 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Stochastic Variance Reduced Ensemble Adversarial Attack for Boosting the Adversarial Transferability
Nov 21, 2021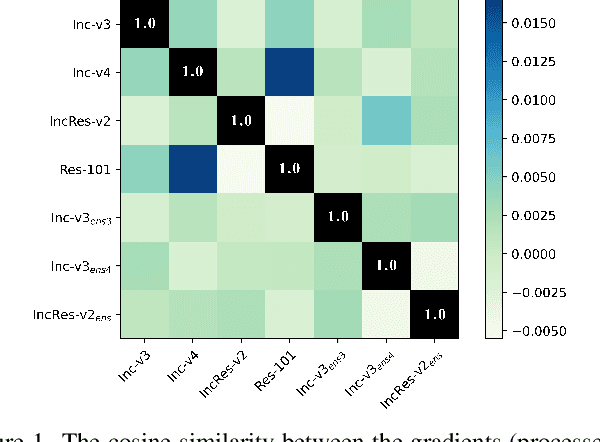
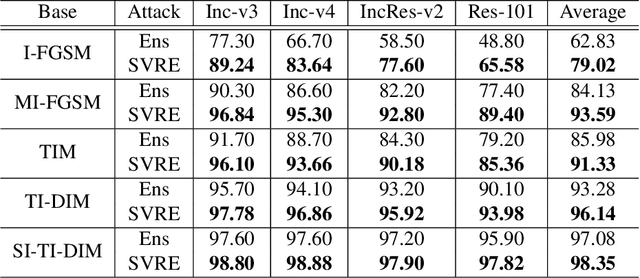
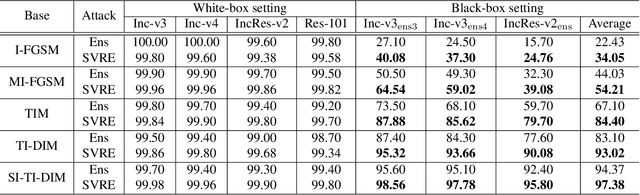
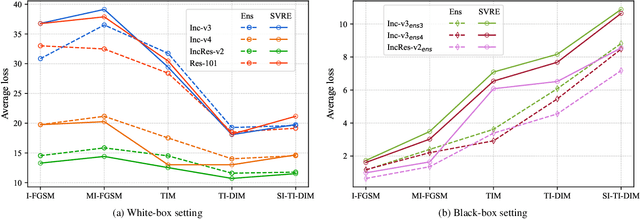
The black-box adversarial attack has attracted impressive attention for its practical use in the field of deep learning security, meanwhile, it is very challenging as there is no access to the network architecture or internal weights of the target model. Based on the hypothesis that if an example remains adversarial for multiple models, then it is more likely to transfer the attack capability to other models, the ensemble-based adversarial attack methods are efficient and widely used for black-box attacks. However, ways of ensemble attack are rather less investigated, and existing ensemble attacks simply fuse the outputs of all the models evenly. In this work, we treat the iterative ensemble attack as a stochastic gradient descent optimization process, in which the variance of the gradients on different models may lead to poor local optima. To this end, we propose a novel attack method called the stochastic variance reduced ensemble (SVRE) attack, which could reduce the gradient variance of the ensemble models and take full advantage of the ensemble attack. Empirical results on the standard ImageNet dataset demonstrate that the proposed method could boost the adversarial transferability and outperforms existing ensemble attacks significantly.
Adversarial Attacks on ML Defense Models Competition
Oct 15, 2021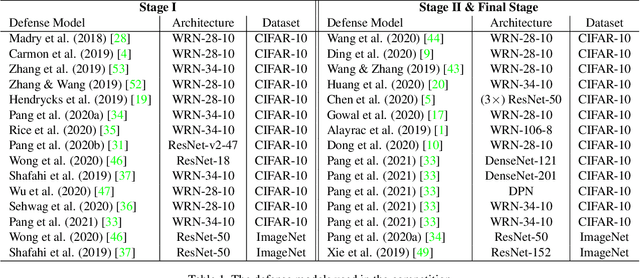
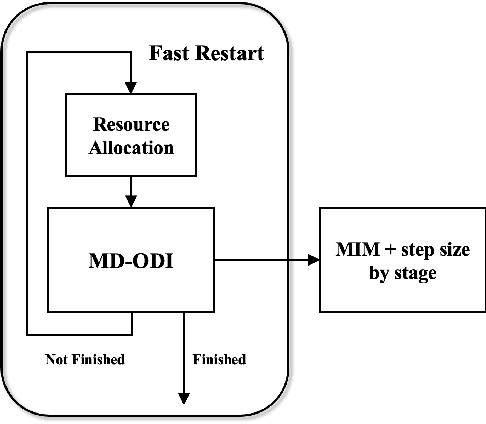
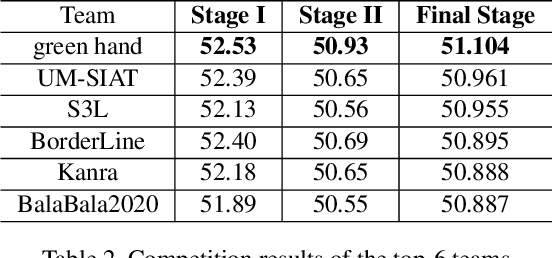
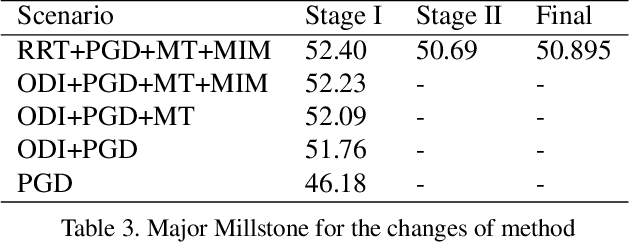
Due to the vulnerability of deep neural networks (DNNs) to adversarial examples, a large number of defense techniques have been proposed to alleviate this problem in recent years. However, the progress of building more robust models is usually hampered by the incomplete or incorrect robustness evaluation. To accelerate the research on reliable evaluation of adversarial robustness of the current defense models in image classification, the TSAIL group at Tsinghua University and the Alibaba Security group organized this competition along with a CVPR 2021 workshop on adversarial machine learning (https://aisecure-workshop.github.io/amlcvpr2021/). The purpose of this competition is to motivate novel attack algorithms to evaluate adversarial robustness more effectively and reliably. The participants were encouraged to develop stronger white-box attack algorithms to find the worst-case robustness of different defenses. This competition was conducted on an adversarial robustness evaluation platform -- ARES (https://github.com/thu-ml/ares), and is held on the TianChi platform (https://tianchi.aliyun.com/competition/entrance/531847/introduction) as one of the series of AI Security Challengers Program. After the competition, we summarized the results and established a new adversarial robustness benchmark at https://ml.cs.tsinghua.edu.cn/ares-bench/, which allows users to upload adversarial attack algorithms and defense models for evaluation.
Boosting Adversarial Transferability through Enhanced Momentum
Mar 19, 2021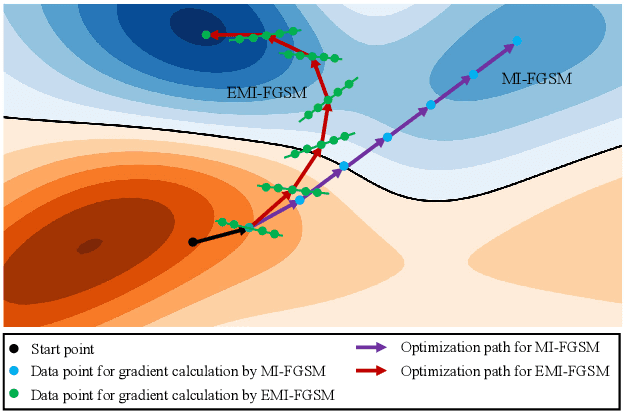
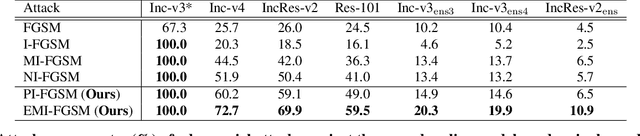
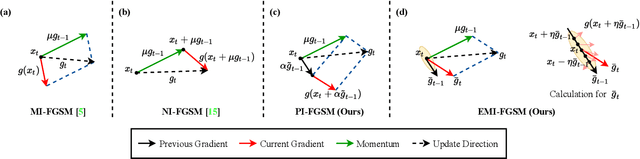
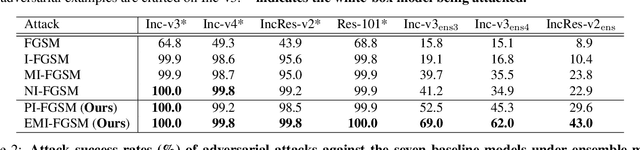
Deep learning models are known to be vulnerable to adversarial examples crafted by adding human-imperceptible perturbations on benign images. Many existing adversarial attack methods have achieved great white-box attack performance, but exhibit low transferability when attacking other models. Various momentum iterative gradient-based methods are shown to be effective to improve the adversarial transferability. In what follows, we propose an enhanced momentum iterative gradient-based method to further enhance the adversarial transferability. Specifically, instead of only accumulating the gradient during the iterative process, we additionally accumulate the average gradient of the data points sampled in the gradient direction of the previous iteration so as to stabilize the update direction and escape from poor local maxima. Extensive experiments on the standard ImageNet dataset demonstrate that our method could improve the adversarial transferability of momentum-based methods by a large margin of 11.1% on average. Moreover, by incorporating with various input transformation methods, the adversarial transferability could be further improved significantly. We also attack several extra advanced defense models under the ensemble-model setting, and the enhancements are remarkable with at least 7.8% on average.
Robust Local Features for Improving the Generalization of Adversarial Training
Sep 23, 2019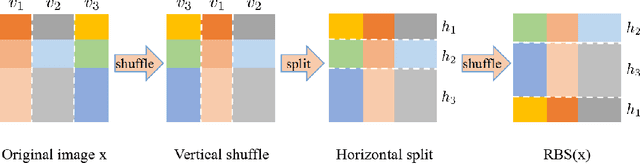
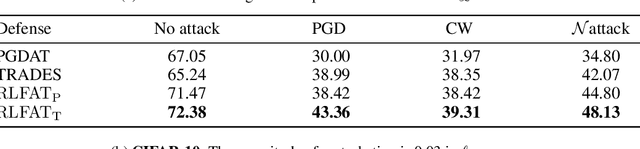

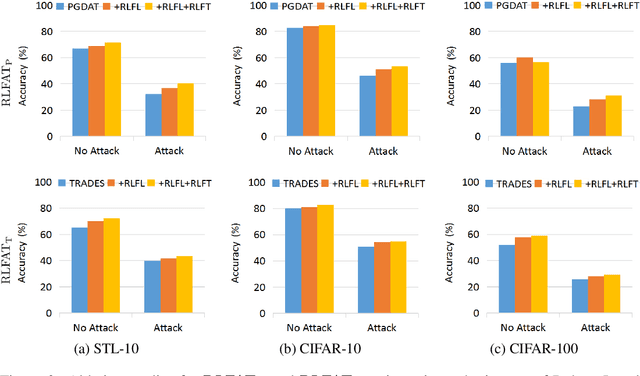
Adversarial training has been demonstrated as one of the most effective methods for training robust models so as to defend against adversarial examples. However, adversarial training often lacks adversarially robust generalization on unseen data. Recent works show that adversarially trained models may be more biased towards global structure features. Instead, in this work, we would like to investigate the relationship between the generalization of adversarial training and the robust local features, as the local features generalize well for unseen shape variation. To learn the robust local features, we develop a Random Block Shuffle (RBS) transformation to break up the global structure features on normal adversarial examples. We continue to propose a new approach called Robust Local Features for Adversarial Training (RLFAT), which first learns the robust local features by adversarial training on the RBS-transformed adversarial examples, and then transfers the robust local features into the training of normal adversarial examples. Finally, we implement RLFAT in two currently state-of-the-art adversarial training frameworks. Extensive experiments on STL-10, CIFAR-10, CIFAR-100 datasets show that RLFAT improves the adversarially robust generalization as well as the standard generalization of adversarial training. Additionally, we demonstrate that our method captures more local features of the object, aligning better with human perception.
Nesterov Accelerated Gradient and Scale Invariance for Improving Transferability of Adversarial Examples
Aug 17, 2019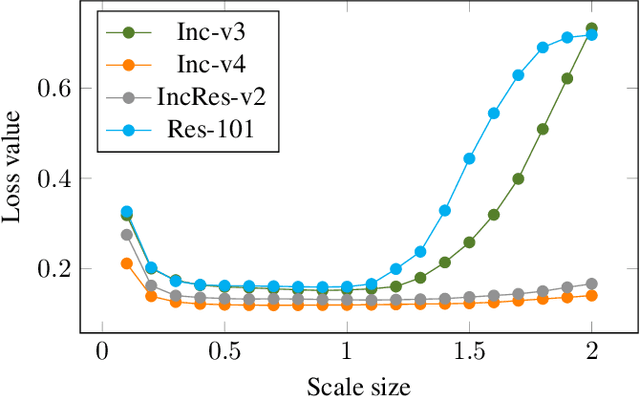

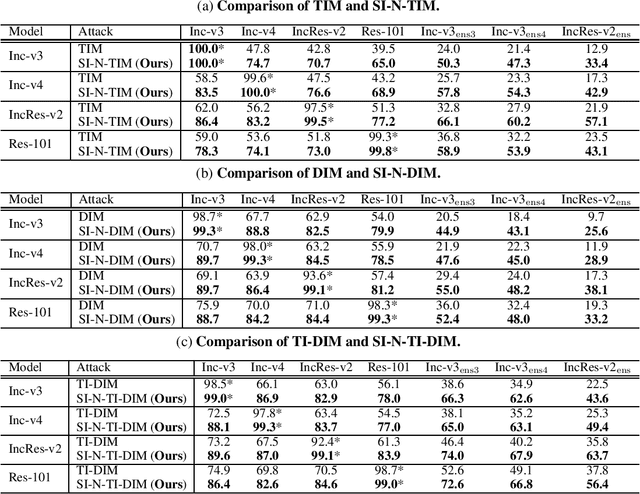

Recent evidence suggests that deep neural networks (DNNs) are vulnerable to adversarial examples, which are crafted by adding human-imperceptible perturbations to legitimate examples. However, most of the existing adversarial attacks generate adversarial examples with weak transferability, making it difficult to evaluate the robustness of DNNs under the challenging black-box setting. To address this issue, we propose two methods: Nesterov momentum iterative fast gradient sign method (N-MI-FGSM) and scale-invariant attack method (SIM), to improve the transferability of adversarial examples. N-MI-FGSM tries a better optimizer by applying the idea of Nesterov accelerated gradient to gradient-based attack method. SIM leverages the scale-invariant property of DNNs and optimizes the generated adversarial example by a set of scaled images as the inputs. Further, the two methods can be naturally combined to form a strong attack and enhance existing gradient attack methods. Empirical results on ImageNet and NIPS 2017 adversarial competition show that the proposed methods can generate adversarial examples with higher transferability than existing competing baselines.