 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHub.ai: A Simple, Standardized, and Reproducible Platform for AI Models in Medical Imaging
Jan 15, 2026Artificial intelligence (AI) has the potential to transform medical imaging by automating image analysis and accelerating clinical research. However, research and clinical use are limited by the wide variety of AI implementations and architectures, inconsistent documentation, and reproducibility issues. Here, we introduce MHub.ai, an open-source, container-based platform that standardizes access to AI models with minimal configuration, promoting accessibility and reproducibility in medical imaging. MHub.ai packages models from peer-reviewed publications into standardized containers that support direct processing of DICOM and other formats, provide a unified application interface, and embed structured metadata. Each model is accompanied by publicly available reference data that can be used to confirm model operation. MHub.ai includes an initial set of state-of-the-art segmentation, prediction, and feature extraction models for different modalities. The modular framework enables adaptation of any model and supports community contributions. We demonstrate the utility of the platform in a clinical use case through comparative evaluation of lung segmentation models. To further strengthen transparency and reproducibility, we publicly release the generated segmentations and evaluation metrics and provide interactive dashboards that allow readers to inspect individual cases and reproduce or extend our analysis. By simplifying model use, MHub.ai enables side-by-side benchmarking with identical execution commands and standardized outputs, and lowers the barrier to clinical translation.
brat: Aligned Multi-View Embeddings for Brain MRI Analysis
Dec 21, 2025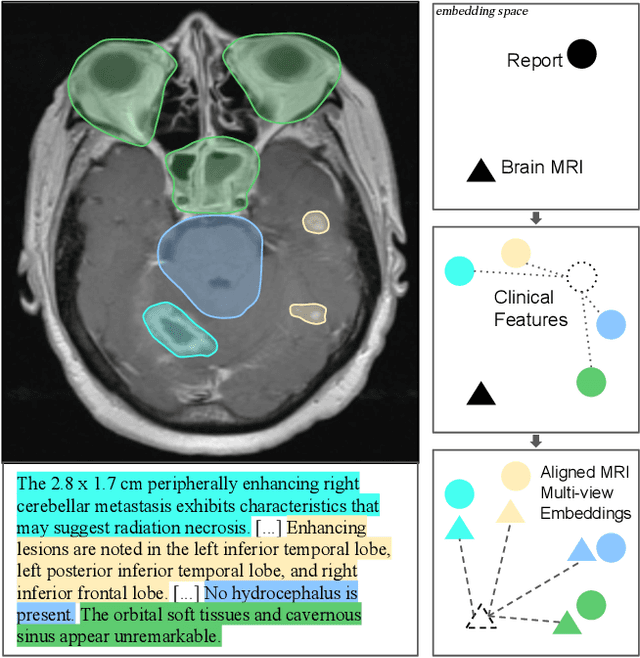
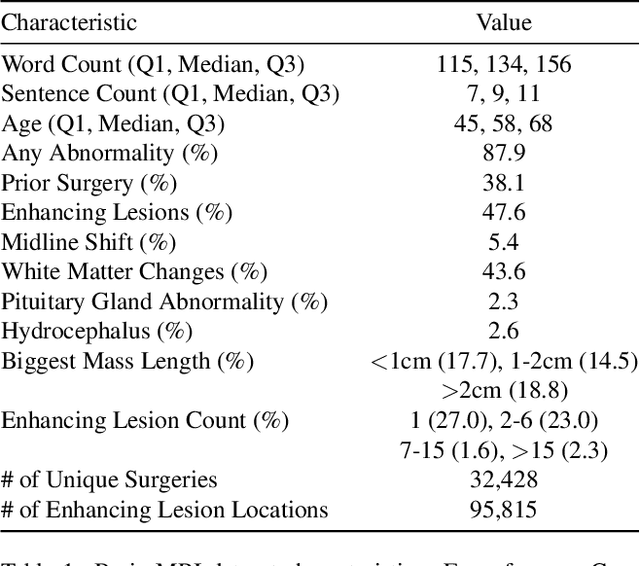
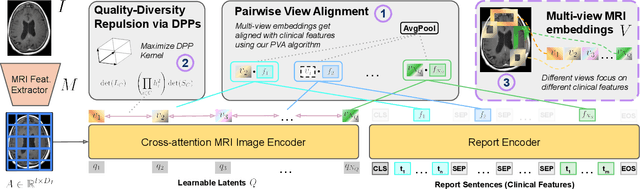
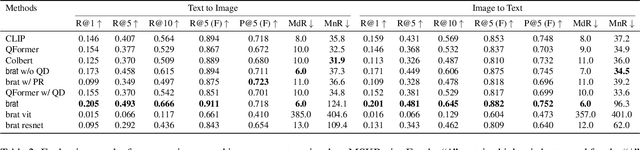
We present brat (brain report alignment transformer), a multi-view representation learning framework for brain magnetic resonance imaging (MRI) trained on MRIs paired with clinical reports. Brain MRIs present unique challenges due to the presence of numerous, highly varied, and often subtle abnormalities that are localized to a few slices within a 3D volume. To address these challenges, we introduce a brain MRI dataset $10\times$ larger than existing ones, containing approximately 80,000 3D scans with corresponding radiology reports, and propose a multi-view pre-training approach inspired by advances in document retrieval. We develop an implicit query-feature matching mechanism and adopt concepts from quality-diversity to obtain multi-view embeddings of MRIs that are aligned with the clinical features given by report sentences. We evaluate our approach across multiple vision-language and vision tasks, demonstrating substantial performance improvements. The brat foundation models are publicly released.
Tumor-anchored deep feature random forests for out-of-distribution detection in lung cancer segmentation
Dec 09, 2025Accurate segmentation of cancerous lesions from 3D computed tomography (CT) scans is essential for automated treatment planning and response assessment. However, even state-of-the-art models combining self-supervised learning (SSL) pretrained transformers with convolutional decoders are susceptible to out-of-distribution (OOD) inputs, generating confidently incorrect tumor segmentations, posing risks for safe clinical deployment. Existing logit-based methods suffer from task-specific model biases, while architectural enhancements to explicitly detect OOD increase parameters and computational costs. Hence, we introduce a plug-and-play and lightweight post-hoc random forests-based OOD detection framework called RF-Deep that leverages deep features with limited outlier exposure. RF-Deep enhances generalization to imaging variations by repurposing the hierarchical features from the pretrained-then-finetuned backbone encoder, providing task-relevant OOD detection by extracting the features from multiple regions of interest anchored to the predicted tumor segmentations. Hence, it scales to images of varying fields-of-view. We compared RF-Deep against existing OOD detection methods using 1,916 CT scans across near-OOD (pulmonary embolism, negative COVID-19) and far-OOD (kidney cancer, healthy pancreas) datasets. RF-Deep achieved AUROC > 93.50 for the challenging near-OOD datasets and near-perfect detection (AUROC > 99.00) for the far-OOD datasets, substantially outperforming logit-based and radiomics approaches. RF-Deep maintained similar performance consistency across networks of different depths and pretraining strategies, demonstrating its effectiveness as a lightweight, architecture-agnostic approach to enhance the reliability of tumor segmentation from CT volumes.
Random forest-based out-of-distribution detection for robust lung cancer segmentation
Aug 26, 2025Accurate detection and segmentation of cancerous lesions from computed tomography (CT) scans is essential for automated treatment planning and cancer treatment response assessment. Transformer-based models with self-supervised pretraining can produce reliably accurate segmentation from in-distribution (ID) data but degrade when applied to out-of-distribution (OOD) datasets. We address this challenge with RF-Deep, a random forest classifier that utilizes deep features from a pretrained transformer encoder of the segmentation model to detect OOD scans and enhance segmentation reliability. The segmentation model comprises a Swin Transformer encoder, pretrained with masked image modeling (SimMIM) on 10,432 unlabeled 3D CT scans covering cancerous and non-cancerous conditions, with a convolution decoder, trained to segment lung cancers in 317 3D scans. Independent testing was performed on 603 3D CT public datasets that included one ID dataset and four OOD datasets comprising chest CTs with pulmonary embolism (PE) and COVID-19, and abdominal CTs with kidney cancers and healthy volunteers. RF-Deep detected OOD cases with a FPR95 of 18.26%, 27.66%, and less than 0.1% on PE, COVID-19, and abdominal CTs, consistently outperforming established OOD approaches. The RF-Deep classifier provides a simple and effective approach to enhance reliability of cancer segmentation in ID and OOD scenarios.
Segmentation Regularized Training for Multi-Domain Deep Learning Registration applied to MR-Guided Prostate Cancer Radiotherapy
Jul 09, 2025Background: Accurate deformable image registration (DIR) is required for contour propagation and dose accumulation in MR-guided adaptive radiotherapy (MRgART). This study trained and evaluated a deep learning DIR method for domain invariant MR-MR registration. Methods: A progressively refined registration and segmentation (ProRSeg) method was trained with 262 pairs of 3T MR simulation scans from prostate cancer patients using weighted segmentation consistency loss. ProRSeg was tested on same- (58 pairs), cross- (72 1.5T MR Linac pairs), and mixed-domain (42 MRSim-MRL pairs) datasets for contour propagation accuracy of clinical target volume (CTV), bladder, and rectum. Dose accumulation was performed for 42 patients undergoing 5-fraction MRgART. Results: ProRSeg demonstrated generalization for bladder with similar Dice Similarity Coefficients across domains (0.88, 0.87, 0.86). For rectum and CTV, performance was domain-dependent with higher accuracy on cross-domain MRL dataset (DSCs 0.89) versus same-domain data. The model's strong cross-domain performance prompted us to study the feasibility of using it for dose accumulation. Dose accumulation showed 83.3% of patients met CTV coverage (D95 >= 40.0 Gy) and bladder sparing (D50 <= 20.0 Gy) constraints. All patients achieved minimum mean target dose (>40.4 Gy), but only 9.5% remained under upper limit (<42.0 Gy). Conclusions: ProRSeg showed reasonable multi-domain MR-MR registration performance for prostate cancer patients with preliminary feasibility for evaluating treatment compliance to clinical constraints.
Modality-agnostic, patient-specific digital twins modeling temporally varying digestive motion
Jul 03, 2025Objective: Clinical implementation of deformable image registration (DIR) requires voxel-based spatial accuracy metrics such as manually identified landmarks, which are challenging to implement for highly mobile gastrointestinal (GI) organs. To address this, patient-specific digital twins (DT) modeling temporally varying motion were created to assess the accuracy of DIR methods. Approach: 21 motion phases simulating digestive GI motion as 4D sequences were generated from static 3D patient scans using published analytical GI motion models through a semi-automated pipeline. Eleven datasets, including six T2w FSE MRI (T2w MRI), two T1w 4D golden-angle stack-of-stars, and three contrast-enhanced CT scans. The motion amplitudes of the DTs were assessed against real patient stomach motion amplitudes extracted from independent 4D MRI datasets. The generated DTs were then used to assess six different DIR methods using target registration error, Dice similarity coefficient, and the 95th percentile Hausdorff distance using summary metrics and voxel-level granular visualizations. Finally, for a subset of T2w MRI scans from patients treated with MR-guided radiation therapy, dose distributions were warped and accumulated to assess dose warping errors, including evaluations of DIR performance in both low- and high-dose regions for patient-specific error estimation. Main results: Our proposed pipeline synthesized DTs modeling realistic GI motion, achieving mean and maximum motion amplitudes and a mean log Jacobian determinant within 0.8 mm and 0.01, respectively, similar to published real-patient gastric motion data. It also enables the extraction of detailed quantitative DIR performance metrics and rigorous validation of dose mapping accuracy. Significance: The pipeline enables rigorously testing DIR tools for dynamic, anatomically complex regions enabling granular spatial and dosimetric accuracies.
Pretrained hybrid transformer for generalizable cardiac substructures segmentation from contrast and non-contrast CTs in lung and breast cancers
May 16, 2025AI automated segmentations for radiation treatment planning (RTP) can deteriorate when applied in clinical cases with different characteristics than training dataset. Hence, we refined a pretrained transformer into a hybrid transformer convolutional network (HTN) to segment cardiac substructures lung and breast cancer patients acquired with varying imaging contrasts and patient scan positions. Cohort I, consisting of 56 contrast-enhanced (CECT) and 124 non-contrast CT (NCCT) scans from patients with non-small cell lung cancers acquired in supine position, was used to create oracle with all 180 training cases and balanced (CECT: 32, NCCT: 32 training) HTN models. Models were evaluated on a held-out validation set of 60 cohort I patients and 66 patients with breast cancer from cohort II acquired in supine (n=45) and prone (n=21) positions. Accuracy was measured using DSC, HD95, and dose metrics. Publicly available TotalSegmentator served as the benchmark. The oracle and balanced models were similarly accurate (DSC Cohort I: 0.80 \pm 0.10 versus 0.81 \pm 0.10; Cohort II: 0.77 \pm 0.13 versus 0.80 \pm 0.12), outperforming TotalSegmentator. The balanced model, using half the training cases as oracle, produced similar dose metrics as manual delineations for all cardiac substructures. This model was robust to CT contrast in 6 out of 8 substructures and patient scan position variations in 5 out of 8 substructures and showed low correlations of accuracy to patient size and age. A HTN demonstrated robustly accurate (geometric and dose metrics) cardiac substructures segmentation from CTs with varying imaging and patient characteristics, one key requirement for clinical use. Moreover, the model combining pretraining with balanced distribution of NCCT and CECT scans was able to provide reliably accurate segmentations under varied conditions with far fewer labeled datasets compared to an oracle model.
Tumor aware recurrent inter-patient deformable image registration of computed tomography scans with lung cancer
Sep 18, 2024Background: Voxel-based analysis (VBA) for population level radiotherapy (RT) outcomes modeling requires topology preserving inter-patient deformable image registration (DIR) that preserves tumors on moving images while avoiding unrealistic deformations due to tumors occurring on fixed images. Purpose: We developed a tumor-aware recurrent registration (TRACER) deep learning (DL) method and evaluated its suitability for VBA. Methods: TRACER consists of encoder layers implemented with stacked 3D convolutional long short term memory network (3D-CLSTM) followed by decoder and spatial transform layers to compute dense deformation vector field (DVF). Multiple CLSTM steps are used to compute a progressive sequence of deformations. Input conditioning was applied by including tumor segmentations with 3D image pairs as input channels. Bidirectional tumor rigidity, image similarity, and deformation smoothness losses were used to optimize the network in an unsupervised manner. TRACER and multiple DL methods were trained with 204 3D CT image pairs from patients with lung cancers (LC) and evaluated using (a) Dataset I (N = 308 pairs) with DL segmented LCs, (b) Dataset II (N = 765 pairs) with manually delineated LCs, and (c) Dataset III with 42 LC patients treated with RT. Results: TRACER accurately aligned normal tissues. It best preserved tumors, blackindicated by the smallest tumor volume difference of 0.24\%, 0.40\%, and 0.13 \% and mean square error in CT intensities of 0.005, 0.005, 0.004, computed between original and resampled moving image tumors, for Datasets I, II, and III, respectively. It resulted in the smallest planned RT tumor dose difference computed between original and resampled moving images of 0.01 Gy and 0.013 Gy when using a female and a male reference.
Transformer-based segmentation of adnexal lesions and ovarian implants in CT images
Jun 25, 2024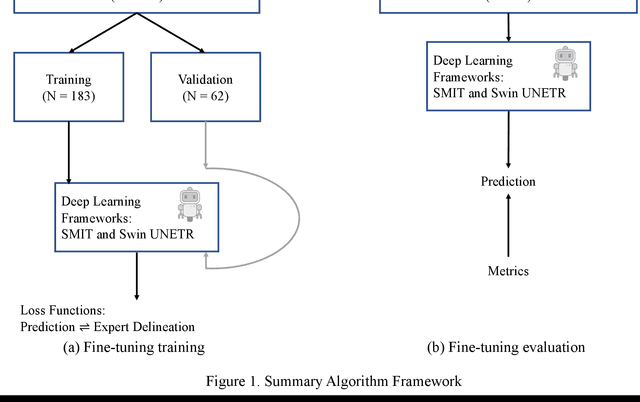
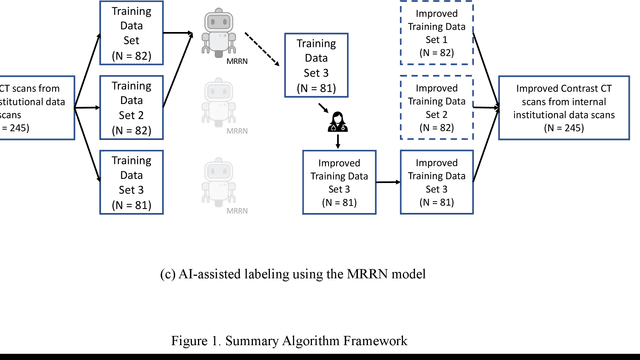
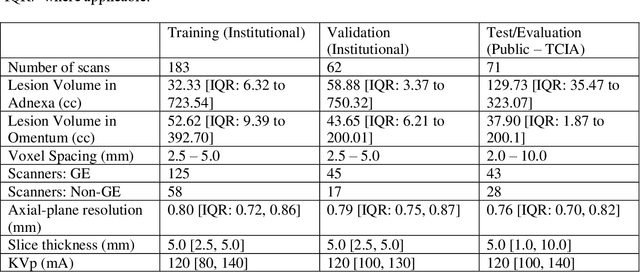
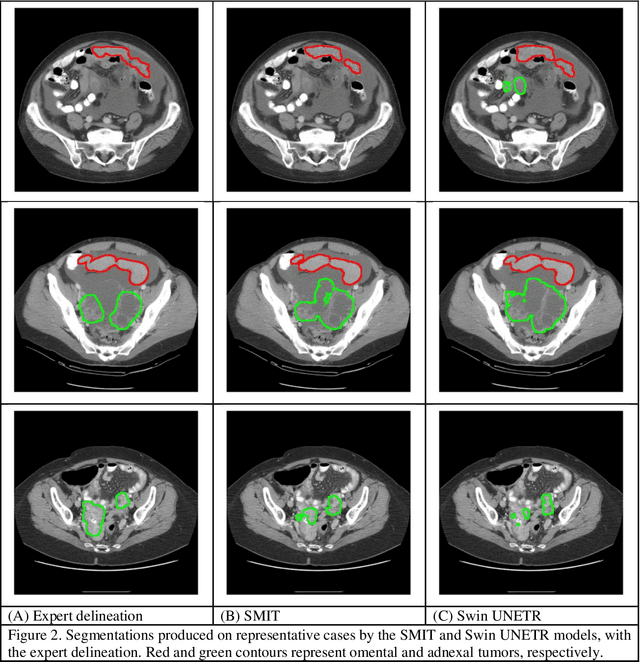
Two self-supervised pretrained transformer-based segmentation models (SMIT and Swin UNETR) fine-tuned on a dataset of ovarian cancer CT images provided reasonably accurate delineations of the tumors in an independent test dataset. Tumors in the adnexa were segmented more accurately by both transformers (SMIT and Swin UNETR) than the omental implants. AI-assisted labeling performed on 72 out of 245 omental implants resulted in smaller manual editing effort of 39.55 mm compared to full manual correction of partial labels of 106.49 mm and resulted in overall improved accuracy performance. Both SMIT and Swin UNETR did not generate any false detection of omental metastases in the urinary bladder and relatively few false detections in the small bowel, with 2.16 cc on average for SMIT and 7.37 cc for Swin UNETR respectively.
Self-supervised learning improves robustness of deep learning lung tumor segmentation to CT imaging differences
May 14, 2024



Self-supervised learning (SSL) is an approach to extract useful feature representations from unlabeled data, and enable fine-tuning on downstream tasks with limited labeled examples. Self-pretraining is a SSL approach that uses the curated task dataset for both pretraining the networks and fine-tuning them. Availability of large, diverse, and uncurated public medical image sets provides the opportunity to apply SSL in the "wild" and potentially extract features robust to imaging variations. However, the benefit of wild- vs self-pretraining has not been studied for medical image analysis. In this paper, we compare robustness of wild versus self-pretrained transformer (vision transformer [ViT] and hierarchical shifted window [Swin]) models to computed tomography (CT) imaging differences for non-small cell lung cancer (NSCLC) segmentation. Wild-pretrained Swin models outperformed self-pretrained Swin for the various imaging acquisitions. ViT resulted in similar accuracy for both wild- and self-pretrained models. Masked image prediction pretext task that forces networks to learn the local structure resulted in higher accuracy compared to contrastive task that models global image information. Wild-pretrained models resulted in higher feature reuse at the lower level layers and feature differentiation close to output layer after fine-tuning. Hence, we conclude: Wild-pretrained networks were more robust to analyzed CT imaging differences for lung tumor segmentation than self-pretrained methods. Swin architecture benefited from such pretraining more than ViT.