 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulnerabilities in Machine Learning-Based Voice Disorder Detection Systems
Oct 21, 2024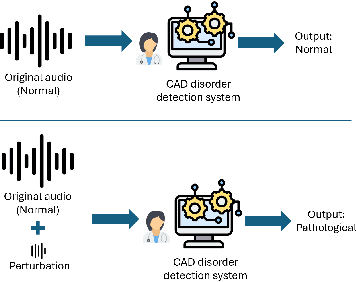
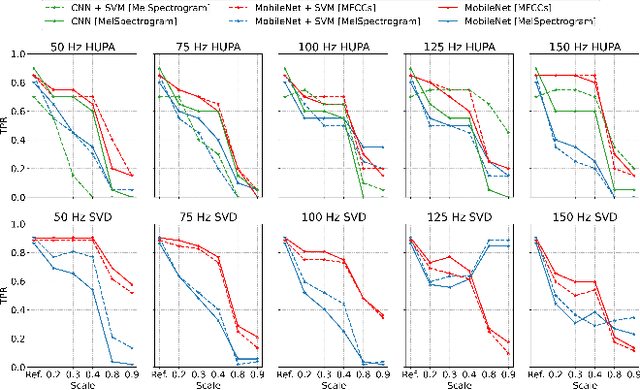
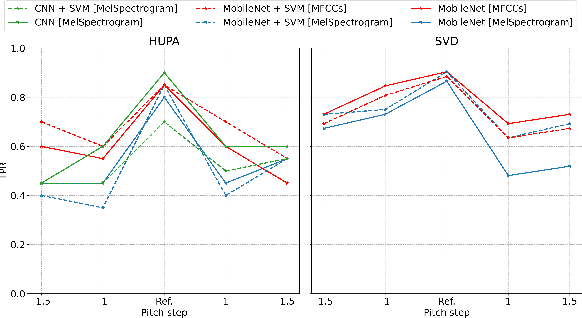
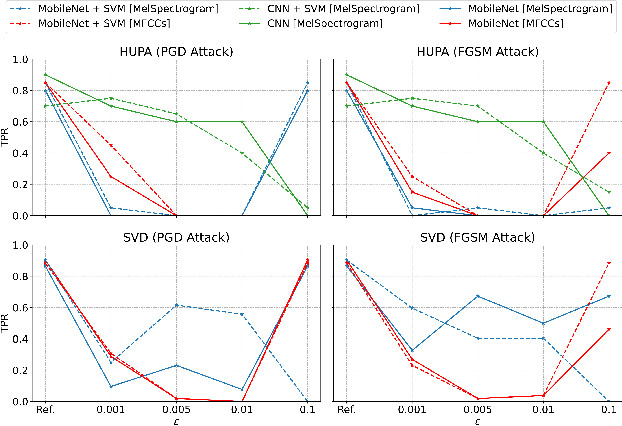
The impact of voice disorders is becoming more widely acknowledged as a public health issue. Several machine learning-based classifiers with the potential to identify disorders have been used in recent studies to differentiate between normal and pathological voices and sounds. In this paper, we focus on analyzing the vulnerabilities of these systems by exploring the possibility of attacks that can reverse classification and compromise their reliability. Given the critical nature of personal health information, understanding which types of attacks are effective is a necessary first step toward improving the security of such systems. Starting from the original audios, we implement various attack methods, including adversarial, evasion, and pitching techniques, and evaluate how state-of-the-art disorder detection models respond to them. Our findings identify the most effective attack strategies, underscoring the need to address these vulnerabilities in machine-learning systems used in the healthcare domain.
SDFR: Synthetic Data for Face Recognition Competition
Apr 09, 2024



Large-scale face recognition datasets are collected by crawling the Internet and without individuals' consent, raising legal, ethical, and privacy concerns. With the recent advances in generative models, recently several works proposed generating synthetic face recognition datasets to mitigate concerns in web-crawled face recognition datasets. This paper presents the summary of the Synthetic Data for Face Recognition (SDFR) Competition held in conjunction with the 18th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2024) and established to investigate the use of synthetic data for training face recognition models. The SDFR competition was split into two tasks, allowing participants to train face recognition systems using new synthetic datasets and/or existing ones. In the first task, the face recognition backbone was fixed and the dataset size was limited, while the second task provided almost complete freedom on the model backbone, the dataset, and the training pipeline. The submitted models were trained on existing and also new synthetic datasets and used clever methods to improve training with synthetic data. The submissions were evaluated and ranked on a diverse set of seven benchmarking datasets. The paper gives an overview of the submitted face recognition models and reports achieved performance compared to baseline models trained on real and synthetic datasets. Furthermore, the evaluation of submissions is extended to bias assessment across different demography groups. Lastly, an outlook on the current state of the research in training face recognition models using synthetic data is presented, and existing problems as well as potential future directions are also discussed.