 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAW: Stage-Aware Dynamic Weighting for Multi-Objective Reinforcement Learning in Large Language Models
Jun 05, 2026Although multi-objective reinforcement learning (MORL) is central to aligning large language models with complex human preferences, the prevailing practice of static weighted summation overlooks a more fundamental phenomenon: reward learning is markedly asynchronous across objectives. Well-learned dimensions quickly produce homogeneous, low-variance signals whose residual noise contaminates the aggregated reward (in GRPO) or occupies a fixed share of the advantage budget (in GDPO), interfering with the scarce yet high-value signals carried by under-learned dimensions. To address this asynchrony, we propose Stage-Aware Dynamic Weighting (SAW), a lightweight, algorithm-agnostic dynamic weighting mechanism. SAW utilizes the coefficient of variation (CV) as a scale-invariant proxy for real-time informativeness, reweighting each dimension's reward or advantage contribution by its relative informativeness within the batch. Unlike gradient-based methods that require multiple forward and backward passes, SAW relies solely on batch-level statistics, introducing nearly negligible computational overhead. Experiments on tool-calling and text summarization tasks demonstrate that SAW consistently improves both training efficiency and final performance under both GRPO and GDPO frameworks, confirming it as a general-purpose plug-in for multi-reward LLM alignment. Our code is available at https://github.com/Zhaolutuan/SAW
QUITO: Accelerating Long-Context Reasoning through Query-Guided Context Compression
Aug 01, 2024In-context learning (ICL) capabilities are foundational to the success of large language models (LLMs). Recently, context compression has attracted growing interest since it can largely reduce reasoning complexities and computation costs of LLMs. In this paper, we introduce a novel Query-gUIded aTtention cOmpression (QUITO) method, which leverages attention of the question over the contexts to filter useless information. Specifically, we take a trigger token to calculate the attention distribution of the context in response to the question. Based on the distribution, we propose three different filtering methods to satisfy the budget constraints of the context length. We evaluate the QUITO using two widely-used datasets, namely, NaturalQuestions and ASQA. Experimental results demonstrate that QUITO significantly outperforms established baselines across various datasets and downstream LLMs, underscoring its effectiveness. Our code is available at https://github.com/Wenshansilvia/attention_compressor.
CofeNet: Context and Former-Label Enhanced Net for Complicated Quotation Extraction
Sep 20, 2022
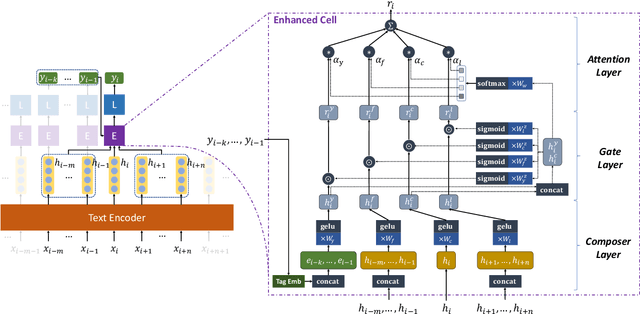
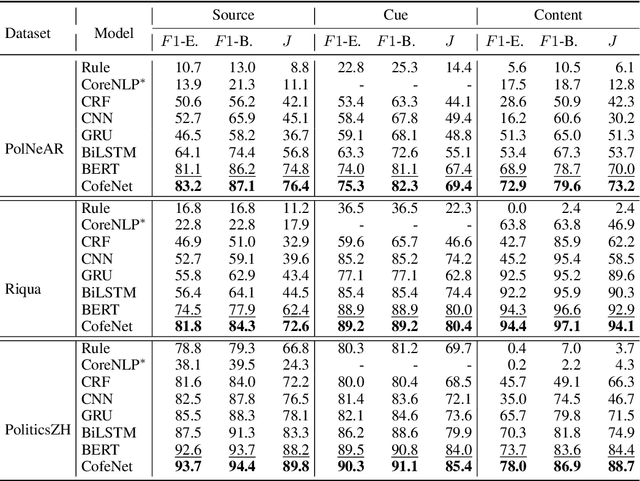
Quotation extraction aims to extract quotations from written text. There are three components in a quotation: source refers to the holder of the quotation, cue is the trigger word(s), and content is the main body. Existing solutions for quotation extraction mainly utilize rule-based approaches and sequence labeling models. While rule-based approaches often lead to low recalls, sequence labeling models cannot well handle quotations with complicated structures. In this paper, we propose the Context and Former-Label Enhanced Net (CofeNet) for quotation extraction. CofeNet is able to extract complicated quotations with components of variable lengths and complicated structures. On two public datasets (i.e., PolNeAR and Riqua) and one proprietary dataset (i.e., PoliticsZH), we show that our CofeNet achieves state-of-the-art performance on complicated quotation extraction.
Dynamic-K Recommendation with Personalized Decision Boundary
Dec 25, 2020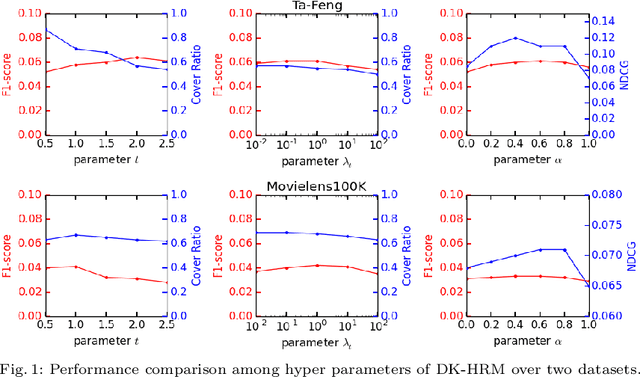
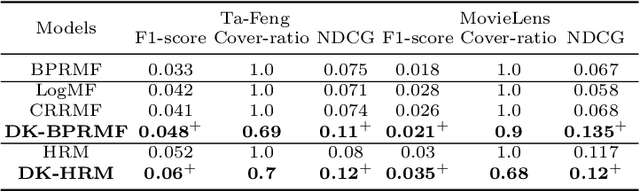

In this paper, we investigate the recommendation task in the most common scenario with implicit feedback (e.g., clicks, purchases). State-of-the-art methods in this direction usually cast the problem as to learn a personalized ranking on a set of items (e.g., webpages, products). The top-N results are then provided to users as recommendations, where the N is usually a fixed number pre-defined by the system according to some heuristic criteria (e.g., page size, screen size). There is one major assumption underlying this fixed-number recommendation scheme, i.e., there are always sufficient relevant items to users' preferences. Unfortunately, this assumption may not always hold in real-world scenarios. In some applications, there might be very limited candidate items to recommend, and some users may have very high relevance requirement in recommendation. In this way, even the top-1 ranked item may not be relevant to a user's preference. Therefore, we argue that it is critical to provide a dynamic-K recommendation, where the K should be different with respect to the candidate item set and the target user. We formulate this dynamic-K recommendation task as a joint learning problem with both ranking and classification objectives. The ranking objective is the same as existing methods, i.e., to create a ranking list of items according to users' interests. The classification objective is unique in this work, which aims to learn a personalized decision boundary to differentiate the relevant items from irrelevant items. Based on these ideas, we extend two state-of-the-art ranking-based recommendation methods, i.e., BPRMF and HRM, to the corresponding dynamic-K versions, namely DK-BPRMF and DK-HRM. Our experimental results on two datasets show that the dynamic-K models are more effective than the original fixed-N recommendation methods.
* 12 pages