 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustExplain: Evaluating Robustness of LLM-Based Explanation Agents for Recommendation
Jan 27, 2026Large Language Models (LLMs) are increasingly used to generate natural-language explanations in recommender systems, acting as explanation agents that reason over user behavior histories. While prior work has focused on explanation fluency and relevance under fixed inputs, the robustness of LLM-generated explanations to realistic user behavior noise remains largely unexplored. In real-world web platforms, interaction histories are inherently noisy due to accidental clicks, temporal inconsistencies, missing values, and evolving preferences, raising concerns about explanation stability and user trust. We present RobustExplain, the first systematic evaluation framework for measuring the robustness of LLM-generated recommendation explanations. RobustExplain introduces five realistic user behavior perturbations evaluated across multiple severity levels and a multi-dimensional robustness metric capturing semantic, keyword, structural, and length consistency. Our goal is to establish a principled, task-level evaluation framework and initial robustness baselines, rather than to provide a comprehensive leaderboard across all available LLMs. Experiments on four representative LLMs (7B--70B) show that current models exhibit only moderate robustness, with larger models achieving up to 8% higher stability. Our results establish the first robustness benchmarks for explanation agents and highlight robustness as a critical dimension for trustworthy, agent-driven recommender systems at web scale.
LLMs as Orchestrators: Constraint-Compliant Multi-Agent Optimization for Recommendation Systems
Jan 27, 2026Recommendation systems must optimize multiple objectives while satisfying hard business constraints such as fairness and coverage. For example, an e-commerce platform may require every recommendation list to include items from multiple sellers and at least one newly listed product; violating such constraints--even once--is unacceptable in production. Prior work on multi-objective recommendation and recent LLM-based recommender agents largely treat constraints as soft penalties or focus on item scoring and interaction, leading to frequent violations in real-world deployments. How to leverage LLMs for coordinating constrained optimization in recommendation systems remains underexplored. We propose DualAgent-Rec, an LLM-coordinated dual-agent framework for constrained multi-objective e-commerce recommendation. The framework separates optimization into an Exploitation Agent that prioritizes accuracy under hard constraints and an Exploration Agent that promotes diversity through unconstrained Pareto search. An LLM-based coordinator adaptively allocates resources between agents based on optimization progress and constraint satisfaction, while an adaptive epsilon-relaxation mechanism guarantees feasibility of final solutions. Experiments on the Amazon Reviews 2023 dataset demonstrate that DualAgent-Rec achieves 100% constraint satisfaction and improves Pareto hypervolume by 4-6% over strong baselines, while maintaining competitive accuracy-diversity trade-offs. These results indicate that LLMs can act as effective orchestration agents for deployable and constraint-compliant recommendation systems.
A DeepSeek-Powered AI System for Automated Chest Radiograph Interpretation in Clinical Practice
Dec 23, 2025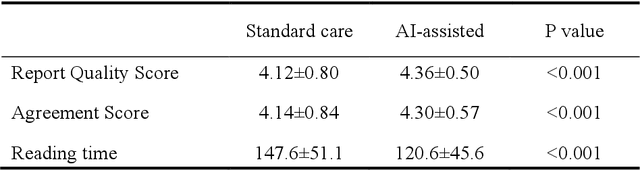
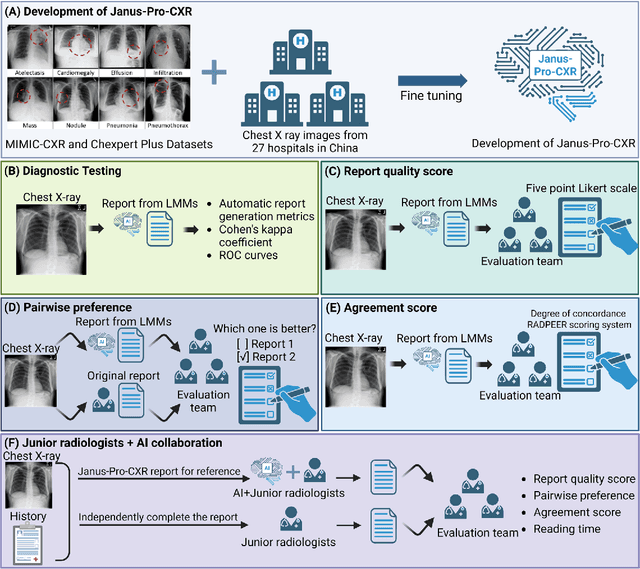
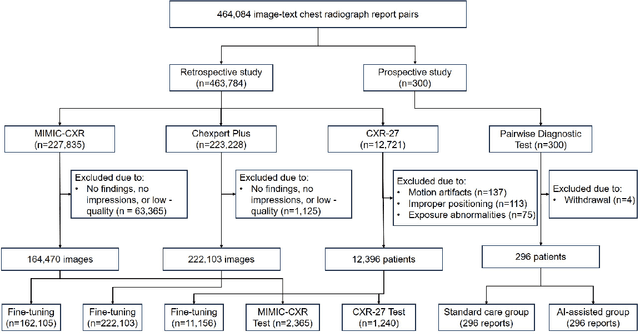
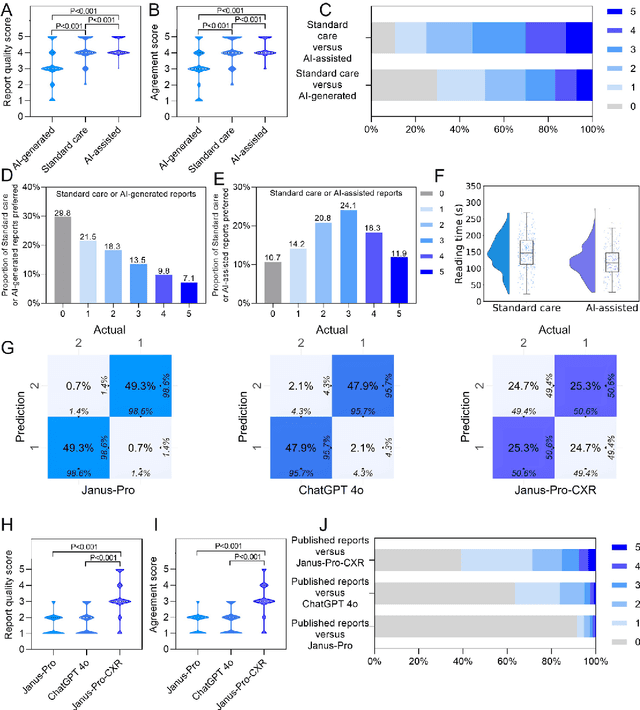
A global shortage of radiologists has been exacerbated by the significant volume of chest X-ray workloads, particularly in primary care. Although multimodal large language models show promise, existing evaluations predominantly rely on automated metrics or retrospective analyses, lacking rigorous prospective clinical validation. Janus-Pro-CXR (1B), a chest X-ray interpretation system based on DeepSeek Janus-Pro model, was developed and rigorously validated through a multicenter prospective trial (NCT07117266). Our system outperforms state-of-the-art X-ray report generation models in automated report generation, surpassing even larger-scale models including ChatGPT 4o (200B parameters), while demonstrating reliable detection of six clinically critical radiographic findings. Retrospective evaluation confirms significantly higher report accuracy than Janus-Pro and ChatGPT 4o. In prospective clinical deployment, AI assistance significantly improved report quality scores, reduced interpretation time by 18.3% (P < 0.001), and was preferred by a majority of experts in 54.3% of cases. Through lightweight architecture and domain-specific optimization, Janus-Pro-CXR improves diagnostic reliability and workflow efficiency, particularly in resource-constrained settings. The model architecture and implementation framework will be open-sourced to facilitate the clinical translation of AI-assisted radiology solutions.
Adaptive GPU Resource Allocation for Multi-Agent Collaborative Reasoning in Serverless Environments
Dec 15, 2025Multi-agent systems powered by large language models have emerged as a promising paradigm for solving complex reasoning tasks through collaborative intelligence. However, efficiently deploying these systems on serverless GPU platforms presents significant resource allocation challenges due to heterogeneous agent workloads, varying computational demands, and the need for cost-effective scaling. This paper presents an adaptive GPU resource allocation framework that achieves 85\% latency reduction compared to round-robin scheduling while maintaining comparable throughput to static allocation, using an $O(N)$ complexity algorithm for real-time adaptation. Our approach dynamically allocates GPU resources based on workload characteristics, agent priorities, and minimum resource requirements, enabling efficient utilization while maintaining quality of service. The framework addresses three key challenges: (1) heterogeneous computational demands across lightweight coordinators and heavyweight specialists, (2) dynamic workload fluctuations requiring millisecond-scale reallocation, and (3) capacity constraints in serverless environments. Through comprehensive simulations modeling realistic multi-agent workflows with four heterogeneous agents, we demonstrate that adaptive allocation outperforms static equal and round-robin strategies across latency, cost, and GPU utilization metrics. The framework provides a practical solution for deploying cost-efficient multi-agent AI systems on serverless GPU infrastructure.
* 7 pages, 2 figures
Vehicle Pose and Shape Estimation through Multiple Monocular Vision
Nov 11, 2018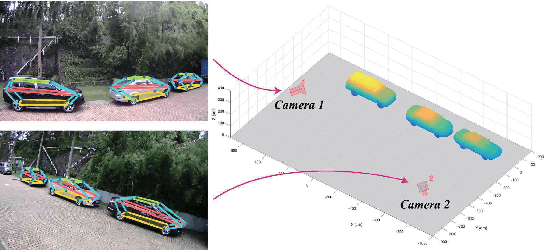
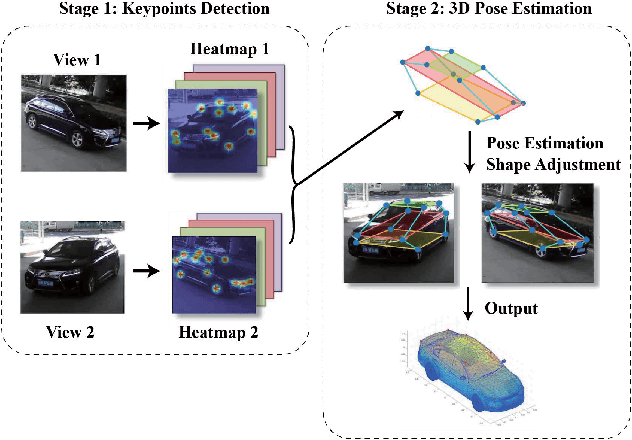
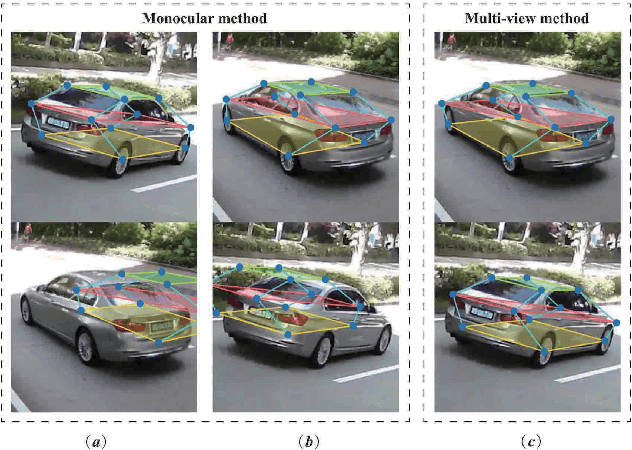
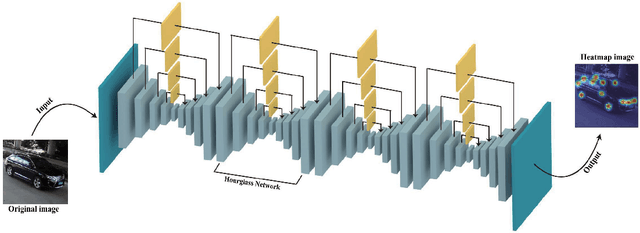
In this paper, we present an accurate approach to estimate vehicles' pose and shape from off-board multiview images. The images are taken by monocular cameras and have small overlaps. We utilize state-of-the-art convolutional neural networks (CNNs) to extract vehicles' semantic keypoints and introduce a Cross Projection Optimization (CPO) method to estimate the 3D pose. During the iterative CPO process, an adaptive shape adjustment method named Hierarchical Wireframe Constraint (HWC) is implemented to estimate the shape. Our approach is evaluated under both simulated and real-world scenes for performance verification. It's shown that our algorithm outperforms other existing monocular and stereo methods for vehicles' pose and shape estimation. This approach provides a new and robust solution for off-board visual vehicle localization and tracking, which can be applied to massive surveillance camera networks for intelligent transportation.