 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Risk Minimization with $f$-Divergence Regularization
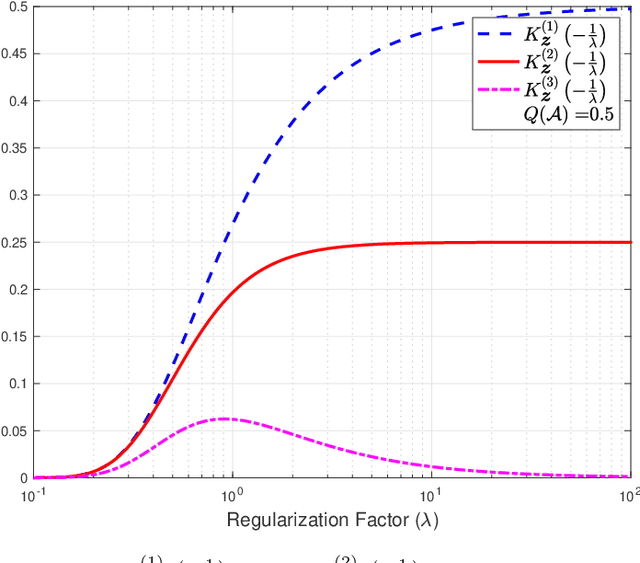
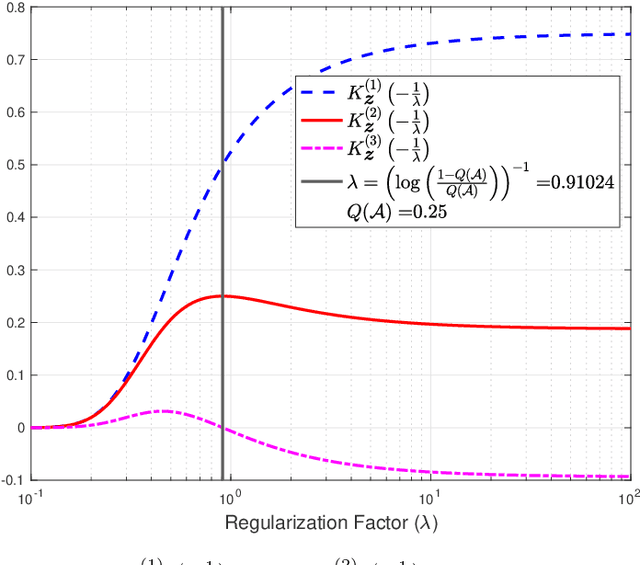
Jan 19, 2026In this paper, the solution to the empirical risk minimization problem with $f$-divergence regularization (ERM-$f$DR) is presented and conditions under which the solution also serves as the solution to the minimization of the expected empirical risk subject to an $f$-divergence constraint are established. The proposed approach extends applicability to a broader class of $f$-divergences than previously reported and yields theoretical results that recover previously known results. Additionally, the difference between the expected empirical risk of the ERM-$f$DR solution and that of its reference measure is characterized, providing insights into previously studied cases of $f$-divergences. A central contribution is the introduction of the normalization function, a mathematical object that is critical in both the dual formulation and practical computation of the ERM-$f$DR solution. This work presents an implicit characterization of the normalization function as a nonlinear ordinary differential equation (ODE), establishes its key properties, and subsequently leverages them to construct a numerical algorithm for approximating the normalization factor under mild assumptions. Further analysis demonstrates structural equivalences between ERM-$f$DR problems with different $f$-divergences via transformations of the empirical risk. Finally, the proposed algorithm is used to compute the training and test risks of ERM-$f$DR solutions under different $f$-divergence regularizers. This numerical example highlights the practical implications of choosing different functions $f$ in ERM-$f$DR problems.
Generalization Error of $f$-Divergence Stabilized Algorithms via Duality
Feb 20, 2025The solution to empirical risk minimization with $f$-divergence regularization (ERM-$f$DR) is extended to constrained optimization problems, establishing conditions for equivalence between the solution and constraints. A dual formulation of ERM-$f$DR is introduced, providing a computationally efficient method to derive the normalization function of the ERM-$f$DR solution. This dual approach leverages the Legendre-Fenchel transform and the implicit function theorem, enabling explicit characterizations of the generalization error for general algorithms under mild conditions, and another for ERM-$f$DR solutions.
Proofs for Folklore Theorems on the Radon-Nikodym Derivative
Jan 30, 2025Rigorous statements and formal proofs are presented for both foundational and advanced folklore theorems on the Radon-Nikodym derivative. The cases of product and marginal measures are carefully considered; and the hypothesis under which the statements hold are rigorously enumerated.
Stealth Attacks Against Moving Target Defense for Smart Grid
Nov 25, 2024Data injection attacks (DIAs) pose a significant cybersecurity threat to the Smart Grid by enabling an attacker to compromise the integrity of data acquisition and manipulate estimated states without triggering bad data detection procedures. To mitigate this vulnerability, the moving target defense (MTD) alters branch admittances to mismatch the system information that is available to an attacker, thereby inducing an imperfect DIA construction that results in degradation of attack performance. In this paper, we first analyze the existence of stealth attacks for the case in which the MTD strategy only changes the admittance of a single branch. Equipped with this initial insight, we then extend the results to the case in which multiple branches are protected by the MTD strategy. Remarkably, we show that stealth attacks can be constructed with information only about which branches are protected, without knowledge about the particular admittance value changes. Furthermore, we provide a sufficient protection condition for the MTD strategy via graph-theoretic tools that guarantee that the system is not vulnerable to DIAs. Numerical simulations are implemented on IEEE test systems to validate the obtained results.
Equivalence of the Empirical Risk Minimization to Regularization on the Family of f-Divergences
Feb 01, 2024The solution to empirical risk minimization with $f$-divergence regularization (ERM-$f$DR) is presented under mild conditions on $f$. Under such conditions, the optimal measure is shown to be unique. Examples of the solution for particular choices of the function $f$ are presented. Previously known solutions to common regularization choices are obtained by leveraging the flexibility of the family of $f$-divergences. These include the unique solutions to empirical risk minimization with relative entropy regularization (Type-I and Type-II). The analysis of the solution unveils the following properties of $f$-divergences when used in the ERM-$f$DR problem: $i\bigl)$ $f$-divergence regularization forces the support of the solution to coincide with the support of the reference measure, which introduces a strong inductive bias that dominates the evidence provided by the training data; and $ii\bigl)$ any $f$-divergence regularization is equivalent to a different $f$-divergence regularization with an appropriate transformation of the empirical risk function.
Generalization Analysis of Machine Learning Algorithms via the Worst-Case Data-Generating Probability Measure
Dec 19, 2023In this paper, the worst-case probability measure over the data is introduced as a tool for characterizing the generalization capabilities of machine learning algorithms. More specifically, the worst-case probability measure is a Gibbs probability measure and the unique solution to the maximization of the expected loss under a relative entropy constraint with respect to a reference probability measure. Fundamental generalization metrics, such as the sensitivity of the expected loss, the sensitivity of the empirical risk, and the generalization gap are shown to have closed-form expressions involving the worst-case data-generating probability measure. Existing results for the Gibbs algorithm, such as characterizing the generalization gap as a sum of mutual information and lautum information, up to a constant factor, are recovered. A novel parallel is established between the worst-case data-generating probability measure and the Gibbs algorithm. Specifically, the Gibbs probability measure is identified as a fundamental commonality of the model space and the data space for machine learning algorithms.
On the Validation of Gibbs Algorithms: Training Datasets, Test Datasets and their Aggregation
Jun 21, 2023The dependence on training data of the Gibbs algorithm (GA) is analytically characterized. By adopting the expected empirical risk as the performance metric, the sensitivity of the GA is obtained in closed form. In this case, sensitivity is the performance difference with respect to an arbitrary alternative algorithm. This description enables the development of explicit expressions involving the training errors and test errors of GAs trained with different datasets. Using these tools, dataset aggregation is studied and different figures of merit to evaluate the generalization capabilities of GAs are introduced. For particular sizes of such datasets and parameters of the GAs, a connection between Jeffrey's divergence, training and test errors is established.
Analysis of the Relative Entropy Asymmetry in the Regularization of Empirical Risk Minimization
Jun 12, 2023The effect of the relative entropy asymmetry is analyzed in the empirical risk minimization with relative entropy regularization (ERM-RER) problem. A novel regularization is introduced, coined Type-II regularization, that allows for solutions to the ERM-RER problem with a support that extends outside the support of the reference measure. The solution to the new ERM-RER Type-II problem is analytically characterized in terms of the Radon-Nikodym derivative of the reference measure with respect to the solution. The analysis of the solution unveils the following properties of relative entropy when it acts as a regularizer in the ERM-RER problem: i) relative entropy forces the support of the Type-II solution to collapse into the support of the reference measure, which introduces a strong inductive bias that dominates the evidence provided by the training data; ii) Type-II regularization is equivalent to classical relative entropy regularization with an appropriate transformation of the empirical risk function. Closed-form expressions of the expected empirical risk as a function of the regularization parameters are provided.
Empirical Risk Minimization with Generalized Relative Entropy Regularization
Nov 12, 2022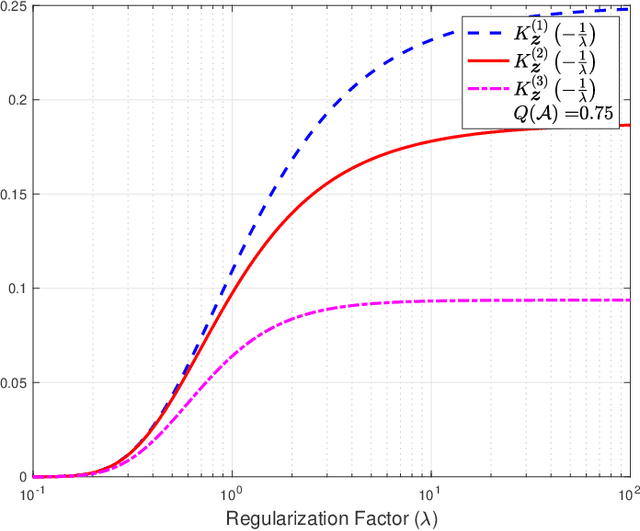
The empirical risk minimization (ERM) problem with relative entropy regularization (ERM-RER) is investigated under the assumption that the reference measure is a~$\sigma$-finite measure instead of a probability measure. This assumption leads to a generalization of the ERM-RER (g-ERM-RER) problem that allows for a larger degree of flexibility in the incorporation of prior knowledge over the set of models. The solution of the g-ERM-RER problem is shown to be a unique probability measure mutually absolutely continuous with the reference measure and to exhibit a probably-approximately-correct (PAC) guarantee for the ERM problem. For a given dataset, the empirical risk is shown to be a sub-Gaussian random variable when the models are sampled from the solution to the g-ERM-RER problem. Finally, the sensitivity of the expected empirical risk to deviations from the solution of the g-ERM-RER problem is studied. In particular, the expectation of the absolute value of sensitivity is shown to be upper bounded, up to a constant factor, by the square root of the lautum information between the models and the datasets.
Empirical Risk Minimization with Relative Entropy Regularization: Optimality and Sensitivity Analysis
Feb 09, 2022The optimality and sensitivity of the empirical risk minimization problem with relative entropy regularization (ERM-RER) are investigated for the case in which the reference is a sigma-finite measure instead of a probability measure. This generalization allows for a larger degree of flexibility in the incorporation of prior knowledge over the set of models. In this setting, the interplay of the regularization parameter, the reference measure, the risk function, and the empirical risk induced by the solution of the ERM-RER problem is characterized. This characterization yields necessary and sufficient conditions for the existence of a regularization parameter that achieves an arbitrarily small empirical risk with arbitrarily high probability. The sensitivity of the expected empirical risk to deviations from the solution of the ERM-RER problem is studied. The sensitivity is then used to provide upper and lower bounds on the expected empirical risk. Moreover, it is shown that the expectation of the sensitivity is upper bounded, up to a constant factor, by the square root of the lautum information between the models and the datasets.