 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Aligned Captions for Explainable Video Anomaly Detection
Jan 13, 2026Explainable video anomaly detection (VAD) is crucial for safety-critical applications, yet even with recent progress, much of the research still lacks spatial grounding, making the explanations unverifiable. This limitation is especially pronounced in multi-entity interactions, where existing explainable VAD methods often produce incomplete or visually misaligned descriptions, reducing their trustworthiness. To address these challenges, we introduce instance-aligned captions that link each textual claim to specific object instances with appearance and motion attributes. Our framework captures who caused the anomaly, what each entity was doing, whom it affected, and where the explanationis grounded, enabling verifiable and actionable reasoning. We annotate eight widely used VAD benchmarks and extend the 360-degree egocentric dataset, VIEW360, with 868 additional videos, eight locations, and four new anomaly types, creating VIEW360+, a comprehensive testbed for explainable VAD. Experiments show that our instance-level spatially grounded captions reveal significant limitations in current LLM- and VLM-based methods while providing a robust benchmark for future research in trustworthy and interpretable anomaly detection.
Anomaly Detection for People with Visual Impairments Using an Egocentric 360-Degree Camera
Nov 17, 2024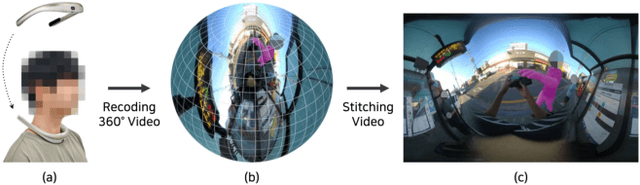



Recent advancements in computer vision have led to a renewed interest in developing assistive technologies for individuals with visual impairments. Although extensive research has been conducted in the field of computer vision-based assistive technologies, most of the focus has been on understanding contexts in images, rather than addressing their physical safety and security concerns. To address this challenge, we propose the first step towards detecting anomalous situations for visually impaired people by observing their entire surroundings using an egocentric 360-degree camera. We first introduce a novel egocentric 360-degree video dataset called VIEW360 (Visually Impaired Equipped with Wearable 360-degree camera), which contains abnormal activities that visually impaired individuals may encounter, such as shoulder surfing and pickpocketing. Furthermore, we propose a new architecture called the FDPN (Frame and Direction Prediction Network), which facilitates frame-level prediction of abnormal events and identifying of their directions. Finally, we evaluate our approach on our VIEW360 dataset and the publicly available UCF-Crime and Shanghaitech datasets, demonstrating state-of-the-art performance.
Video Question Answering for People with Visual Impairments Using an Egocentric 360-Degree Camera
May 30, 2024



This paper addresses the daily challenges encountered by visually impaired individuals, such as limited access to information, navigation difficulties, and barriers to social interaction. To alleviate these challenges, we introduce a novel visual question answering dataset. Our dataset offers two significant advancements over previous datasets: Firstly, it features videos captured using a 360-degree egocentric wearable camera, enabling observation of the entire surroundings, departing from the static image-centric nature of prior datasets. Secondly, unlike datasets centered on singular challenges, ours addresses multiple real-life obstacles simultaneously through an innovative visual-question answering framework. We validate our dataset using various state-of-the-art VideoQA methods and diverse metrics. Results indicate that while progress has been made, satisfactory performance levels for AI-powered assistive services remain elusive for visually impaired individuals. Additionally, our evaluation highlights the distinctive features of the proposed dataset, featuring ego-motion in videos captured via 360-degree cameras across varied scenarios.