 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Model of RIS-Aided High-Mobility Communication System
Feb 28, 2025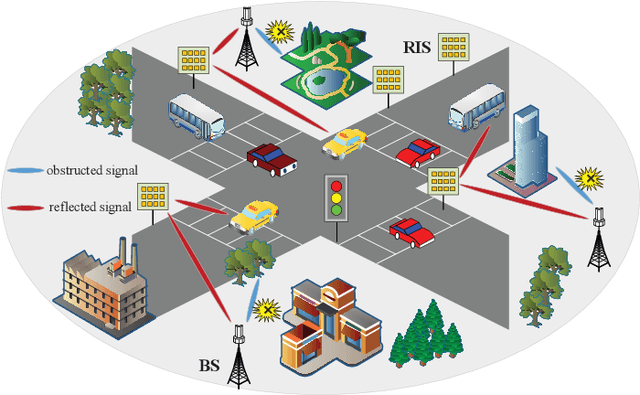



Reconfigurable intelligent surface (RIS)-aided vehicle-to-everything (V2X) communication has emerged as a crucial solution for providing reliable data services to vehicles on the road. However, in delay-sensitive or high-mobility communications, the rapid movement of vehicles can lead to random scattering in the environment and time-selective fading in the channel. In view of this, we investigate in this paper an innovative linear model with low-complexity transmitter signal design and receiver detection methods, which boost stability in fast-fading environments and reduce channel training overhead. Specifically, considering the differences in hardware design and signal processing at the receiving end between uplink and downlink communication systems, distinct solutions are proposed. Accordingly, we first integrate the Rician channel introduced by the RIS with the corresponding signal processing algorithms to model the RIS-aided downlink communication system as a Doppler-robust linear model. Inspired by this property, we design a precoding scheme based on the linear model to reduce the complexity of precoding. Then, by leveraging the linear model and the large-scale antenna array at the base station (BS) side, we improve the linear model for the uplink communication system and derive its asymptotic performance in closed-form. Simulation results demonstrate the performance advantages of the proposed RIS-aided high-mobility communication system compared to other benchmark schemes.
* accepted in IEEE Transactions on Vehicular Technology( Early Access )
Vehicle Pose and Shape Estimation through Multiple Monocular Vision
Nov 11, 2018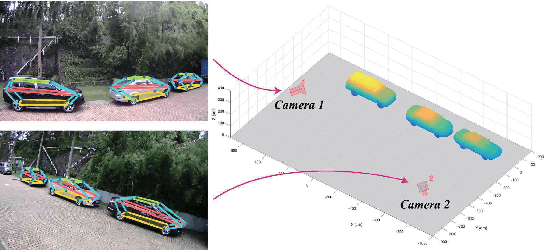
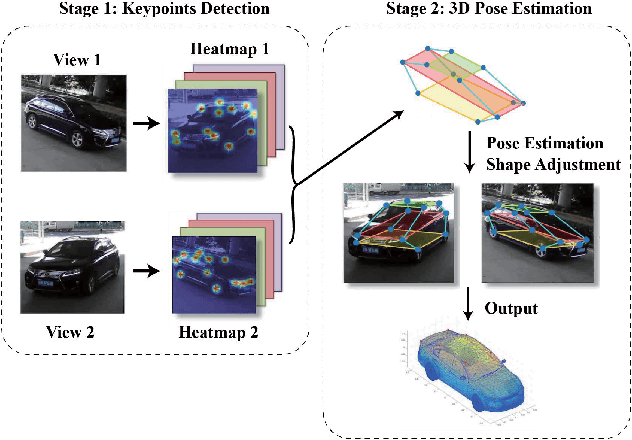
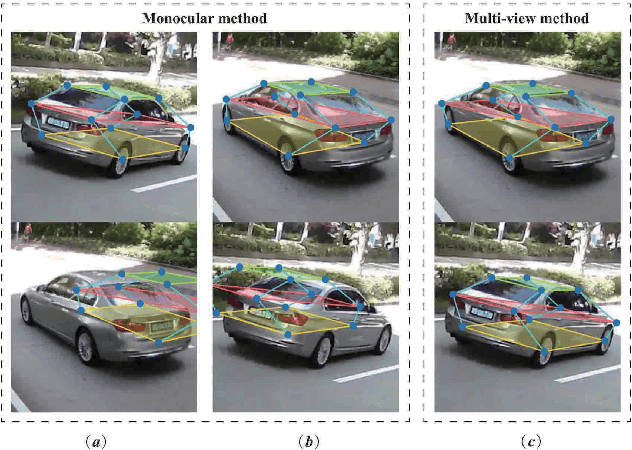
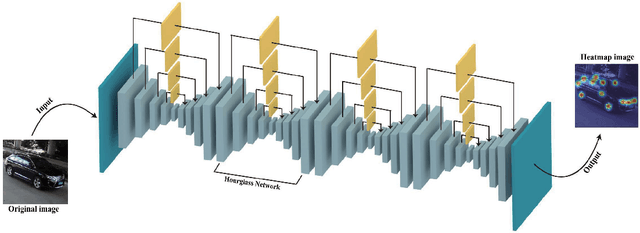
In this paper, we present an accurate approach to estimate vehicles' pose and shape from off-board multiview images. The images are taken by monocular cameras and have small overlaps. We utilize state-of-the-art convolutional neural networks (CNNs) to extract vehicles' semantic keypoints and introduce a Cross Projection Optimization (CPO) method to estimate the 3D pose. During the iterative CPO process, an adaptive shape adjustment method named Hierarchical Wireframe Constraint (HWC) is implemented to estimate the shape. Our approach is evaluated under both simulated and real-world scenes for performance verification. It's shown that our algorithm outperforms other existing monocular and stereo methods for vehicles' pose and shape estimation. This approach provides a new and robust solution for off-board visual vehicle localization and tracking, which can be applied to massive surveillance camera networks for intelligent transportation.
Hierarchical Reinforcement Learning Framework towards Multi-agent Navigation
Jul 17, 2018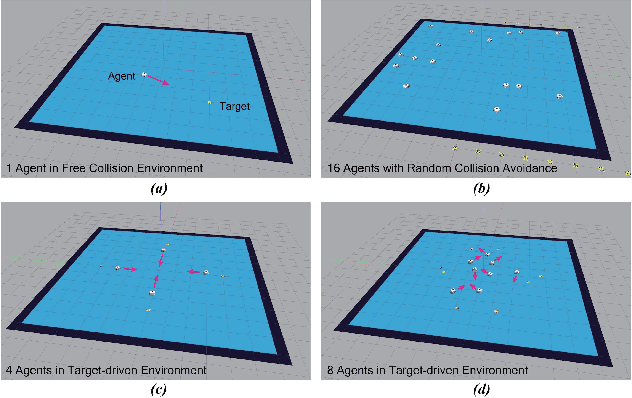
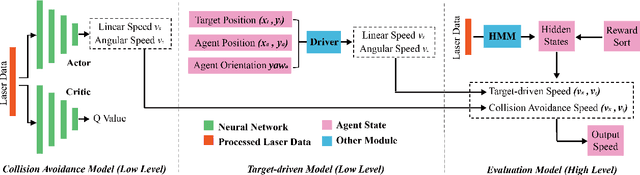
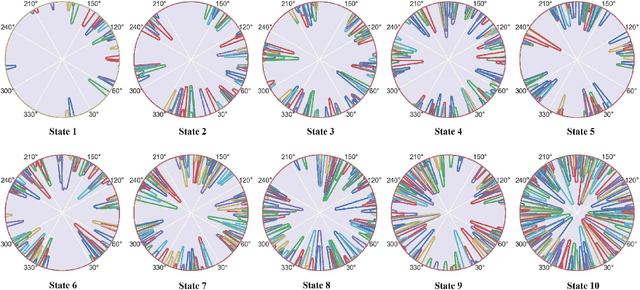
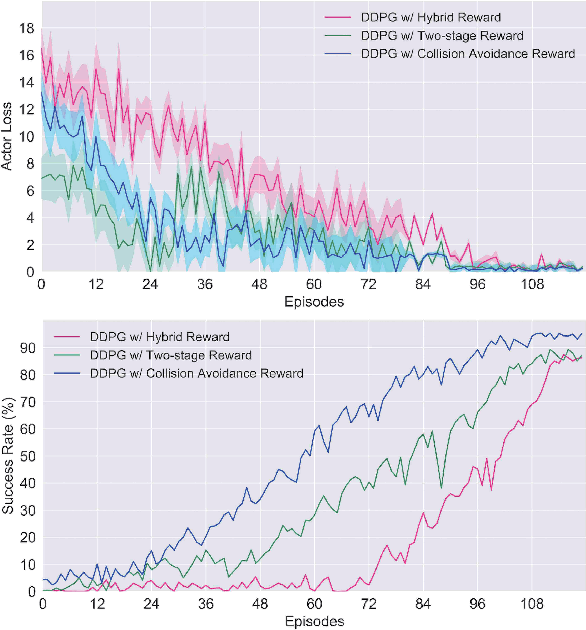
In this paper, we propose a navigation algorithm oriented to multi-agent environment. This algorithm is expressed as a hierarchical framework that contains a Hidden Markov Model (HMM) and a Deep Reinforcement Learning (DRL) structure. For simplification, we term our method Hierarchical Navigation Reinforcement Network (HNRN). In high- level architecture, we train an HMM to evaluate the agent's perception to obtain a score. According to this score, adaptive control action will be chosen. While in low-level architecture, two sub-systems are introduced, one is a differential target- driven system, which aims at heading to the target; the other is a collision avoidance DRL system, which is used for avoiding dynamic obstacles. The advantage of this hierarchical structure is decoupling the target-driven and collision avoidance tasks, leading to a faster and more stable model to be trained. The experiments indicate that our algorithm has higher learning efficiency and rate of success than traditional Velocity Obstacle (VO) algorithms or hybrid DRL method.
Monocular Vision-based Vehicle Localization Aided by Fine-grained Classification
Apr 21, 2018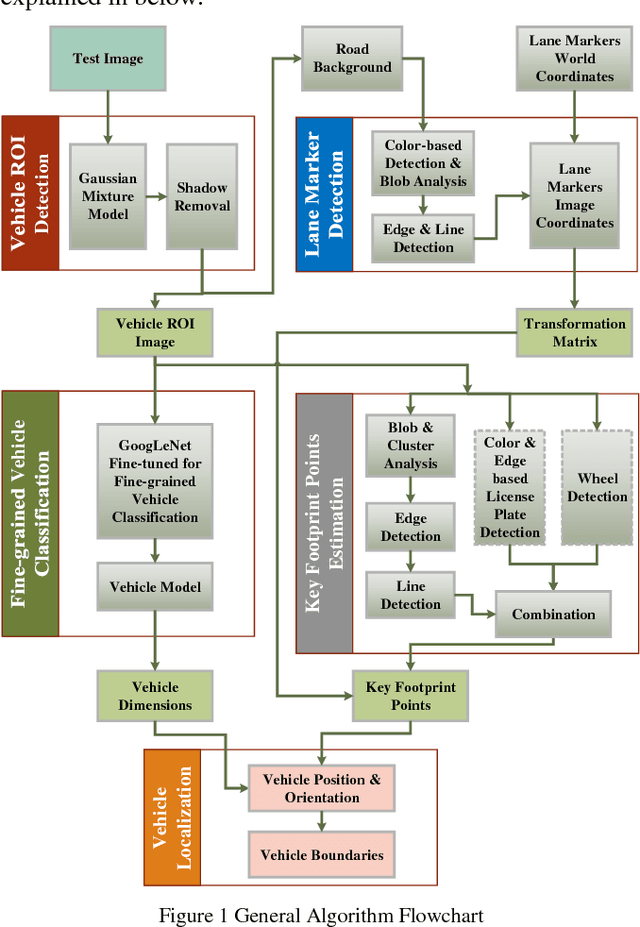
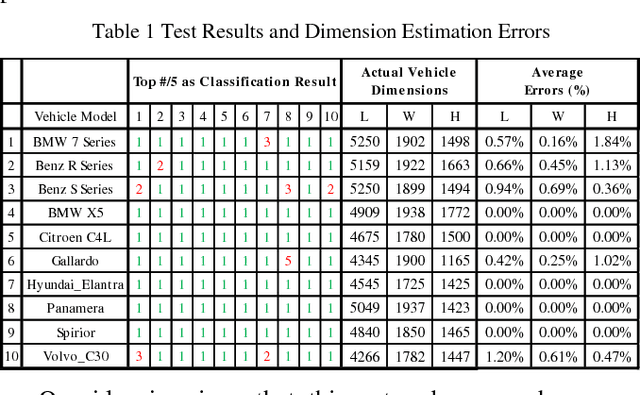
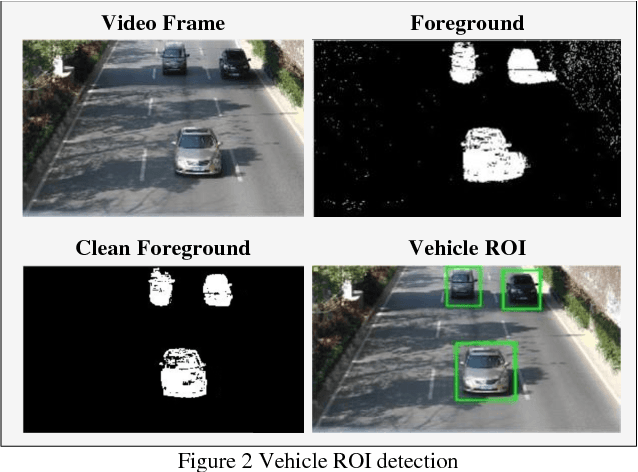
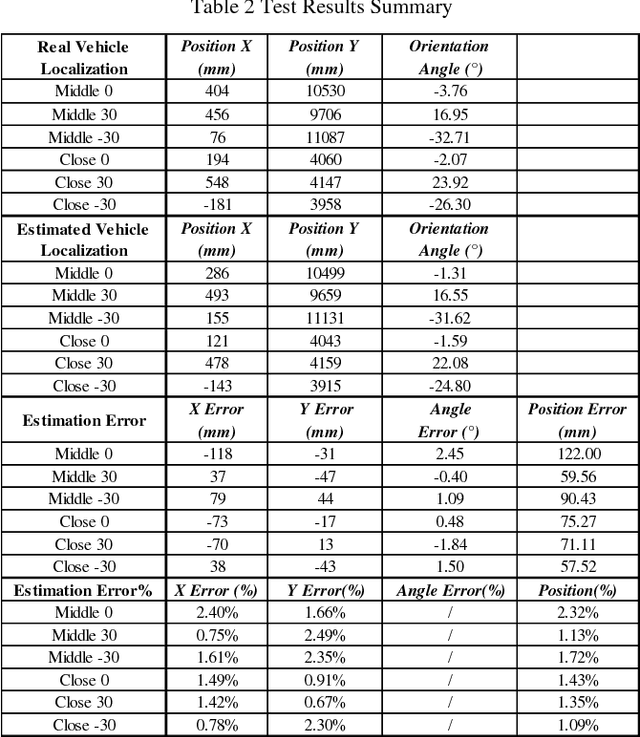
Monocular camera systems are prevailing in intelligent transportation systems, but by far they have rarely been used for dimensional purposes such as to accurately estimate the localization information of a vehicle. In this paper, we show that this capability can be realized. By integrating a series of advanced computer vision techniques including foreground extraction, edge and line detection, etc., and by utilizing deep learning networks for fine-grained vehicle model classification, we developed an algorithm which can estimate vehicles location (position, orientation and boundaries) within the environment down to 3.79 percent position accuracy and 2.5 degrees orientation accuracy. With this enhancement, current massive surveillance camera systems can potentially play the role of e-traffic police and trigger many new intelligent transportation applications, for example, to guide vehicles for parking or even for autonomous driving.