 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariations on the Expectation Due to Changes in the Probability Measure
Feb 05, 2025Closed-form expressions are presented for the variation of the expectation of a given function due to changes in the probability measure used for the expectation. They unveil interesting connections with Gibbs probability measures, the mutual information, and the lautum information.
Proofs for Folklore Theorems on the Radon-Nikodym Derivative
Jan 30, 2025Rigorous statements and formal proofs are presented for both foundational and advanced folklore theorems on the Radon-Nikodym derivative. The cases of product and marginal measures are carefully considered; and the hypothesis under which the statements hold are rigorously enumerated.
On the Validation of Gibbs Algorithms: Training Datasets, Test Datasets and their Aggregation
Jun 21, 2023The dependence on training data of the Gibbs algorithm (GA) is analytically characterized. By adopting the expected empirical risk as the performance metric, the sensitivity of the GA is obtained in closed form. In this case, sensitivity is the performance difference with respect to an arbitrary alternative algorithm. This description enables the development of explicit expressions involving the training errors and test errors of GAs trained with different datasets. Using these tools, dataset aggregation is studied and different figures of merit to evaluate the generalization capabilities of GAs are introduced. For particular sizes of such datasets and parameters of the GAs, a connection between Jeffrey's divergence, training and test errors is established.
Empirical Risk Minimization with Generalized Relative Entropy Regularization
Nov 12, 2022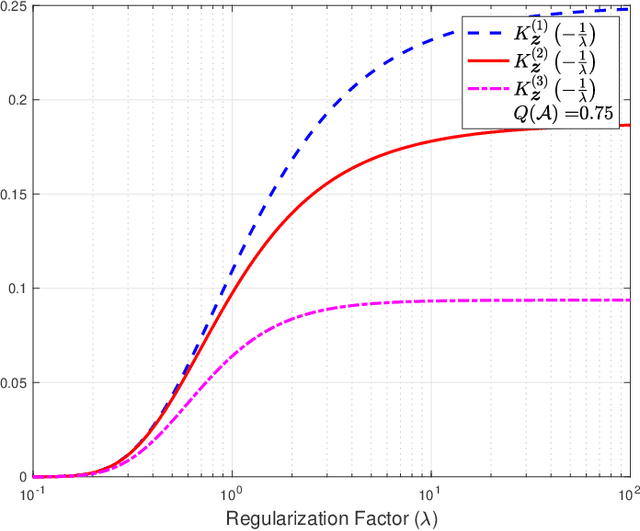
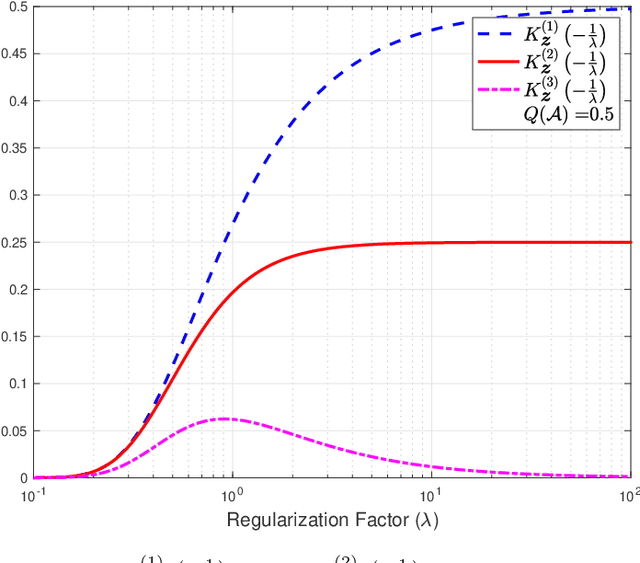
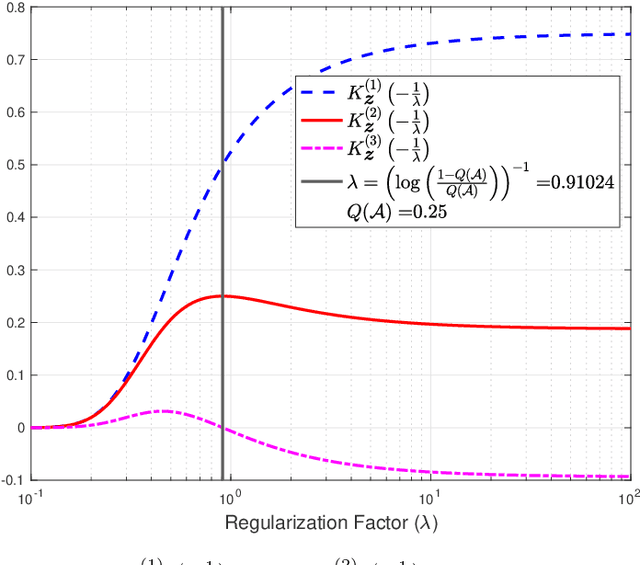
The empirical risk minimization (ERM) problem with relative entropy regularization (ERM-RER) is investigated under the assumption that the reference measure is a~$\sigma$-finite measure instead of a probability measure. This assumption leads to a generalization of the ERM-RER (g-ERM-RER) problem that allows for a larger degree of flexibility in the incorporation of prior knowledge over the set of models. The solution of the g-ERM-RER problem is shown to be a unique probability measure mutually absolutely continuous with the reference measure and to exhibit a probably-approximately-correct (PAC) guarantee for the ERM problem. For a given dataset, the empirical risk is shown to be a sub-Gaussian random variable when the models are sampled from the solution to the g-ERM-RER problem. Finally, the sensitivity of the expected empirical risk to deviations from the solution of the g-ERM-RER problem is studied. In particular, the expectation of the absolute value of sensitivity is shown to be upper bounded, up to a constant factor, by the square root of the lautum information between the models and the datasets.
Empirical Risk Minimization with Relative Entropy Regularization: Optimality and Sensitivity Analysis
Feb 09, 2022The optimality and sensitivity of the empirical risk minimization problem with relative entropy regularization (ERM-RER) are investigated for the case in which the reference is a sigma-finite measure instead of a probability measure. This generalization allows for a larger degree of flexibility in the incorporation of prior knowledge over the set of models. In this setting, the interplay of the regularization parameter, the reference measure, the risk function, and the empirical risk induced by the solution of the ERM-RER problem is characterized. This characterization yields necessary and sufficient conditions for the existence of a regularization parameter that achieves an arbitrarily small empirical risk with arbitrarily high probability. The sensitivity of the expected empirical risk to deviations from the solution of the ERM-RER problem is studied. The sensitivity is then used to provide upper and lower bounds on the expected empirical risk. Moreover, it is shown that the expectation of the sensitivity is upper bounded, up to a constant factor, by the square root of the lautum information between the models and the datasets.