 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Representation Analysis of Graph Mining
Aug 31, 2016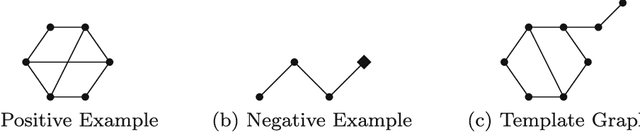
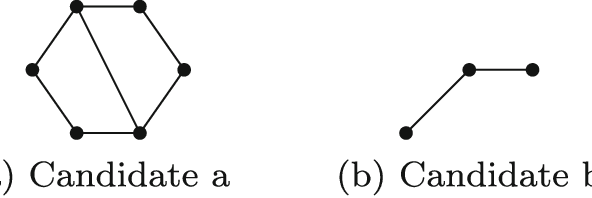
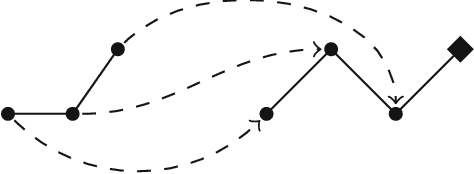

Many problems, especially those with a composite structure, can naturally be expressed in higher order logic. From a KR perspective modeling these problems in an intuitive way is a challenging task. In this paper we study the graph mining problem as an example of a higher order problem. In short, this problem asks us to find a graph that frequently occurs as a subgraph among a set of example graphs. We start from the problem's mathematical definition to solve it in three state-of-the-art specification systems. For IDP and ASP, which have no native support for higher order logic, we propose the use of encoding techniques such as the disjoint union technique and the saturation technique. ProB benefits from the higher order support for sets. We compare the performance of the three approaches to get an idea of the overhead of the higher order support. We propose higher-order language extensions for IDP-like specification languages and discuss what kind of solver support is needed. Native higher order shifts the burden of rewriting specifications using encoding techniques from the user to the solver itself.
Implementing a Relevance Tracker Module
Aug 19, 2016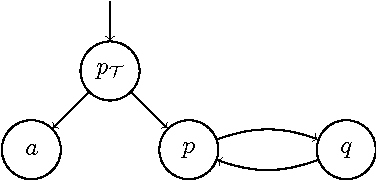

PC(ID) extends propositional logic with inductive definitions: rule sets under the well-founded semantics. Recently, a notion of relevance was introduced for this language. This notion determines the set of undecided literals that can still influence the satisfiability of a PC(ID) formula in a given partial assignment. The idea is that the PC(ID) solver can make decisions only on relevant literals without losing soundness and thus safely ignore irrelevant literals. One important insight that the relevance of a literal is completely determined by the current solver state. During search, the solver state changes have an effect on the relevance of literals. In this paper, we discuss an incremental, lightweight implementation of a relevance tracker module that can be added to and interact with an out-of-the-box SAT(ID) solver.
The KB paradigm and its application to interactive configuration
May 06, 2016

The knowledge base paradigm aims to express domain knowledge in a rich formal language, and to use this domain knowledge as a knowledge base to solve various problems and tasks that arise in the domain by applying multiple forms of inference. As such, the paradigm applies a strict separation of concerns between information and problem solving. In this paper, we analyze the principles and feasibility of the knowledge base paradigm in the context of an important class of applications: interactive configuration problems. In interactive configuration problems, a configuration of interrelated objects under constraints is searched, where the system assists the user in reaching an intended configuration. It is widely recognized in industry that good software solutions for these problems are very difficult to develop. We investigate such problems from the perspective of the KB paradigm. We show that multiple functionalities in this domain can be achieved by applying different forms of logical inferences on a formal specification of the configuration domain. We report on a proof of concept of this approach in a real-life application with a banking company. To appear in Theory and Practice of Logic Programming (TPLP).
A web-based IDE for IDP
Nov 03, 2015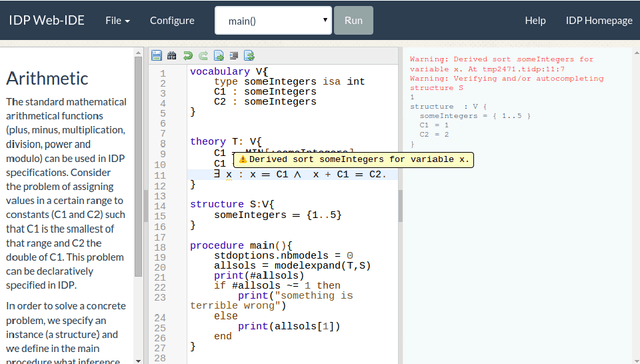
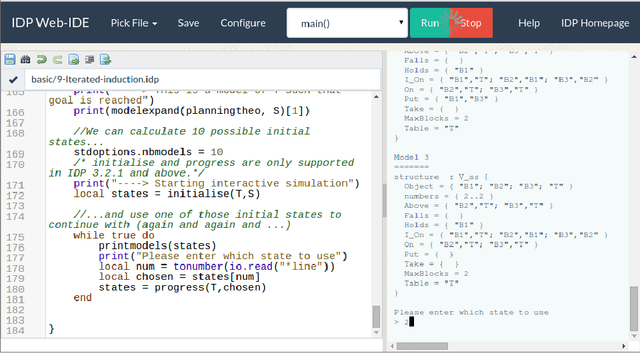
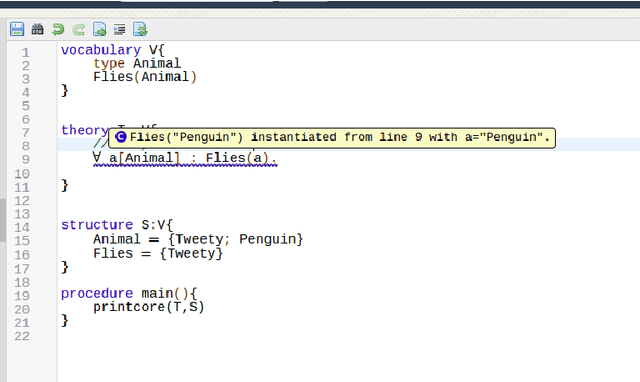
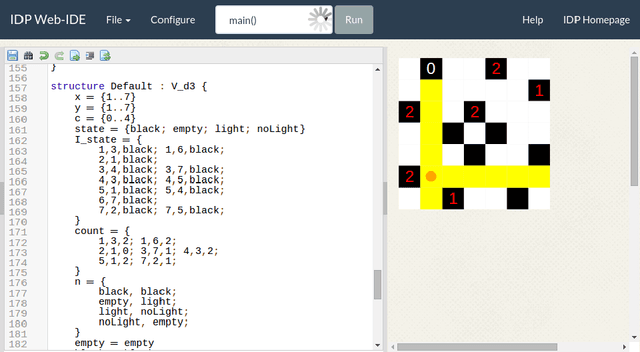
IDP is a knowledge base system based on first order logic. It is finding its way to a larger public but is still facing practical challenges. Adoption of new languages requires a newcomer-friendly way for users to interact with it. Both an online presence to try to convince potential users to download the system and offline availability to develop larger applications are essential. We developed an IDE which can serve both purposes through the use of web technology. It enables us to provide the user with a modern IDE with relatively little effort.
Inference and learning in probabilistic logic programs using weighted Boolean formulas
Apr 25, 2013
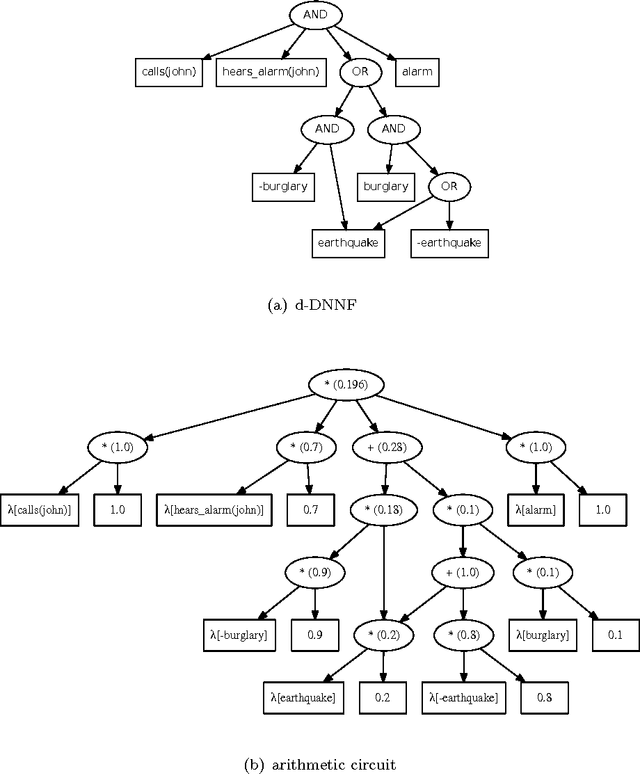
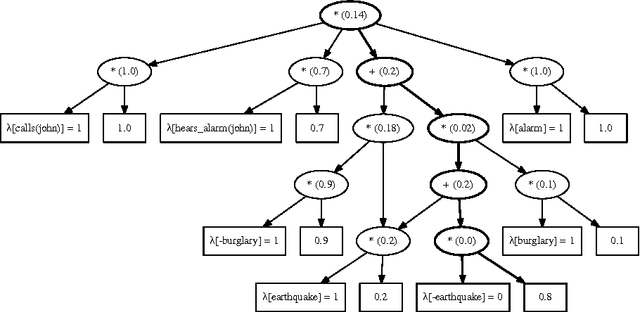
Probabilistic logic programs are logic programs in which some of the facts are annotated with probabilities. This paper investigates how classical inference and learning tasks known from the graphical model community can be tackled for probabilistic logic programs. Several such tasks such as computing the marginals given evidence and learning from (partial) interpretations have not really been addressed for probabilistic logic programs before. The first contribution of this paper is a suite of efficient algorithms for various inference tasks. It is based on a conversion of the program and the queries and evidence to a weighted Boolean formula. This allows us to reduce the inference tasks to well-studied tasks such as weighted model counting, which can be solved using state-of-the-art methods known from the graphical model and knowledge compilation literature. The second contribution is an algorithm for parameter estimation in the learning from interpretations setting. The algorithm employs Expectation Maximization, and is built on top of the developed inference algorithms. The proposed approach is experimentally evaluated. The results show that the inference algorithms improve upon the state-of-the-art in probabilistic logic programming and that it is indeed possible to learn the parameters of a probabilistic logic program from interpretations.
* To appear in Theory and Practice of Logic Programming (TPLP)
A Delta Debugger for ILP Query Execution
Jan 17, 2007
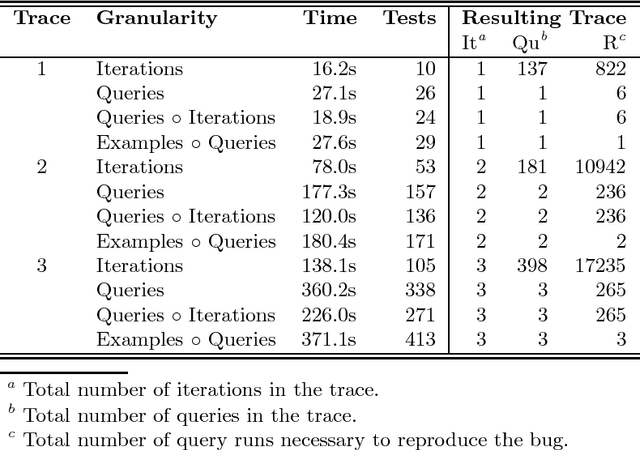

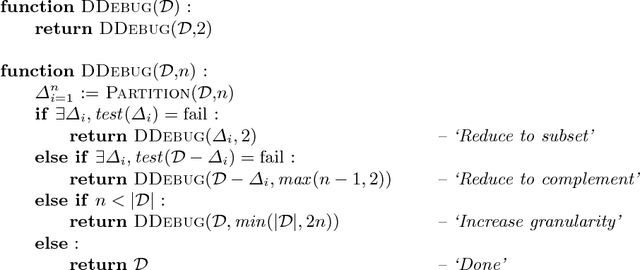
Because query execution is the most crucial part of Inductive Logic Programming (ILP) algorithms, a lot of effort is invested in developing faster execution mechanisms. These execution mechanisms typically have a low-level implementation, making them hard to debug. Moreover, other factors such as the complexity of the problems handled by ILP algorithms and size of the code base of ILP data mining systems make debugging at this level a very difficult job. In this work, we present the trace-based debugging approach currently used in the development of new execution mechanisms in hipP, the engine underlying the ACE Data Mining system. This debugger uses the delta debugging algorithm to automatically reduce the total time needed to expose bugs in ILP execution, thus making manual debugging step much lighter.
Fast Frequent Querying with Lazy Control Flow Compilation
Jan 16, 2006
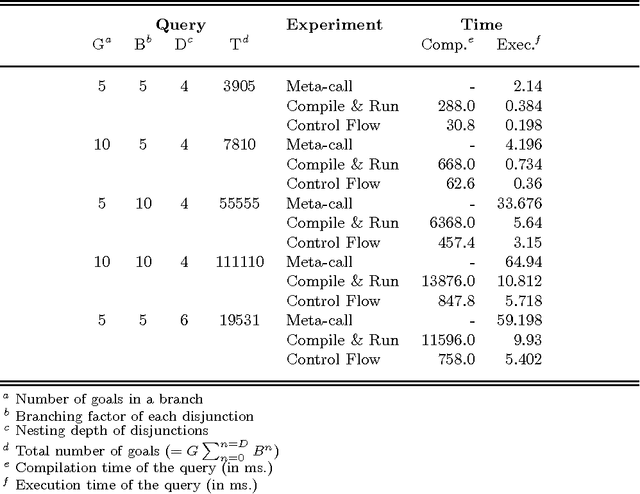

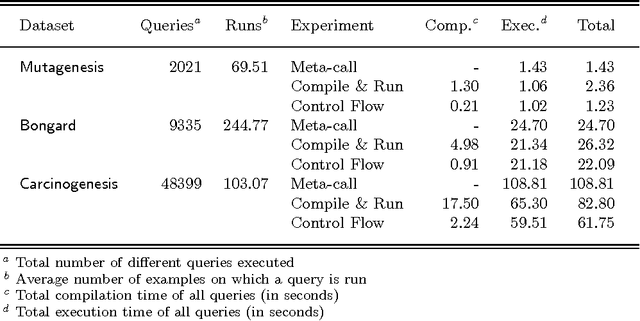
Control flow compilation is a hybrid between classical WAM compilation and meta-call, limited to the compilation of non-recursive clause bodies. This approach is used successfully for the execution of dynamically generated queries in an inductive logic programming setting (ILP). Control flow compilation reduces compilation times up to an order of magnitude, without slowing down execution. A lazy variant of control flow compilation is also presented. By compiling code by need, it removes the overhead of compiling unreached code (a frequent phenomenon in practical ILP settings), and thus reduces the size of the compiled code. Both dynamic compilation approaches have been implemented and were combined with query packs, an efficient ILP execution mechanism. It turns out that locality of data and code is important for performance. The experiments reported in the paper show that lazy control flow compilation is superior in both artificial and real life settings.