 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Hands and Objects in Future Frames
Paper and Code
Aug 23, 2018
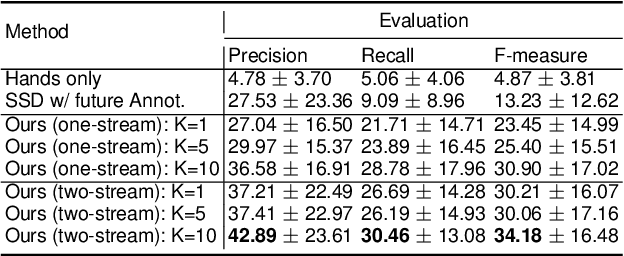
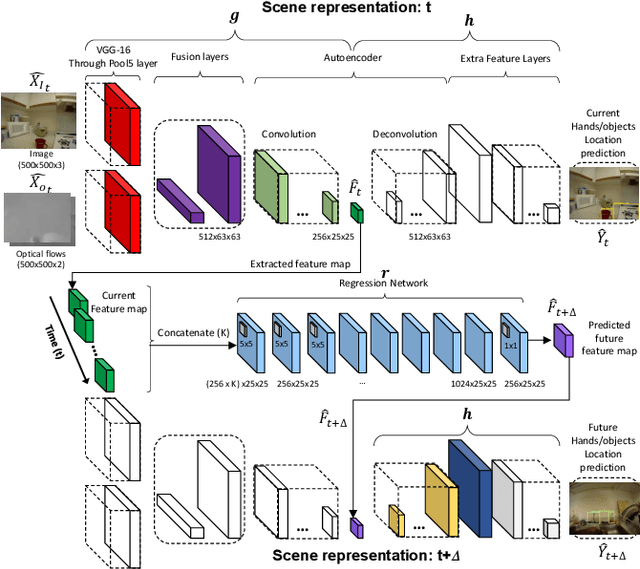
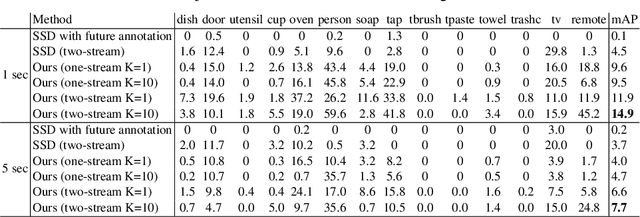
This paper presents an approach to forecast future presence and location of human hands and objects. Given an image frame, the goal is to predict what objects will appear in the future frame (e.g., 5 seconds later) and where they will be located at, even when they are not visible in the current frame. The key idea is that (1) an intermediate representation of a convolutional object recognition model abstracts scene information in its frame and that (2) we can predict (i.e., regress) such representations corresponding to the future frames based on that of the current frame. We design a new two-stream convolutional neural network (CNN) architecture for videos by extending the state-of-the-art convolutional object detection network, and present a new fully convolutional regression network for predicting future scene representations. Our experiments confirm that combining the regressed future representation with our detection network allows reliable estimation of future hands and objects in videos. We obtain much higher accuracy compared to the state-of-the-art future object presence forecast method on a public dataset.