 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCofeNet: Context and Former-Label Enhanced Net for Complicated Quotation Extraction
Paper and Code

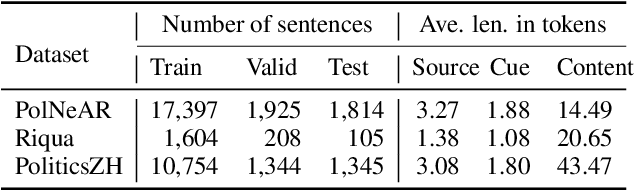
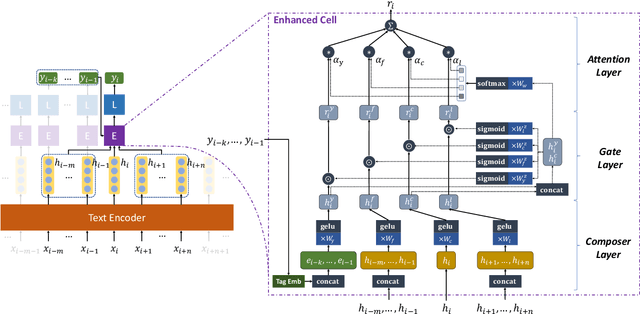
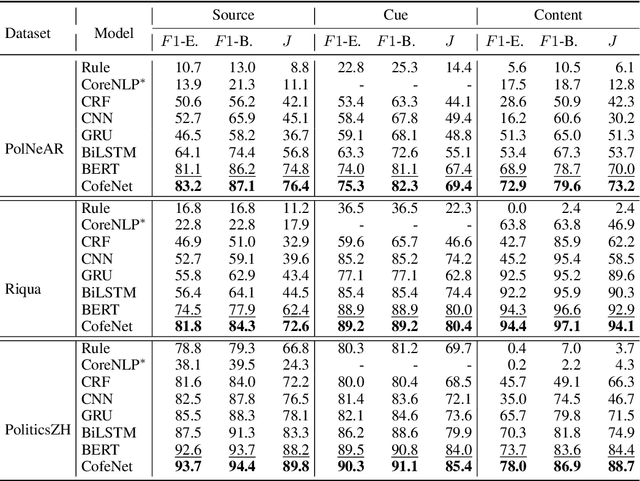
Quotation extraction aims to extract quotations from written text. There are three components in a quotation: source refers to the holder of the quotation, cue is the trigger word(s), and content is the main body. Existing solutions for quotation extraction mainly utilize rule-based approaches and sequence labeling models. While rule-based approaches often lead to low recalls, sequence labeling models cannot well handle quotations with complicated structures. In this paper, we propose the Context and Former-Label Enhanced Net (CofeNet) for quotation extraction. CofeNet is able to extract complicated quotations with components of variable lengths and complicated structures. On two public datasets (i.e., PolNeAR and Riqua) and one proprietary dataset (i.e., PoliticsZH), we show that our CofeNet achieves state-of-the-art performance on complicated quotation extraction.