 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastBERT: a Self-distilling BERT with Adaptive Inference Time
Apr 29, 2020


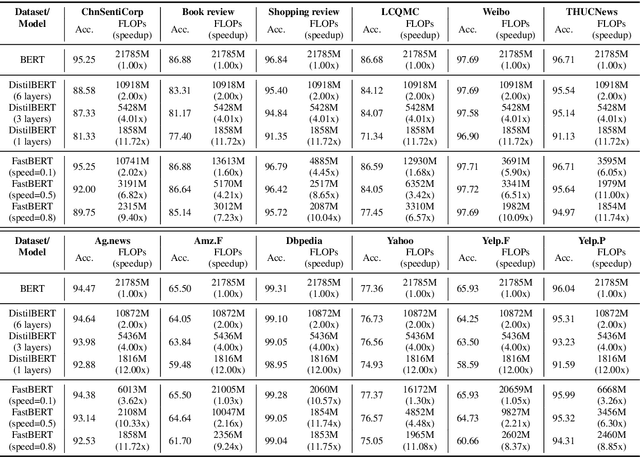
Pre-trained language models like BERT have proven to be highly performant. However, they are often computationally expensive in many practical scenarios, for such heavy models can hardly be readily implemented with limited resources. To improve their efficiency with an assured model performance, we propose a novel speed-tunable FastBERT with adaptive inference time. The speed at inference can be flexibly adjusted under varying demands, while redundant calculation of samples is avoided. Moreover, this model adopts a unique self-distillation mechanism at fine-tuning, further enabling a greater computational efficacy with minimal loss in performance. Our model achieves promising results in twelve English and Chinese datasets. It is able to speed up by a wide range from 1 to 12 times than BERT if given different speedup thresholds to make a speed-performance tradeoff.
K-BERT: Enabling Language Representation with Knowledge Graph
Sep 17, 2019



Pre-trained language representation models, such as BERT, capture a general language representation from large-scale corpora, but lack domain-specific knowledge. When reading a domain text, experts make inferences with relevant knowledge. For machines to achieve this capability, we propose a knowledge-enabled language representation model (K-BERT) with knowledge graphs (KGs), in which triples are injected into the sentences as domain knowledge. However, too much knowledge incorporation may divert the sentence from its correct meaning, which is called knowledge noise (KN) issue. To overcome KN, K-BERT introduces soft-position and visible matrix to limit the impact of knowledge. K-BERT can easily inject domain knowledge into the models by equipped with a KG without pre-training by-self because it is capable of loading model parameters from the pre-trained BERT. Our investigation reveals promising results in twelve NLP tasks. Especially in domain-specific tasks (including finance, law, and medicine), K-BERT significantly outperforms BERT, which demonstrates that K-BERT is an excellent choice for solving the knowledge-driven problems that require experts.
UER: An Open-Source Toolkit for Pre-training Models
Sep 12, 2019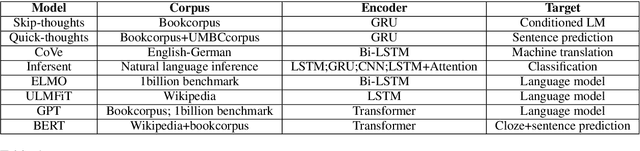
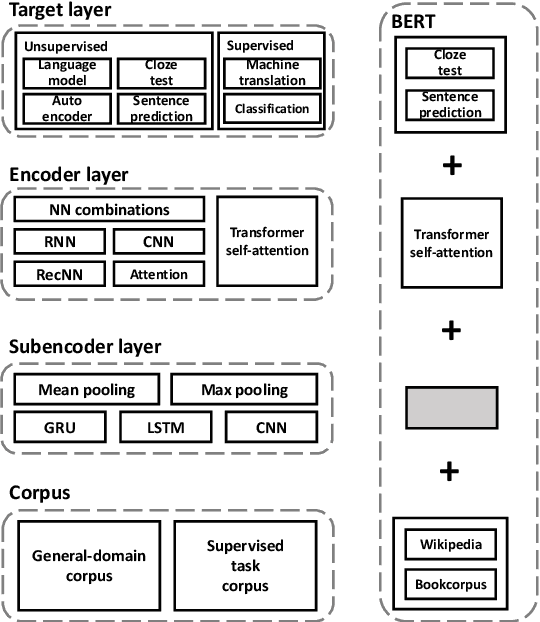
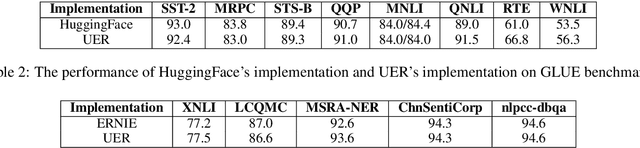
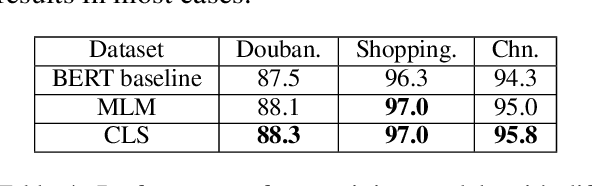
Existing works, including ELMO and BERT, have revealed the importance of pre-training for NLP tasks. While there does not exist a single pre-training model that works best in all cases, it is of necessity to develop a framework that is able to deploy various pre-training models efficiently. For this purpose, we propose an assemble-on-demand pre-training toolkit, namely Universal Encoder Representations (UER). UER is loosely coupled, and encapsulated with rich modules. By assembling modules on demand, users can either reproduce a state-of-the-art pre-training model or develop a pre-training model that remains unexplored. With UER, we have built a model zoo, which contains pre-trained models based on different corpora, encoders, and targets (objectives). With proper pre-trained models, we could achieve new state-of-the-art results on a range of downstream datasets.