 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Aligned Captions for Explainable Video Anomaly Detection
Jan 13, 2026Explainable video anomaly detection (VAD) is crucial for safety-critical applications, yet even with recent progress, much of the research still lacks spatial grounding, making the explanations unverifiable. This limitation is especially pronounced in multi-entity interactions, where existing explainable VAD methods often produce incomplete or visually misaligned descriptions, reducing their trustworthiness. To address these challenges, we introduce instance-aligned captions that link each textual claim to specific object instances with appearance and motion attributes. Our framework captures who caused the anomaly, what each entity was doing, whom it affected, and where the explanationis grounded, enabling verifiable and actionable reasoning. We annotate eight widely used VAD benchmarks and extend the 360-degree egocentric dataset, VIEW360, with 868 additional videos, eight locations, and four new anomaly types, creating VIEW360+, a comprehensive testbed for explainable VAD. Experiments show that our instance-level spatially grounded captions reveal significant limitations in current LLM- and VLM-based methods while providing a robust benchmark for future research in trustworthy and interpretable anomaly detection.
PCEval: A Benchmark for Evaluating Physical Computing Capabilities of Large Language Models
Dec 31, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains, including software development, education, and technical assistance. Among these, software development is one of the key areas where LLMs are increasingly adopted. However, when hardware constraints are considered-for instance, in physical computing, where software must interact with and control physical hardware -their effectiveness has not been fully explored. To address this gap, we introduce \textsc{PCEval} (Physical Computing Evaluation), the first benchmark in physical computing that enables a fully automatic evaluation of the capabilities of LLM in both the logical and physical aspects of the projects, without requiring human assessment. Our evaluation framework assesses LLMs in generating circuits and producing compatible code across varying levels of project complexity. Through comprehensive testing of 13 leading models, \textsc{PCEval} provides the first reproducible and automatically validated empirical assessment of LLMs' ability to reason about fundamental hardware implementation constraints within a simulation environment. Our findings reveal that while LLMs perform well in code generation and logical circuit design, they struggle significantly with physical breadboard layout creation, particularly in managing proper pin connections and avoiding circuit errors. \textsc{PCEval} advances our understanding of AI assistance in hardware-dependent computing environments and establishes a foundation for developing more effective tools to support physical computing education.
PawPrint: Whose Footprints Are These? Identifying Animal Individuals by Their Footprints
May 23, 2025In the United States, as of 2023, pet ownership has reached 66% of households and continues to rise annually. This trend underscores the critical need for effective pet identification and monitoring methods, particularly as nearly 10 million cats and dogs are reported stolen or lost each year. However, traditional methods for finding lost animals like GPS tags or ID photos have limitations-they can be removed, face signal issues, and depend on someone finding and reporting the pet. To address these limitations, we introduce PawPrint and PawPrint+, the first publicly available datasets focused on individual-level footprint identification for dogs and cats. Through comprehensive benchmarking of both modern deep neural networks (e.g., CNN, Transformers) and classical local features, we observe varying advantages and drawbacks depending on substrate complexity and data availability. These insights suggest future directions for combining learned global representations with local descriptors to enhance reliability across diverse, real-world conditions. As this approach provides a non-invasive alternative to traditional ID tags, we anticipate promising applications in ethical pet management and wildlife conservation efforts.
Real-time Traffic Accident Anticipation with Feature Reuse
May 23, 2025This paper addresses the problem of anticipating traffic accidents, which aims to forecast potential accidents before they happen. Real-time anticipation is crucial for safe autonomous driving, yet most methods rely on computationally heavy modules like optical flow and intermediate feature extractors, making real-world deployment challenging. In this paper, we thus introduce RARE (Real-time Accident anticipation with Reused Embeddings), a lightweight framework that capitalizes on intermediate features from a single pre-trained object detector. By eliminating additional feature-extraction pipelines, RARE significantly reduces latency. Furthermore, we introduce a novel Attention Score Ranking Loss, which prioritizes higher attention on accident-related objects over non-relevant ones. This loss enhances both accuracy and interpretability. RARE demonstrates a 4-8 times speedup over existing approaches on the DAD and CCD benchmarks, achieving a latency of 13.6ms per frame (73.3 FPS) on an RTX 6000. Moreover, despite its reduced complexity, it attains state-of-the-art Average Precision and reliably anticipates imminent collisions in real time. These results highlight RARE's potential for safety-critical applications where timely and explainable anticipation is essential.
Anomaly Detection for People with Visual Impairments Using an Egocentric 360-Degree Camera
Nov 17, 2024Recent advancements in computer vision have led to a renewed interest in developing assistive technologies for individuals with visual impairments. Although extensive research has been conducted in the field of computer vision-based assistive technologies, most of the focus has been on understanding contexts in images, rather than addressing their physical safety and security concerns. To address this challenge, we propose the first step towards detecting anomalous situations for visually impaired people by observing their entire surroundings using an egocentric 360-degree camera. We first introduce a novel egocentric 360-degree video dataset called VIEW360 (Visually Impaired Equipped with Wearable 360-degree camera), which contains abnormal activities that visually impaired individuals may encounter, such as shoulder surfing and pickpocketing. Furthermore, we propose a new architecture called the FDPN (Frame and Direction Prediction Network), which facilitates frame-level prediction of abnormal events and identifying of their directions. Finally, we evaluate our approach on our VIEW360 dataset and the publicly available UCF-Crime and Shanghaitech datasets, demonstrating state-of-the-art performance.
SFTrack: A Robust Scale and Motion Adaptive Algorithm for Tracking Small and Fast Moving Objects
Oct 26, 2024

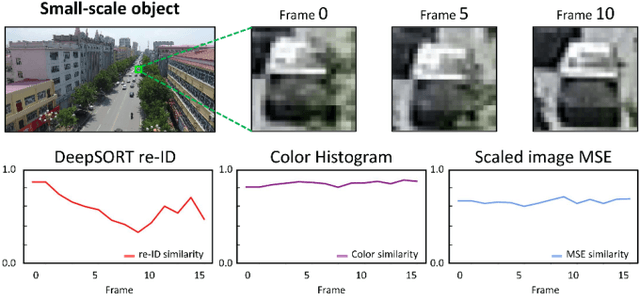

This paper addresses the problem of multi-object tracking in Unmanned Aerial Vehicle (UAV) footage. It plays a critical role in various UAV applications, including traffic monitoring systems and real-time suspect tracking by the police. However, this task is highly challenging due to the fast motion of UAVs, as well as the small size of target objects in the videos caused by the high-altitude and wide angle views of drones. In this study, we thus introduce a simple yet more effective method compared to previous work to overcome these challenges. Our approach involves a new tracking strategy, which initiates the tracking of target objects from low-confidence detections commonly encountered in UAV application scenarios. Additionally, we propose revisiting traditional appearance-based matching algorithms to improve the association of low-confidence detections. To evaluate the effectiveness of our method, we conducted benchmark evaluations on two UAV-specific datasets (VisDrone2019, UAVDT) and one general object tracking dataset (MOT17). The results demonstrate that our approach surpasses current state-of-the art methodologies, highlighting its robustness and adaptability in diverse tracking environments. Furthermore, we have improved the annotation of the UAVDT dataset by rectifying several errors and addressing omissions found in the original annotations. We will provide this refined version of the dataset to facilitate better benchmarking in the field.
TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Aug 21, 2024In this work, we discuss evaluating video foundation models in a fair and robust manner. Unlike language or image foundation models, many video foundation models are evaluated with differing parameters (such as sampling rate, number of frames, pretraining steps, etc.), making fair and robust comparisons challenging. Therefore, we present a carefully designed evaluation framework for measuring two core capabilities of video comprehension: appearance and motion understanding. Our findings reveal that existing video foundation models, whether text-supervised like UMT or InternVideo2, or self-supervised like V-JEPA, exhibit limitations in at least one of these capabilities. As an alternative, we introduce TWLV-I, a new video foundation model that constructs robust visual representations for both motion- and appearance-based videos. Based on the average top-1 accuracy of linear probing on five action recognition benchmarks, pretrained only on publicly accessible datasets, our model shows a 4.6%p improvement compared to V-JEPA (ViT-L) and a 7.7%p improvement compared to UMT (ViT-L). Even when compared to much larger models, our model demonstrates a 7.2%p improvement compared to DFN (ViT-H), a 2.7%p improvement compared to V-JEPA~(ViT-H) and a 2.8%p improvement compared to InternVideo2 (ViT-g). We provide embedding vectors obtained by TWLV-I from videos of several commonly used video benchmarks, along with evaluation source code that can directly utilize these embeddings. The code is available on "https://github.com/twelvelabs-io/video-embeddings-evaluation-framework".
PAFormer: Part Aware Transformer for Person Re-identification
Aug 12, 2024Within the domain of person re-identification (ReID), partial ReID methods are considered mainstream, aiming to measure feature distances through comparisons of body parts between samples. However, in practice, previous methods often lack sufficient awareness of anatomical aspect of body parts, resulting in the failure to capture features of the same body parts across different samples. To address this issue, we introduce \textbf{Part Aware Transformer (PAFormer)}, a pose estimation based ReID model which can perform precise part-to-part comparison. In order to inject part awareness to pose tokens, we introduce learnable parameters called `pose token' which estimate the correlation between each body part and partial regions of the image. Notably, at inference phase, PAFormer operates without additional modules related to body part localization, which is commonly used in previous ReID methodologies leveraging pose estimation models. Additionally, leveraging the enhanced awareness of body parts, PAFormer suggests the use of a learning-based visibility predictor to estimate the degree of occlusion for each body part. Also, we introduce a teacher forcing technique using ground truth visibility scores which enables PAFormer to be trained only with visible parts. A set of extensive experiments show that our method outperforms existing approaches on well-known ReID benchmark datasets.
Video Question Answering for People with Visual Impairments Using an Egocentric 360-Degree Camera
May 30, 2024This paper addresses the daily challenges encountered by visually impaired individuals, such as limited access to information, navigation difficulties, and barriers to social interaction. To alleviate these challenges, we introduce a novel visual question answering dataset. Our dataset offers two significant advancements over previous datasets: Firstly, it features videos captured using a 360-degree egocentric wearable camera, enabling observation of the entire surroundings, departing from the static image-centric nature of prior datasets. Secondly, unlike datasets centered on singular challenges, ours addresses multiple real-life obstacles simultaneously through an innovative visual-question answering framework. We validate our dataset using various state-of-the-art VideoQA methods and diverse metrics. Results indicate that while progress has been made, satisfactory performance levels for AI-powered assistive services remain elusive for visually impaired individuals. Additionally, our evaluation highlights the distinctive features of the proposed dataset, featuring ego-motion in videos captured via 360-degree cameras across varied scenarios.
A Decoding Scheme with Successive Aggregation of Multi-Level Features for Light-Weight Semantic Segmentation
Feb 17, 2024Multi-scale architecture, including hierarchical vision transformer, has been commonly applied to high-resolution semantic segmentation to deal with computational complexity with minimum performance loss. In this paper, we propose a novel decoding scheme for semantic segmentation in this regard, which takes multi-level features from the encoder with multi-scale architecture. The decoding scheme based on a multi-level vision transformer aims to achieve not only reduced computational expense but also higher segmentation accuracy, by introducing successive cross-attention in aggregation of the multi-level features. Furthermore, a way to enhance the multi-level features by the aggregated semantics is proposed. The effort is focused on maintaining the contextual consistency from the perspective of attention allocation and brings improved performance with significantly lower computational cost. Set of experiments on popular datasets demonstrates superiority of the proposed scheme to the state-of-the-art semantic segmentation models in terms of computational cost without loss of accuracy, and extensive ablation studies prove the effectiveness of ideas proposed.