability for every inputs of interest, and are computationally cheaper than global mitigation. All of our constructions are black-box, so our techniques work without needing access to the model's representation (i.e., its code or parameters). Along the way we prove a simple result for robust mean estimation.