 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Distribution-Dependent Learning Curves
Paper and Code
Aug 31, 2022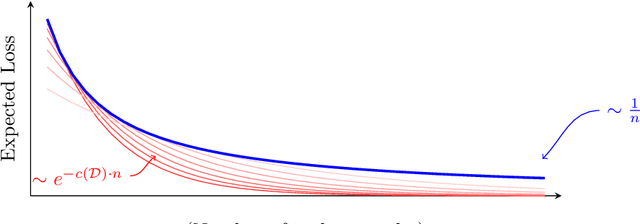
Learning curves plot the expected error of a learning algorithm as a function of the number of labeled input samples. They are widely used by machine learning practitioners as a measure of an algorithm's performance, but classic PAC learning theory cannot explain their behavior. In this paper we introduce a new combinatorial characterization called the VCL dimension that improves and refines the recent results of Bousquet et al. (2021). Our characterization sheds new light on the structure of learning curves by providing fine-grained bounds, and showing that for classes with finite VCL, the rate of decay can be decomposed into a linear component that depends only on the hypothesis class and an exponential component that depends also on the target distribution. In particular, the finer nuance of the VCL dimension implies lower bounds that are quantitatively stronger than the bounds of Bousquet et al. (2021) and qualitatively stronger than classic 'no free lunch' lower bounds. The VCL characterization solves an open problem studied by Antos and Lugosi (1998), who asked in what cases such lower bounds exist. As a corollary, we recover their lower bound for half-spaces in $\mathbb{R}^d$, and we do so in a principled way that should be applicable to other cases as well. Finally, to provide another viewpoint on our work and how it compares to traditional PAC learning bounds, we also present an alternative formulation of our results in a language that is closer to the PAC setting.